

-
偏置偏置偏置
查看全部 -
留痕迹查看全部
-
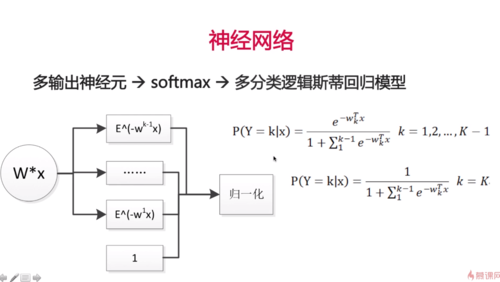
多分类逻辑斯蒂回归模型
 查看全部
查看全部 -
1.虽然神经元模型简单,但是花在数据处理和训练模型上的时间也不少。在多分类时重用这部分代码,只要修改模型即可。
2.修改模型(多个神经元(10个)多分类实现逻辑斯蒂回归):(单层神经网络:10个神经元)
(做修改的地方)
for filename in filenames:
data, labels = load_data(filename)
# 不需要在做filter
all_data.append(data)
all_labels.append(labels)
# [None], y:label,[0,5,6,3,...]
y = tf.placeholder(tf.int64, [None])
# (3072, 10)
w = tf.get_variable('w', [x.get_shape()[-1], 10], # 多分类
initializer=tf.random_normal_initializer(0, 1)) #initializer表示初始化,这里使用正态分布,均值为0,方差为1
# (10, )
b = tf.get_variable('b', [10],
initializer=tf.constant_initializer(0.0)) # b使用常量初始化
# get_variable表示获取变量,如果已经定义好了就使用,如果没有就定义
# [None, 3072] * [3072, 10] = [None, 10]
y_ = tf.matmul(x, w) + b
# mean square loss
'''
# 因为是多分类,使用softmax
# course:1+e^x
# api:e^x/sum(e^x)
# 归一化
# p_y:每个样本都是一个分布,10个值加起来等于1,[[0.01,0.9,...0.03], []...]
p_y = tf.nn.softmax(y_)
# 多分类的loss,可以使用one-hot编码把y也变成一个分布
# 5 -> [0,0,0,0,0,1,0,0,0,0]
y_one_hot = tf.one_hot(y, 10, dtype=tf.float32)
loss = tf.reduce_mean(tf.square(y_one_hot - p_y)) # 类型不一致需要变换
'''
loss = tf.losses.sparse_softmax_cross_entropy(labels=y, logits=y_)
# y_ -> softmax
# y -> one_hot
# loss = ylogy_
# 得到的是index,是一个int值
predict = tf.argmax(y_, 1)
# [1, 0, 1, 1, 0, 1,...]
correct_prediction = tf.equal(predict, y) # bool
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float64))
3.API不会的时候要学会查文档。
4.jupyter notebook的一些用法:
 查看全部
查看全部 -
1.# 执行计算图,首先要初始化变量
init = tf.global_variables_initializer()
batch_size = 20
train_steps = 100000 # 因为是一个神经元,所以还是挺快的
test_steps = 100 # 20 * 200 = 2000 张图片
# 对于tensorflow来说,在构建好计算图后,需要开启一个会话session
# 打开会话之后,就可以执行计算图了
with tf.Session() as sess:
sess.run(init)
for i in range(train_steps):
batch_data, batch_labels = train_data.next_batch(batch_size)
# 在会话中执行计算图使用sess.run()方法,如果加了train_op,就说明在这次run中我们就去训练了,如果没有,就是在测试模式下
# feed_dict:要喂入的数据,因为前面x和y都是placeholder,所以需要输入数据,x和y应该输入的是CIFAR-10的数据,分别是图片数据和label数据
# 需要在CIFAR-10数据集上循环遍历整个数据,使得feed_dict拿到的是不同的数据
# 为了达到这种处理模式,我们需要对CIFAR-10的数据集做一些处理
loss_val, acc_val, _ = sess.run(
[loss, accuracy, train_op],
feed_dict={x: batch_data, y: batch_labels})
# 打印log
if (i+1) % 500 == 0:
print('[Train] Step: %d, loss: %4.5f, acc: %4.5f' % (i+1, loss_val, acc_val))
if (i+1) % 5000 == 0:
# 因为test不用shuffle,所以遍历完之后抛出异常,所以需要在遍历完一次之后重新创建CifarData类
test_data = CifarData(test_filenames, False)
all_test_acc_val = [] # 需要做一个总的test上的结果,所以需要把这些结果加起来做平均
for j in range(test_steps):
test_batch_data, test_batch_labels = test_data.next_batch(batch_size)
test_acc_val = sess.run([accuracy], feed_dict={x: test_batch_data, y: test_batch_labels})
all_test_acc_val.append(test_acc_val)
test_acc = np.mean(all_test_acc_val)
print('[Test] Step: %d, acc: %4.5f' % (i+1, test_acc))
# 两次测试准确率是一样的,说明没有学习到什么东西,我们需要做一下改进——》CifarData
2.# 为什么不做归一化准确率在大约0.5呢?因为它的数值比较大,而且它的数值都在0-1之间,所以导致它的预测会偏向一方或另一方,类似于sigmoid
self._data = self._data / 127.5 - 1 # 一般来说,我们会把图像缩放到-1到1之间,所以进行缩放:归一化
查看全部 -
1.如何执行计算图:
# 执行计算图,首先要初始化变量
init = tf.global_variable_initializer()
# 对于tensorflow来说,在构建好计算图后,需要开启一个会话session
# 打开会话之后,就可以执行计算图了
with tf.Session() as sess:
# 在会话中执行计算图使用sess.run()方法,如果加了train_op,就说明在这次run中我们就去训练了,如果没有,就是在测试模式下
# feed_dict:要喂入的数据,因为前面x和y都是placeholder,所以需要输入数据,x和y应该输入的是CIFAR-10的数据,分别是图片数据和label数据
# 需要在CIFAR-10数据集上循环遍历整个数据,使得feed_dict拿到的是不同的数据
# 为了达到这种处理模式,我们需要对CIFAR-10的数据集做一些处理
sess.run([loss, accuracy, train_op], feed_dict={x: })
# CIFAR-10数据处理的方法
class CifarData:
# 初始化:filenames,文件名说明对于训练数据集和测试数据集是分开的
# need_shuffle:对于训练集来说,在训练的时候,过完一遍数据之后,需要shuffle一下数据,就是使得数据更加散乱,散乱代表数据之间没有依赖关系,使得泛化能力更强,这是机器学习中一个常用的概念
# 对于测试集来说,因为不需要训练,所以不需要shuffle
def __init__(self, filenames, need_shuffle):
# 把数据读进来
all_data = []
all_labels = []
for filename in filenames:
data, labels = load_data(filename)
# 因为我们要做的是一个二分类的问题,所以我们只用CIFAR-10的0和1两个分类,在这里需要做一个filter
# 因为data和labels的数目是一样的,所以我们把它们打包到一起
for item, label in zip(data, labels):
# 如果类别是0,1的话,就把数据和label放进来
if label in [0, 1]:
all_data.append(item)
all_labels.append(label)
# 把最后的值合并并且转化为numpy的矩阵
self._data = np.vstack(all_data) # 从纵向上把数据合并到一起,因为all_data定义是一个一个向量
self._labels = np.hstack(all_labels) # 从横向上合并到一起,因为label实际上是一个一维向量
# 测试
print(self._data.shape)
print(self._labels.shape)
self._num_examples = self._data.shape[0] # 数量
self._need_shuffle = need_shuffle # shuffle开关
self._indicator = 0 # 表示训练集已经遍历到哪个位置了
if self._need_shuffle:
self._shuffle_data()
# 因为all_data和all_labels都是numpy的数据结构,所以我们可以用numpy的方法来做
def _shuffle_data(self):
# np.random.permutation这个函数会做一个混排,从0到_num_examples,如[0, 1, 2, 3, 4, 5] -> [5, 3, 2, 4, 0, 1]
p = np.random.permutation(self._num_examples)
# p只是得到一个排列,需要把数据放进来
# _data和_labels应该做一样的shuffle,否则会错乱
self._data = self._data[p]
self._labels = self._labels[p]
def next_batch(self, batch_size):
'''return batch_size examples as a batch.'''
end_indicator = self._indicator + batch_size # 对应于_indicator,这个表示结束位置
if end_indicator > self._num_examples:
if self._need_shuffle:
self._shuffle_data()
self._indicator = 0
end_indicator = batch_size
else:
raise Exception('have no more examples')
# 当end_indicator=batch_size时,如果还比_num_examples大,就需要抛出异常了
if end_indicator > self._num_examples:
raise Exception('batch size is larger than all examples')
batch_data = self._data[self._indicator: end_indicator] # 需要把这个范围内的数据放到结果中
batch_labels = self._labels[self._indicator: end_indicator]
self._indicator = end_indicator
return batch_data, batch_labels
train_filenames = [os.path.join(CIFAR_DIR, 'data_batch_%d' % i) for i in range(1,6)]
test_filenames = [os.path.join(CIFAR_DIR, 'test_batch')]
train_data = CifarData(train_filenames, True)
查看全部 -
1.# 为了使函数具有更好的泛化能力,定义一个load_data
# 用于从pickle文件将数据读取进来
def load_data(filename):
'''read data from data file.'''
with open(filename, 'rb') as f:
data = cPickle.load(f, encoding='bytes')
return data[b'data'], data[b'labels']
# 先搭建tensorflow计算图,再执行
x = tf.placeholder(tf.float32, [None, 3072]) # None表示可变性
# [None]
y = tf.placeholder(tf.int64, [None])
# (3072, 1)
w = tf.get_variable('w', [x.get_shape()[-1], 1], # 因为是二分类,所以只有一个输出结果,定义为1
initializer=tf.random_normal_initializer(0, 1)) #initializer表示初始化,这里使用正态分布,均值为0,方差为1
# (1, )
b = tf.get_variable('b', [1],
initializer=tf.constant_initializer(0.0)) # b使用常量初始化
# get_variable表示获取变量,如果已经定义好了就使用,如果没有就定义
# [None, 3072] * [3072, 1] = [None, 1]
y_ = tf.matmul(x, w) + b
# [None, 1]
p_y_1 = tf.nn.sigmoid(y_) # 概率值
# 因为y维度不一样,所以需要进行一下reshape
# [None, 1]
y_reshaped = tf.reshape(y, (-1, 1))
y_reshaped_float = tf.cast(y_reshaped, tf.float32)
# 用平方差作为损失函数
loss = tf.reduce_mean(tf.square(y_reshaped_float - p_y_1)) # 类型不一致需要变换
predict = p_y_1 > 0.5 # true:1 false:0
# [1, 0, 1, 1, 0, 1,...]
correct_prediction = tf.equal(tf.cast(predict, tf.int64), y_reshaped) # bool
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float64))
# 定义梯度下降的方法
with tf.name_scope('train_op'):
train_op = tf.train.AdamOptimizer(1e-3).minimize(loss) # 最小化loss,到这里,计算图构建完成
查看全部 -
1. 神经元的Tensorflow实现:
使用的数据集是:CIFAR-10
The CIFAR-10 dataset consists of 60000 32x32 colour images in 10 classes, with 6000 images per class. There are 50000 training images and 10000 test images.
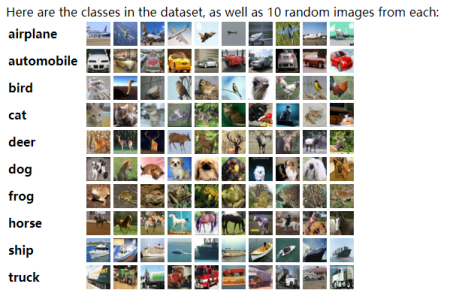
CIFAR-10文件里是python版本的文件,所以它们是pickle的数据格式。如果想要检查里面的文件格式是什么,需要导入cPickle,因为里面的数据使用numpy存的,所以需要导入numpy。
2.jupyter notebook可以使用tab键补全变量名。
3.加载数据集:
import _pickle as cPickleimport numpy as np
import os
CIFAR_DIR = './cifar-10-batches-py'
print(os.listdir(CIFAR_DIR))
with open(os.path.join(CIFAR_DIR, 'data_batch_1'), 'rb') as f:
data = cPickle.load(f, encoding='bytes')
print(type(data))
print(data.keys())
print(type(data[b'data']))
print(type(data[b'labels']))
print(type(data[b'batch_label']))
print(type(data[b'filenames']))
print(data[b'data'].shape)
print(data[b'data'][0:2])
print(data[b'labels'][0:2])
print(data[b'batch_label'])
print(data[b'filenames'][0:2])
# 32 * 32 = 1024 * 3 = 3072
# RR-GG-BB = 3072
image_arr = data[b'data'][100]
image_arr = image_arr.reshape((3, 32, 32)) # 32 32 3 三通道不一致,所以需要再做一下变换,如果解析的时候顺序不对,那么报错
image_arr = image_arr.transpose((1, 2, 0)) # 把1,2位置上的往前放,把0位置上的放在最后,如果通道顺序不对,那么图片的方向会发生变化
import matplotlib.pyplot as plt # 显示图像的库
from matplotlib.pyplot import imshow
%matplotlib inline # 这样可以直接显示在notebook上,而不是再打开一个另外的框
imshow(image_arr) # 显示图片
查看全部 -
1. 如何调整神经网络使得目标函数最小呢?在这里,我们不能像解方程一样神经网络参数解出来,找到最优参数,为什么呢?第一个因为现在的参数数目众多,求解起来会非常的耗时;第二点是因为约束条件是数据,就是说我们要在数据集上调整参数使得目标函数最小,但是对于很多的机器学习应用来说,它的数据是变化的,比如说很多应用都采集不同的数据,每天都有增加,今天数据集上的最优参数可能到明天就不是最优了,所以导致我们不能用直接求解的方式。那么如何求呢?
下山算法:找到方向,走一步。
神经网络中有类似的算法,叫做梯度下降算法。
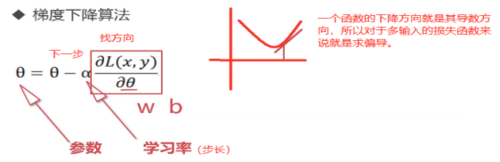
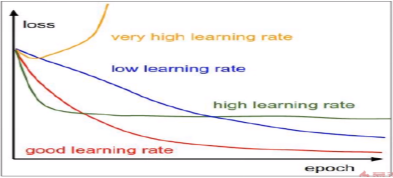
在这个过程中,影响最大的参数是α,这是一个预先设定好的值,当然可以在训练过程中不断去调整,但这不是学习出来的,而是人为设置的。它的大小完完全全影响着整个网络的学习程度:
2 Tensorflow介绍:
Google Brain的第二代机器学习框架
开源社区活跃
可扩展性好,在分布式下支持的特别好,可以很轻松地用tensorflow扩展到多台机器上,一机一卡扩展到一机多卡或者多机多卡这样的情况
API健全,对用户友好
3. 计算图模型:
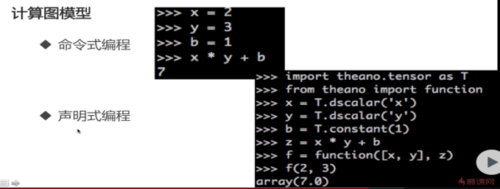
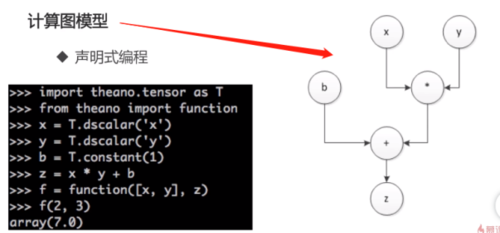
为什么要讲计算图模型呢?因为它和求解神经网络是有关系的的。神经网络的结构是定义好的,但是它的输入x是用户自己产生的,所以我们在定义神经网络的时候并不知道数据是什么,我们要在定义好神经网络之后才可以把数据输入进来,才可以求解,去调整神经网络参数,使神经网络可以符合这个数据,所以这是tensorflow使用计算图模型的一个基础。
 查看全部
查看全部 -
1. 多分类逻辑斯底回归模型:——多个神经元

一个神经元需要一个W,两个神经元需要两个W,所以由向量扩展成矩阵。
2. 多分类问题比二分类问题具有更广泛的适用性。
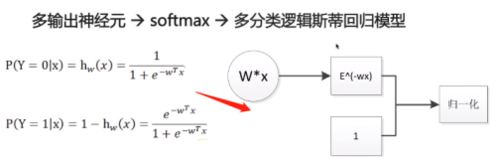
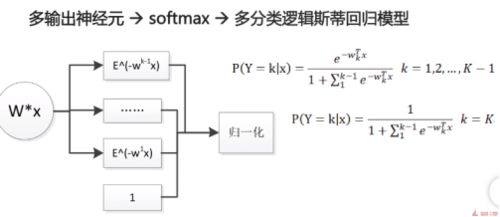
3. 多分类和二分类的逻辑斯蒂回归模型也可以被认为是神经网络。
4. 如何调整神经网络可以使神经网络学到数据中的规律?
目标函数:衡量对数据的拟合程度,在机器学习领域中通常也被称为损失函数。举例:


(1)平方差损失

(2)交叉熵损失

神经网络训练:调整参数使模型在训练集上的损失函数最小。
查看全部 -
1. 逻辑斯底回归模型在深度学习出现之前是最赚钱的一个算法。为什么最赚钱呢?因为百度、谷歌的主要现金业务广告点击率预估在深度学习出现之前就用的这个模型,所以说是最赚钱的。
2. 神经元——最小的神经网络
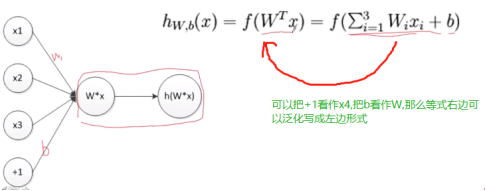
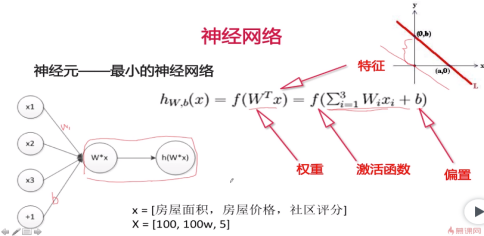
如上图所示,W和b定义的是一个分类线或分类面,看下图:
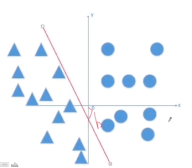
3.二分类逻辑斯底回归模型:
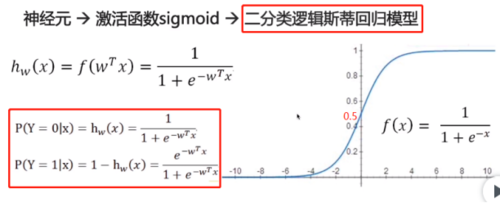 查看全部
查看全部 -
1. 机器学习是什么——无序数据转化为价值的方法
机器学习价值——从数据中抽取规律,并用来预测未来
2. 机器学习应用举例:
分类问题——图像识别、垃圾邮件识别
回归问题——股价预测、房价预测
(分类问题给出的是一个label,而回归问题给出的是一个实数)
排序问题——点击率预估、推荐
生成问题——图像生成、图像风格转换、图像文字描述生成
3. 机器学习应用流程:
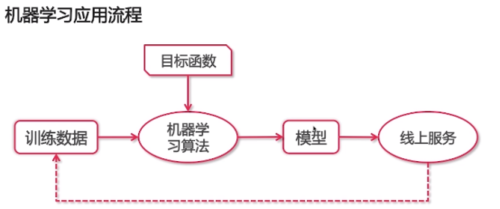
4. .机器学习岗位职责:
数据处理(采集+去噪)
模型训练(特征+模型)
模型评估与优化(MSE、F1-Score、AUC+调参)
模型应用(A/B测试)
5.
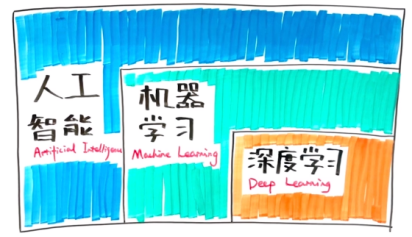
6.深度学习与机器学习:
机器学习是实现人工智能的方法。
深度学习是实现机器学习算法的技术。深度学习的算法实际上可以用机器学习其他算法实现,但是深度学习可以结合大数据使算法达到更好的效果,这是其他算法不能达到的。
7. 深度学习算法集合:
卷积神经网络:图像生成、图像分类等
循环神经网络:用来处理不定长数据的。不定长数据指的是输入的长度是不一样的。比如说它可以是文本数据,比如说一个文本分类问题。
(循环神经网络在NLP领域使用的比较广泛,卷积神经网络在CV领域使用的比较广泛)
自动编码器
稀疏编码
深度信念网络、限制波尔兹曼机
深度学习+强化学习=深度强化学习(交叉领域):alpha-go等
8. 深度学习进展:
图像分类:IMAGENET比赛
机器翻译:循环神经网络加了attention
图像生成:转换,上色可以帮助二次元漫画家上色、字体、图像特性化
AlphaGo:CNN
查看全部 -
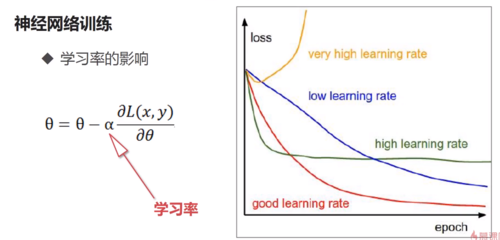
梯度下降法
学习率相当于步长
查看全部 -
单个神经元->sigmod(激活函数)->二分类逻辑斯蒂回归模型
多输出神经元->softmax->多分类逻辑斯蒂回归模型
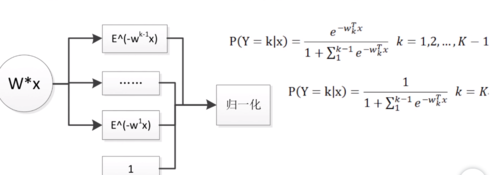
目标函数:衡量对数据的拟合程度(损失)

神经网络训练目的:调整参数,使模型在训练集上的损失函数最小
查看全部 -
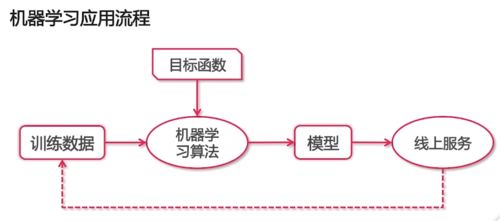
机器学习是什么:无序数据转化为价值的方法
机器学习价值:从数据中抽取规律,并用来预测未来
深度学习是机器学习的一个子方向
机器学习是实现人工智能的方法
深度学习是实现机器学习算法的技术
深度学习算法集合:
卷积神经网络(CNN)
循环神经网络(处理不定长数据)
自动编码器、稀疏编码、深度信念网络、限制玻尔兹曼机
查看全部





举报