

-
nodeValue的返回值类型为null;
查看全部 -
getFirstChild().getNodeValue方法和getTextContent()方法的区别
查看全部 -
使用getFirstChild方法,获取子节点再获取子节点的值
查看全部 -
不知道属性值的情况下,遍历所有属性值
查看全部 -
Java程序中的四种解析xml文件的方式
查看全部 -
通过dom方法解析xml文件
查看全部 -
SAX解析原理
通过自己创建的Handler处理类,去逐个分析遇到的每一个节点,从外层到里层
startElement endElement
1.通过SAXParserFactory的静态newInstance()方法获取SAXParserFactory实例factory
2.通过SAXParserFactory实例的newSAXParser()方法返回SAXParser实例parser
3.创建一个类继承DefaultHandler,重写其中的一些方法进行业务处理并创建这个类的实例handler查看全部 -
在java程序中读取xml文件的过程也称为:解析xml文件
解析的目的:获取节点名、节点值、属性名、属性值
四种解析方式:Java官方提供(DOM SAX ) 其他组织的(DOM4J JDOM)如何在java中保留xml数据的结构
DOM方式解析xml步骤
准备工作:
创建一个DocumentBuilderFactory对象
创建一个DocumentBuilder对象
通过DocumentBuilder对象的parse(String fileName)方法加载books.xml文件到当前项目下(注意:异常不要进行过多的嵌套,要合并在一起)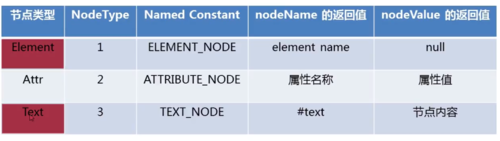
节点类型:3种
空格+换行也算子节点查看全部 -
java解析和生成xml
xml:可扩展标记语言,标准通用标记语言的子集,是一种用于标记电子文件使其具有结构性的标记语言。
表现:以 .xml 为文件扩展名的文件
存储:树形结构
为什么用使用XML
思考1:不同应用程序之间的通信
思考2:不同平台间的通信
思考3:不同平台间的数据共享e.g. MSN中存储用户的聊天记录
查看全部 -
 常用的結點類型查看全部
常用的結點類型查看全部 -
常用节点类型
查看全部 -
//SAX解析XML文件
SAXParserFactory spf=SAXParserFactory.newInstance();
SAXParser sp=spf.newSAXParser();
sp.parse("url",Handler对象);
//Handler对象需要自己创建且继承defaultHandler类;
查看全部 -
//获取book下的子节点
NodeList childnode=book.getChildNodes();
for(int i=0;i<childnode.getLength();i++){
childnode.item(i).getNodeType();//获取节点类型,以便于筛选节点
childnode.item(i).getNodeName();//获取节点名称
//获取节点的节点值
childnode.item(i).getFirstChild.getNodeValue();//节点内的值是本节点的子节点,要获取子节点后再获取节点值,否则返回的值为null。当本届点有不只一个子节点时,返回的值也为null。
childnode.item(i).getTextContent();//可直接获取book子节点的节点值。当此节点有不止一个子节点时,获取的是所有子节点的节点值。
}
查看全部 -
NodeList nodelist=document.getElementByTagName("book");//获取所有book节点。
//在不知道book有几个属性时
for(int i=0;i<nodelist.getlength;i++){
Node book=nodelist.ltem(i);//获取nodelist集合中一个节点。
NameNodeMap attrs=book.getAttributes();//获取此节点所有属性的集合。
for(int j=0;j<attrs.getLength();j++){
Node attr=attrs.item(j);//获取book节点的某个属性。
attr.getNodeName();//获取此属性的属性名。
attr.getNodeValue();//获取此属性的属性值。
}
}
//在明确知道book只有一个属性值时
Element bookid=(Element)nodelist.item(i);//注意强转
bookid.getNodeName();//获取此属性的属性名。
bookid.getNodeValue();//获取此属性的属性值。
查看全部 -
解析XML文件
创建DocumentBuilderFactory的对象。
DocumentBuilderFactory dbf=DocumentBuilderFactory.newInstance();//返回DocumentBuilderFactory对象。
创建一个DocumentBuilder对象。
DocumentBuilder db=dbf.newDocumentBuilder();
加载xml文件到当前目录下。
Document documen=db.parde("需要解析的xml文件的路径");
//注意:Document对象选用org.w3c包下的对象。
查看全部





举报