

-
int前加const常量不可变
查看全部 -
int main(int argc,char **argv)
查看全部 -
stu.math = 95;
stu.english = 93;
struct Student
{
int math;
int english;
}
int main(int argc,char **argv)
{
struct Student stu[50];
//为其中一个学生的成绩赋值
stu[20].math = 90;
stu[20].english = 95;结构体变量名.变量之一=
查看全部 -
如果不想指明数组的长度,可以不写,这样数组的长度就是给定的列表的长度。
include <stdio.h>
int main(int argc,char **argv)
{
int a[4] = {0, 1, 2, 3};
return 0;
}
#include <stdio.h>
int main(int argc,char **argv)
{
int a[] = {0, 1, 2, 3}; // 此处数组的长度就是 4
return 0;也可以只给部分元素赋值,当 {} 中的元素数量少于 [] 中定义的长度的时候,只给前面部分元素赋值,后面的未指定的元素,将被赋值为 0。
#include <stdio.h>
include <stdio.h>
int main(int argc,char **argv)
{
int a[4] = {0};
return 0;
}查看全部 -
在定义了一个结构体之后,我们就可以使用这个结构体了,结构体的使用和变量非常类似:
struct Student
{
int math;
int english;
};
int main(int argc,char **argv)
{
struct Student stu;
return 0;
}这样申明一个结构体变量stu之后,这个 stu 中就包含两个变量,一个是 int 类型的 math,一个是 int 类型的 english。那么这个时候,这两个值其实并没有被初始化,这两个值是随机的值。我们可以用如下代码来为这两个变量进行赋值。
stu.math = 95;
stu.english = 93;还有一种方法,可以在申明结构体变量的时候进行初始化。
struct Student stu = {95, 93};
回到我们最初的问题,记录50个学生的成绩,程序应该怎么写呢?
struct Student
{
int math;
int english;
}
int main(int argc,char **argv)
{
struct Student stu[50];
//为其中一个学生的成绩赋值
stu[20].math = 90;
stu[20].english = 95;
return 0;
}查看全部 -
定义 存储50个学生成绩的变量
int a[50];
给数组中第 1 个变量赋值为 98 分
a[0] = 98;
声明数组的时候,就给数组赋值
int a[4] = {0, 1, 2, 3};
int a[] = {0, 1, 2, 3};
当 {} 中的元素数量少于 [] 中定义的长度的时候,只给前面部分元素赋值,后面的未指定的元素,将被赋值为 0。
int a[4] = {1, 2}; // 1, 2, 0, 0
把数组的所有元素初始化为 0
int a[4] = {0};
查看全部 -

逻辑运算符的用法
查看全部 -
定义布尔类型:
bool b = true
查看全部 -
/ 除法
除法分为两种情况,一种是整数,对于整数的除法,整数除法之后,得到的还是一个整数,如下,输出结果为 2,只保留整数部分,余数部分被舍去
但是如果是浮点数,就会有另外一种情况,会产生小数
查看全部 -
显式转换:(大容量数据类型转换为小容量时需要使用强制转换)
int a = 100;
short b = (short)a;隐式转换:(小转大,无需特别说明)
 查看全部
查看全部 -
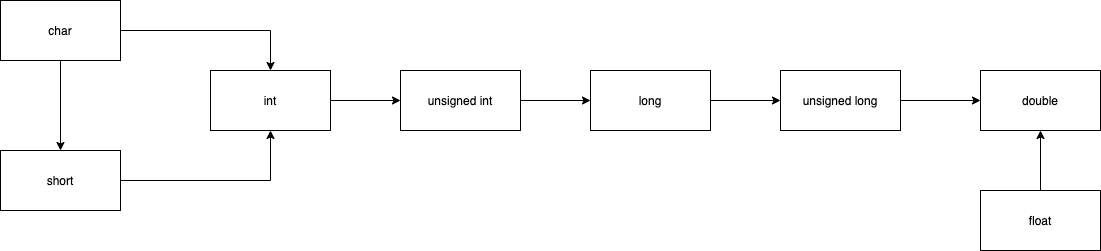
在计算机中,我们把 8 个 bit 的容量称之为 1 个 byte, 中文叫做字节。8bit = 1 byte
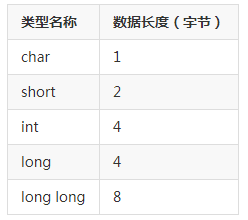
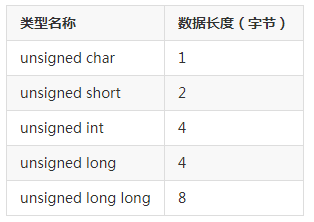
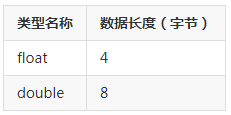
每种数据类型最大的差别就是他们所占的空间大小不一样,更大的数据类型拥有更大的容量,这也意味着他能装得下更多的数字,或者更多的精度。
其实上面的表中的数据长度,只是一个常见的默认值,不同的机器会有不同的情况,C++ 标准中并没有定义某一个数据类型必须占用多少个字节的长度,C++只定义了每种数据类型长度的一个范围。short 要大于等于 char
int 要大于等于 short
long 要大于等于 int
long long 要大于等于 long
查看每种数据类型在电脑上的占用长度:
#include <stdio.h>
int main(int argc,char **argv)
{
printf("int: %d\n", sizeof(int));
return 0;
}查看全部 -
#include<stdio.h>
int main()
{
int a = 1;
int b = 2;
bool mcr1 = a > b;
printf("bool mcr1:%d", mcr1);
return 0;
}
上一节笔记
查看全部 -
std::cout << "a: " << a << ", b: " << b << std::endl;
std::cin >> a >> b;使用 cin 可以连续从键盘读取想要的数据,以空格、tab键或换行符作为分隔符。cin 相对于 scanf 来说,不需要指明类型,用起来更方便一些。
查看全部 -
当你声明一个变量的时候,事实上他是有一个默认值的,并且这个默认值是一个随机值,在某些情况下,这个值甚至有可能是一个非法值。所以我们有时候在写 C++ 程序的时候,会给变量赋上一个默认值.
声明常量和声明一个变量非常像,不一样的地方就是在前面加了一个 const。这个 const 代表的就是不可变的。
查看全部 -
argc和argv参数在用命令行编译程序时有用。main( int argc, char* argv[], char **env ) 中
第一个参数,int型的argc,为整型,用来统计程序运行时发送给main函数的命令行参数的个数,在VS中默认值为1。
第二个参数,char*型的argv[],为字符串数组,用来存放指向的字符串参数的指针数组,每一个元素指向一个参数。各成员含义如下:
argv[0]指向程序运行的全路径名
argv[1]指向在DOS命令行中执行程序名后的第一个字符串
argv[2]指向执行程序名后的第二个字符串
argv[3]指向执行程序名后的第三个字符串
argv[argc]为NULL
第三个参数,char**型的env,为字符串数组。env[]的每一个元素都包含ENVVAR=value形式的字符串,其中ENVVAR为环境变量,value为其对应的值。平时使用到的比较少。查看全部




举报