

-
import pymongo # 指定客户端连接mongodb pymongo_client = pymongo.MongoClient("mongodb://localhost:27017") # 指定数据库名称 pymongo_db = pymongo_client["imooc"] # 创建集合,创建表 pymongo_collection = pymongo_db["pymongo_test"] data = { "name": "imooc", "flag": 1, "url": "https://www.imooc.com" } mylist = [ {"name": "imooc", "flag": "123", "url": "https://www.imooc.com"}, {"name": "taobao", "flag": "456", "url": "https://www.imooc.com"}, {"name": "qq", "flag": "761", "url": "https://www.imooc.com"}, {"name": "知乎", "flag": "354", "url": "https://www.imooc.com"}, {"name": "微博", "flag": "954", "url": "https://www.imooc.com"} ] # pymongo_collection.insert_one(data) # pymongo_collection.insert_many(mylist) # result=pymongo_collection.find({},{"_id":0,"name":1,"url":1,"flag":1}) # result=pymongo_collection.find({},{"_id":0,"name":1,"url":1,"flag":1}) # result=pymongo_collection.find_one() # print(result) # for item in result: # print(item) # 大于一百 # find_result=pymongo_collection.find({"flag":{"$gt":100}}) # 首字母t # find_result=pymongo_collection.find({"name":{"$regex":"^t"}}) # for item in find_result: # print(item) # pymongo_collection.update_one({"name":{"$regex":"^t"}},{"$set":{"name":"baidu"}}) # pymongo_collection.delete_one({"name":"微博"}) pymongo_collection.delete_many({})查看全部 -
import requests from lxml import etree from pymongo.collection import Collection import pymongo print("开始0") class Dangdang(object): mongo_client=pymongo.MongoClient(host="localhost",port=27017) dangdang_db=mongo_client["dangdang_db"] def __init__(self): self.header = { "Host": "bang.dangdang.com", "Connection": "keep-alive", "Cache-Control": "max-age=0", "Upgrade-Insecure-Requests": "1", "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36", "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9", "Referer": "http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-2", "Accept-Encoding": "gzip,deflate", "Accept-Language": "zh-CN,zh;q=0.9" } self.dangdang=Collection(Dangdang.dangdang_db,"dangdang") def get_dangdang(self, page): """发送请求到当当网获取数据""" url = "http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-%s" % page response = requests.get(url=url, headers=self.header) if response: # html数据实例化 # print(response.text) html1 = etree.HTML(response.content) items = html1.xpath("//ul[@class='bang_list clearfix bang_list_mode']/li") return items def join_list(self,item): # 处理列表→字符串 return "".join(item) def parse_item(self,items): # 解析条目 # 存到mongodb之前的数据 result_list=[] for item in items: # 名称 title=item.xpath(".//div[@class='name']/a/@title") # 图书评论 comment=item.xpath(".//div[@class='star']/a/text()") # 作者信息 author=item.xpath(".//div[@class='publisher_info'][1]/a[1]/@title") # 价格 price=item.xpath(".//div[@class='price']/p[1]/span[1]/text()") result_list.append( { "title":self.join_list(title), "comment":self.join_list(comment), "author":self.join_list(author), "price":self.join_list(price) } ) return result_list def insert_data(self,result_list): self.dangdang.insert_many(result_list) def main(): d = Dangdang() print("开始") import json for page in range(1, 26): items = d.get_dangdang(page=page) result=d.parse_item(items=items) # print(json.dumps(result)) print(result) # d.insert_data(result) if __name__ == '__main__': main()查看全部 -
 注意单引号双引号的问题
注意单引号双引号的问题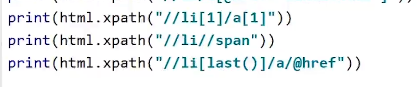 孙子标签用//
孙子标签用//获取最后一个li标签的a标签的href的值
查看全部 -
xpath
//div[@class="result c-container new-pmd"]
//dd[@class="lemmaWgt-lemmaTitle-title J-lemma-title"]/a[3]/text()
//div[not(contains(@class,"para"))]
//div[last()-2]
查看全部 -
遇到网络问题: ConnectionError异常
如果HTTP请求返回了不成功的状态码: HTTPError异常
若请求超时,则抛出一个Timeout异常
若请求超过了设定的最大重定向次数,则会抛出一个 TooManyRedirects异常
查看全部 -
查看全部
-
cookie
查看全部 -
# 随便练习 print(1)
查看全部




举报
0/150
提交
取消