

-
创建外部表语句“create external table tables()"
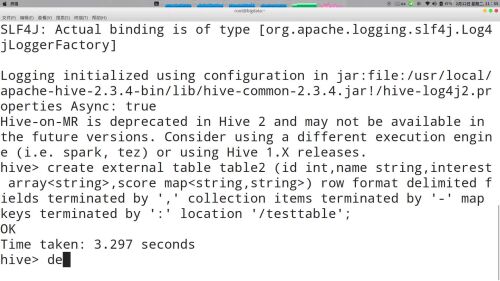 查看全部
查看全部 -
load加载".txt"文件数据到表“table1”
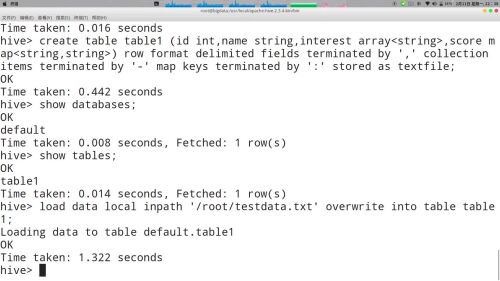 查看全部
查看全部 -
HIVE建表结构
查看全部 -
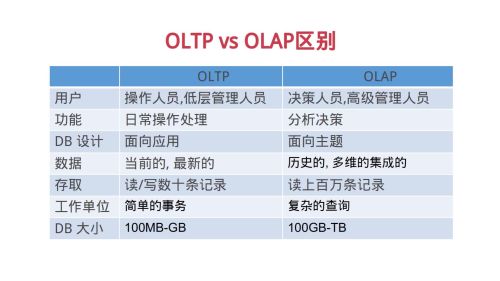
OLTP与OLAP的区别
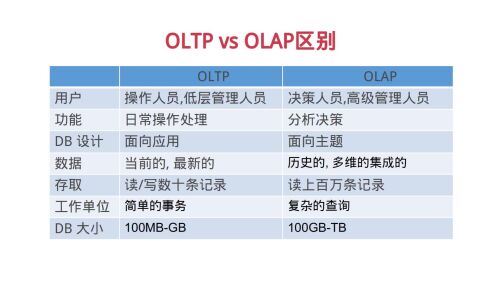 查看全部
查看全部 -
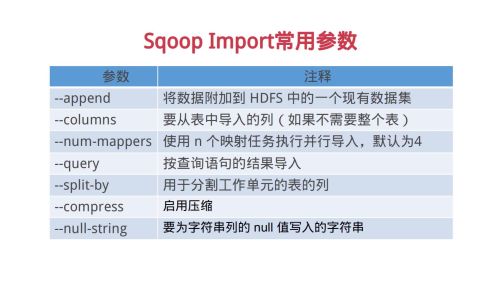 sqoop inport常用参数查看全部
sqoop inport常用参数查看全部 -

Presto是MPP架构,跨数据源查询
查看全部 -
支持JDBC的关系型数据库基本都可以使用Sqoop导入数据
 查看全部
查看全部 -

Presto是Facebook为了解决Hive问题所开发的
PB级数据快速交互式查询
查看全部 -


笔记测试二
查看全部 -



笔记测试111
查看全部 -
Hive: 基于hadoop的数据仓库, 提供类sql语法
Hive将数据映射成数据库和一张张的表,库和表的元数据信息一般存在外部关系型数据库。 以MR计算引擎,HDFS存储系统,提供超大数据集计算扩展能力。Hive的库和表是对HDFS上数据的映射。
Hive语句执行过程将Hive sql转换为MapReduce任务执行
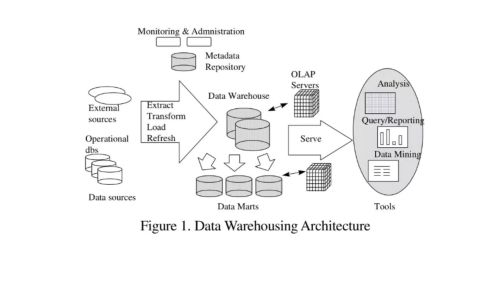
数据仓库:数据源的数据经过ETL处理后,按照一定的主题集成起来提供决策支持和联机分析应用的结构化数据环境。
ETL: Extract, Transform, Load
Sqoop输入 Presto查询输出
联机事务处理OLTP是传统关系型数据库
联机分析处理OLAP是数据仓库应用
查看全部 -
有动态添加catalog代码吗?
查看全部 -
列式存储的优势和劣势:
优势:当我们查询语句只涉及部分列的时候,只需要扫描相关列即可,不需要扫描整个的数据文件,同一列数据格式是相同的,彼此相关性更大,对于列数据的压缩效率更大,可以针对每一列的数据选择不同的数据压缩方式。
劣势:对一条数据写入更新时需要更改多个列。
数据仓库面临的主要需求是查询分析,对于更新不是特别频繁,所以数据仓库是适合使用列式存储的,同时OLAP一般是构建在分布式存储上的,受分布式文件存储特性的影响,需要快速读取,就要按块分片进行读取,修改写入都是追加写入,而非随机读写。
查看全部 -
基于Hadoop开源数据框架工具Hive,本质上是将HDFS上的数据映射成数据库、数据表等元数据,然后再对这些文件进行检索查询。
查看全部 -
create table table1 ( id int, name string, interest array<string>, score map<string,string> ) partitioned by (year int) row format delimited fields terminated by ',' collection items terminated by '-' map keys terminated by ':' stored as textfile; show partitions table1; --展示分区; alter table table1 add partition (year = 2019) location '/test' --添加分区
查看全部








举报