

-
6-4 常用的工作负载类、配置和存储类对象讲解
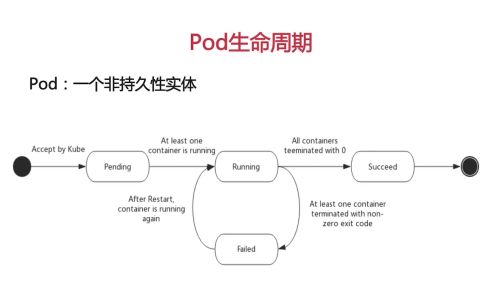
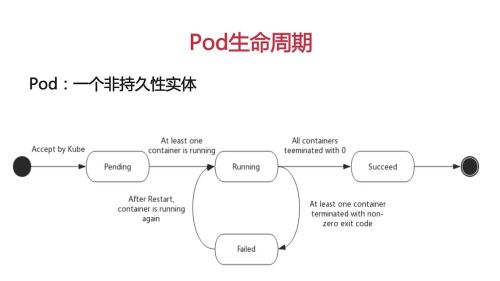
Pod的生命周期
phase:是Pod生命周期所处位置的概括,从phase的值可以反映Pod生命周期形态
Pending:挂起,创建,部署阶段,pod已经被k8s集群接受,但有一个或多个容器镜像尚未创建,即Pending阶段是通过网络下载容器镜像,调度Pod等 等待时间
Running Pod已经绑定到一个节点上,Pod中所有容器已经被创建,并且至少有一个容器正在启动或运行或重启
Succeed 此时Pod所有容器被成功终止,并且不会再重启
Failed Pod容器都已经被终止了,并且至少有一个容器因失败而终止,即容器以非0状态退出导致系统终止的
(被废除的unknown:以未知原因无法取得Pod状态)
---
Service:服务发现,负载均衡Load balance的核心对象
前言:Pod是一个非持久性的实体对象,通常会由各种原因被终止,每次重启ip地址都会改变,所以Pod的ip地址是不能被稳定依赖的;问题来了,pod的ip地址不可靠前提下,我们怎么发现并连接到Pod呢,于是有了Service抽象概念。
Service:与云原生应用的“微服务”概念一一对应
k8s为每个Service分配一个集群唯一的IP地址,在Service生命周期内,ip地址不变;在内部DNS支持下,能轻松实现服务发现机制。
Service通过label seletor关联到实际支撑业务的pod上,并通过集群内置的服务负载均衡将服务请求分发到后端Pod;即调用者无需关心pod状态如何,是否创建,pod的ip是否发生了变化。
通过nodeport或者设置load balancer(负载均衡?)还可以实现将service暴露到集群外部。
k8s还支持多重昂service,比如没有seletor的service,比如不需要分配ip不需要负载均衡的service(高级话题)
---
Controllers:与Pod关联最为紧密的控制器对象,控制器对象就是为Pod保驾护航的。
各种控制器就是为了保证一组Pod始终保证处于期望状态(desired state)正常运行。期望状态包括:Pod副本数量,节点选择,资源约束,持久化数据维持等...
常用的控制器:deployment、replicaset、statefulset、daemonset等
replicaset:副本集合控制器,确保健康Pod数量始终满足用户定义的数量。
它的前身是ReplicationController(rc),新版RS支持集合式的label selector标签筛选(等优势?)
虽然想Pod一样可以手动创建,但官方推荐使用deployment创建并由其自动管理replicaset,这样就可以不用担心兼容问题,比如repllicaset不支持滚动更新,但deployment支持。
deployment:是k8s最常用的控制器,它为Pod和ReplicaSet提供了声明式定义(yaml)。声明式的意思是,描述他们状态是怎么样的,而不是说描述他们的创建步骤和方法。
用户在deployment描述Pod和ReplicaSet的期望状态,DeploymentControlller就会自动将他们改变到期望(不要尝试手动修改由deployment自动创建的ReplicaSet,否则可能会引发未知后果)
周所周知,Deployment支持Pod的滚动更新,并自动管理背后的ReplicaSet,例如更新Pod模板、规格字段来升级Pod新状态时,Deployment会自动创建新的ReplicaSet,Deployment会根据控制速率将Pod旧的ReplicaSet移动到新的那里。以实现ReplicaSet的滚动更新。
Deployment支持Pod回滚,但仅由pod模板(Pod-template)改动的行为触发的版本升级。
---
StatefulSet:Deployment,ReplicaSet等控制器,他们仅用于无状态应用的部署和管理,对于有状态应用,v1.5后k8s提供了StatefulSet提供支持
v1.9毕业,说明可以在环境中可以正常使用了。保证了产品的先后兼容。
为了解决有状态服务的部署问题,例如需要
稳定的的持久化存储,集合的Pod被重新调度后,还是能访问到相同的持久化存储的。
稳定的网络表示;Pod重新调度后,即PodName等标签不变,
有序部署扩展:Pod是有顺序的,Pod在部署或扩展的时候,要根据定义的顺序依次进行,
有序收缩,删除:Pod在被删除收缩等过程中,也要根据定义的顺序依次进行,
有序自动滚动升级等:和有序收缩一样,依据定义的顺序依次进行,每次升级一个Pod,只有一个Pod完成升级才会进行下一个。
Pod的存储必须由RersistentVolume Provisioner根据请求的Storage Class进行配置,或由管理员预先配置好。
考虑到数据安全性,伸缩或删除StatefulSet不会删除关联的存储;另外StatefulSet要求没有class ip的Headless Service负责Pod的网络身份,用户有责任创建此类服务。(高级话题)
---
DaemonSet:特殊的控制器,保证在每个Node上都运行一个Pod副本,当增加/溢出Node,会自动增加/收回Pod副本,删除DaemonSet会删除它创建的所有Pod
适用于:系统Daemon程序sifvillike组件,监控跟踪clkD,日志收集runD等
1.6以后支持滚动更新
支持通过nodeSelector、nodeAffinity、podAffinity来选择需要部署的Node,当Node的标签发生变化时,DaemonSet会重新匹配Node,并在新匹配的Node上部署Pod副本并将原有的但此次为匹配到的Node的Pod副本删除。
---配置和存储类对象
ConfigMap:允许我们将配置信息与容器镜像内容解耦,这样可以保持容器化应用镜像的可移植性,没有必要因为配置的变动而重新制作容器镜像,常用来想Pod提供非敏感的配置信息。
configMap用于保存配置数据的键值对,可用来保存单个属性、配置文件
configMap可以用命令行基于字面值,文件或目录来创建或通过configMap对象定义文件yaml创建。
configMap可以通过三种方式在Pod中使用:环境变量,容器命令行或以文件形式通过数据卷插件挂在到Pod中。
示例:configMap的常见和使用

定义kind:configMap的yaml,里面定义属性配置data.title,data.authtor
定义一个kind:Pod的yaml,并将之前的配置信息以环境变量的形式使用
启动pod,查看输出
---
Secret使用上与ConfigMap类似,不同的是它解决是集群内密码,token,密钥等敏感数据的配置问题
应用场景:鲳鱼ServiceAccount关联,存储在tmpfs系统,Pod删除后Secret文件也会对应地删除。
有三种Secret:
Opaque:64编码格式的secret,存储密码密钥,
Service Account:在pod中访问k8s api服务的,有k8s自动创建。并挂载在到Pod指定目录中去,
dockerconfigjson:用来存储私有docker镜像仓库的认证信息,
secret可以以volume或环境变量方式使用。
查看全部 -
6-1 k8s基本概念
是深入学习k8s的基本条件
pod,deployment等,有一个共同的抽象称呼,k8s object
k8s对象:一种持久化,用于表示集群状态的实体
声明式的记录,一般用yaml描述对象
k8s对象的集合即表示当前k8s的状态。k8s对象可以表示,有哪些容器化应用在运行,容器运行在哪个node上,有哪些可以被应用使用的资源,应用的行为策略是这么样的,例如重启,升级,容错策略等
k8s对象通过api来管理;kubectl其实也是调用api来实现命令功能的,通过api可以实现对象的增删改查;管理k8s对象的过程就是管理,运维k8s的过程;k8s controller manager就是通过对象控制器使对象保持在期望状态,换句话说,k8s的工作就是让k8s对象保持在期望状态,这样k8s集群本身就在期望状态了。
k8s对象模型,面向对象
静态属性:
Kind:对象类型,如Pod,Service
Metadata:元数据
Spec:对象规格信息,不同对象的spec不同,可以参照面向对象基类与子类的关系
操作方法:
增删改查,Create,Get,Update,Delete,每种对象都有这些方法,通过API可以对对象的方法进行调用
动态信息:
k8s对象的创建就好比如一个类被实例化了,状态变成动态信息保存在etcd中,k8s状态的变化是触发k8s各组件工作的起点,k8s的工作就是讲k8s对象一直保持期望状态。
查看全部 -
4-1 演示service,pod的部署,pod伸缩等功能
官方推荐先部署service再部署Pod,因为部署容器pod的时候,会把service信息以环境变量的形式注入到pod,
官方推荐用内部DNS域名访问service,而不推荐用环境变量访问,兼容了以前必须依赖环境变量访问的应用。
k8s常用yaml定义对象
(注意:k8s总是安装在linux,所以熟悉Linux命令是基础)
yaml常见键值对意义:
apiVersion:当前yaml使用的api版本
kind:声明对象类型
metadata:
name:定义元数据的name
spec:规格说明
type:声明kind的类型,NodePort将服务暴露到k8s集群之外
selector:跟label xxx匹配后选项
app:......
ports:一组poort,跟spec.type对象,用NodePort表示这里的port是每台node监听的端口,
port:虚拟的端口,不真实存在
targetPort:容器监听的端口,到达service的流量会被负载均衡到targetPort上
nodePort:向外暴露的访问端口,外网访问的就是它
通过create命令创建service服务
kubectl create -f 配置文件.yaml --record
通过get命令查看命令是否创建成功了
kubectl get svc|grep 服务名
通过describe查看详细信息
kubectl describe svc/服务名
(如果没有部署pod,那么Endpoints对象为none)
如果此时访问:curl ip地址:nodePort/服务,就会被refused拒绝
---
k8s服务有自动注册,发现机制,通过内部DNS供多服务发现,交互
使用run命令启动busybox容器查看服务内部发现地址,即内部域名
kubectl run -i --tty busybox --image=busybox --restart=Never
在busybox使用nslookup命令查看DNS地址
nslookup 服务名
---
部署pod
官方推荐不直接部署pod,而是通过deployment controller部署pod,(怕我们配置得不完全吧?)
linux查看定义好的deployment controller的yaml配置文件
vi 文件名
spec:
replicas: 部署后pod的个数
template:pod的模板类型,子对象都是模板的具体配置信息
metadata:模板元信息
labels: 通过这个label匹配pod
app:
spec:是pod的规格信息,包括容器的名字,镜像信息,镜像拉取...
通过kubectl的create命令创建deployment
kubectl create -f hello-deployment.yaml --record=true
通过get命令查看deployment创建结果
kubectl get deployments
出现一个列表,desired:期望的pod的副本数,current:当前存在pod的副本数,up-to-date:升级到最新的副本数,available:可以给客户提供服务的pod副本数,age:部署了多久
再敲一次查看服务详情,可以发现EndPoint有两个pod的地址了
再访问一次service,接收请求并通过自动选择容器处理服务逻辑,并响应请求
---
测试pod的负载均衡
先查看pod信息
kubuctl get pods|grep 服务名
复制pod名,新开命令行,实时监测运行日志的查看pod在接收到请求后的处理信息
kubuctl logs -f pod名
再通过curl发起多次请求,
---
服务伸缩
根据服务流量大小改变pod的副本数,可以自动?
手动修改pod的副本数,直接修改depoloyment配置文件:
使配置文件生效命令:
kubectl apply -f 配置文件
查看pod副本命令:
发起多次请求
---
服务的版本升级和回退
spec.template.spec.containers.image是容器版本,可以手动修改,
保存,再apply生效
然后用rollout status命令升级容器
kubectl rollout status deployment/xxx-deployment
发出请求,查看pod的版本信息
undo命令是回退到上一版本:
kubectl rollout undo deployment/xxx-deployment
发出请求,查看pod的版本信息
查看全部 -
kubernetes,库珀拿梯子查看全部
-
将的非常好、易于理解查看全部
-
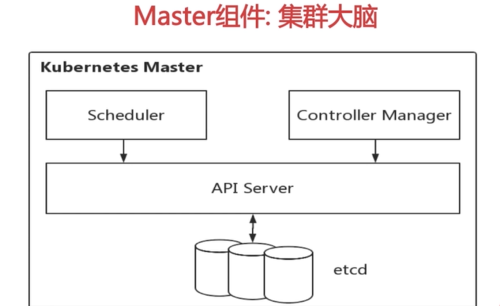
逻辑控制中心
Master
Kubernetes集群大脑,控制平面∶
所有集群的控制命令都传递给Master组件并在其上执行
每个Kubernetes集群至少有一套Master组件(当前默认:一个)
每套master组件包括三个核心组件(apiserver, scheduler
和controller-manager)以及集群数据配置中心etcd
组件:API Server-核心
API Server :
集群控制的唯一入口,是提供Kubernetes集群控制RESTful API的核心组件
集群内各个组件之间数据交互和通信的中枢
提供集群控制的安全机制(身份认证、授权以及admission control)
组件:Scheduler
Scheduler :
通过API Server的Watch接口监听新建Pod副本信息,并通过调度算法为该Pod选择一个最合适的Node
支持自定义调度算法provider
默认调度算法内置预选策略和优选策略,决策考量资源需求、服务质量、软硬件约束、亲缘性、数据局部性等指标参数
组件:ControllerManager
ControllerManager :
集群内各种资源controller的核心管理者
针对每一种具体的资源,都有相应的Controller
保证其下管理的每个Controller所对应的资源始终处于“期望状态”。
组件:Etcd
Etcd :
Kubernetes集群的主数据库,存储着所有资源对象以及状态
默认与Master组件部署在一个Node上
Etcd的数据变更都是通过API Server进行
查看全部 -
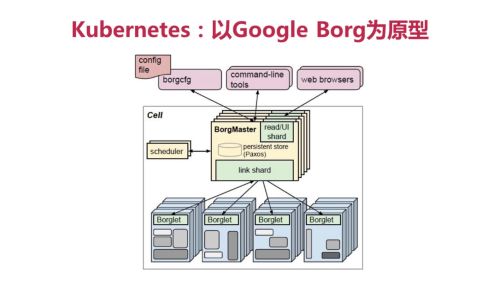
Google Borg
查看全部 -
Kubernetes对象常用的Metedata属性-Name&UID
查看全部 -
5-1 k8s架构全图解释
k8s集群是由一组节点nodes组成,节点可以是物理服务器,可以是虚拟机,k8s平台就运行在这些节点上面;
每个节点上都安装了node组件(kubelet,kube-proxy),
其中安装了master组件的叫作master node,老版本也成为miniNodes,他们是真正运行负载的节点。
miniNodes的node组件的kubelet跟master node交互,维护miniNodes的pod的生命周期。
数据存储中心 etcd,是一个数据库,存储了所有对象和状态
集群维护的命令行工具kubectl,用户以命令行方式与集群交互,操作集群
查看全部 -
Service 可以直接为后方的Deployment配置负载均衡,取代传统Nginx的作用,还可以提供地址代理。
 查看全部
查看全部 -
Pod 的生命周期
 查看全部
查看全部 -
Pod Life Cycle
 查看全部
查看全部 -
summary:
 查看全部
查看全部 -
Kube-proxy
 查看全部
查看全部 -
组件
 查看全部
查看全部








举报