

-
#键值对存储key不能重复,value可以重复
# coding=utf-8
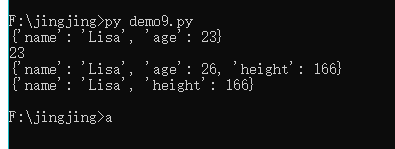
lisa = {"name":"Lisa","age":23}
print(lisa)
print(lisa["age"])
lisa["age"] = 26
lisa["height"] = 166
print(lisa)
lisa.pop("age")
print(lisa)
 查看全部
查看全部 -
左闭右开[0:2]取第一个和第二个
反向索引最后一个下标是-1
# coding=utf-8
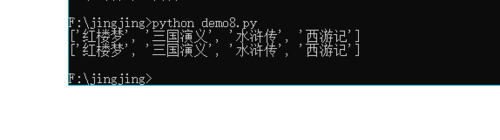
books = ["红楼梦","三国演义","水浒传","西游记","聊斋志异"]
print(books[0:4])
print(books[0:-1])
 查看全部
查看全部 -
# coding=utf-8
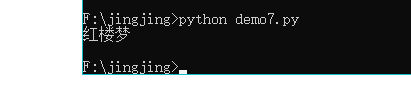
books = ["红楼梦","三国演义","水浒传","西游记","聊斋志异"]
print(books[0])
 查看全部
查看全部 -
int取整
%取余
# coding=utf-8
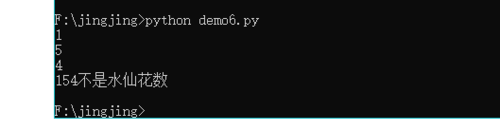
n=154
a=int(n/100)
b=int(n%100/10)
c=n%10
print(a)
print(b)
print(c)
re=a*a*a+b*b*b+c*c*c
if n==re:
print(n,end="")
print("是水仙花数")
else:
print(n,end="")
print("不是水仙花数")
154除以100取余54,54除以10等于5.4取整为5
 查看全部
查看全部 -
# coding=utf-8
score = 30
if score >=60:
print("考试通过!")
if score >= 90:
print("名列前茅,重点表扬")
else:
print("继续努力,潜力巨大")
else:
print("考试未通过,还需努力")
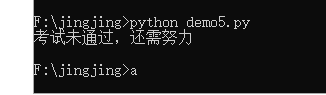
注意缩进
查看全部 -
整型(整数)不需要加双引号,加了双引号就是字符串
查看全部 -
双引号一定标识字符串
查看全部 -
# coding=utf-8
la = "德语"
if la == "德语" :
print("Ich liebe dich")
elif la == "韩语" :
print("사랑해")
elif la == "英语" :
print("I love you")
else :
print("我爱你")
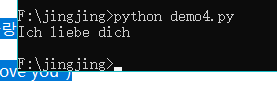
由于是用记事本打开编辑的所以对编码有要求最终保存为utf-8 文件开头对应utf-8 猜测是这个原因,也许我用个正经编辑器就不会这样
查看全部 -
注意 () not and or的优先级
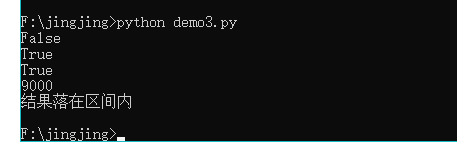
# coding=gbk
r1 = 1 != 1 or 8 < 2 and 6 > 3
print(r1)
r2 = 1 != 1 or not 8 < 1 and 6 > 3
print(r2)
r3 = 1 != 1 or not (8 < 1 and 6 > 3)
print(r3)
x = 700
re = (1000 - x) * 30
print(re)
if(re >= 1 and re <= 10000) :
print("结果落在区间内")
else :
print("结果未落在区间内")
 查看全部
查看全部 -
# coding=gbk
x=1600
re = (1000-x)*30
print(re)
if re >10000 :
print("结果大于10000")
else :
print("结果小于10000")
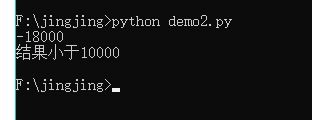
True False 首字母是大写的
查看全部 -
# coding=gbk
if 8 > 6 :
print("判断条件成立")
else :
print("判断条件不成立")
 查看全部
查看全部 -
yntaxError: Non-ASCII character '\xe5' in file index.py on line 7, but no encoding declared; see http://python.org/dev/p
开头加# -*- coding: UTF-8 -*-
不好使就加#coding=gbk 总有一款适合你
 查看全部
查看全部 -
+在python中不仅代表着加法运算符,也有字符串连接的功能,可将前后字符串连接显示
查看全部 -
/n,代表在此符号前后的内容显示时换行的意思。
查看全部 -
在print引号内容后加入,end='',就是指引号内容与下一段内容不换行。
查看全部



举报