

-
hadoop课程内容
查看全部 -
Hadoop包括两个重要的组成部分,HDFS 和 MapReduce,前者是Hadoop的文件系统,后者是并行计算框架。
一、HDFS的设计架构:
-块(Block)
-NameNode
-DataNode
HDFS的文件被分成块进行存储,HDFS块默认大小是64MB,块是整个文件存储处理的逻辑单元。
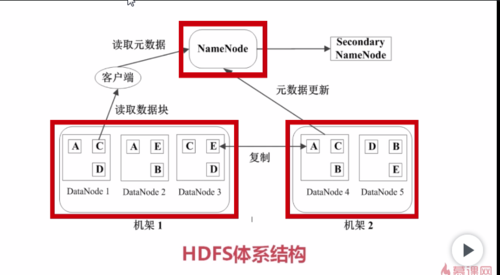
HDFS中有两类节点NameNode和DataNode
namenode是管理节点,存放文件元数据,元数据包含两个部分
文件与数据快的映射表
数据块与数据节点的映射表
namenode是唯一的管理节点,里面存放大量元数据,客户进行访问请求,首先会到namenode查看元数据,返回的结果会知道这个文件放在哪些节点上面,然后从这些节点拿数据块,然后组装成想要的文件
DateNode是HDFS的工作节点,存放数据块
查看全部 -
租用阿里云Linux主机
查看全部 -
Hadoop的组成
包括两个核心组成
1 HDFS:分布式文件系统,存储海量的数据
2MapReduce:并行处理框架,实现任务分解和调度
查看全部 -
HDFS MapReduce 开源工具(hive)
hive就是可以把你的sql语句转化成一个hadoop任务执行(降低了使用hadoop的门槛)
hbase是存储结构化数据的分布式数据库(和传统的关系型数据库的区别是放弃事务特性,追求更高的扩展)(和HDFS的区别就是habse提供数据的随机读写和实时访问,实现对表数据的读写功能)
zookeeper是监控hadoop集群的状态,管理节点间的配置,维护数据的一致性。
查看全部 -
搭建大型数据仓库,PB级数据的存储、处理、分析、统计等业务
搜索引擎、商业智能、日志分析、数据挖掘
优势:1、高扩展 , 2、低成本,3、成熟的生态圈
查看全部 -
下载软件地址: wget https://archive.apache.org/dist/hadoop/common/hadoop-1.2.1/hadoop-1.2.1.tar.gz
配置hadoop文件:
1、hadoop-env.sh
配置java 环境变量的地址
2、 core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/hadoop</value>
</property>
</configuration>
<property>
<name>dfs.name.dir</name>
<value>/hadoop/name</value>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://imooc:9000</value>
</property>
查看全部 -
马住查看全部
-
配置文件//
查看全部 -
4个配置文件
查看全部 -
MapReduce 容错机制
重复执行,一次任务失败,会进行重试,4次
推测执行,单个任务执行慢时,推测其可能出现故障,再另起一个同样的任务,并行执行,哪个先执行完使用哪个
查看全部 -
MapReduce 作业执行过程
查看全部 -
JobTracker 功能职责
查看全部 -
MapReduce 流程原理
查看全部 -
Hadoop 数据写入流程
查看全部









举报