

-
与pod建立连接
Service
Service :与云原生应用中“微服务”概念——对应
Kubernetes集群为每一个Service分配一个集群唯一的IP地址,在service的生命周期内,该IP地址不变﹔在内部DNS的支持下,轻松实现服务发现机制
Service通过label selector关联到实际支撑业务运行的Pod上,并通过集群内置的服务负载均衡将服务请求分发到后端Pod
通过nodeport或设置loadbalancer机制实现集群外部对service的访问
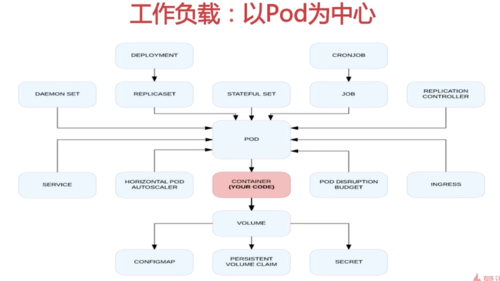
Controllers
Controller是Kubernetes核心对象之一
Controller用于保证集群内一组Pod能始终按照某种期望的状态(desired state)正常运行
状态包括:Pod副本数量、节点选择、资源约束、持久化数据维持等
Kubernetes支持多种Controller,常用的Deployment
、replicaset、statefulset、daemonset等
ReplicaSet
ReplicaSet:确保健康Pod的副本数始终满足用户定义的数量
前身是ReplicationController(rc)
相比rc,增加集合式label selector的支持
支持单独使用,但更多隐藏在Deployment控制器后面,由deployment自动管理
Deployment
Deployment :为Pod和ReplicaSet提供了声明式的定义(declarative)
用户在deployment文件中描述期望状态,Deployment controller就会自动将Pod和Replica Set的实际状态改变到期望状态
Deployment支持Pod的RollingUpdate,并自动管理背后的ReplicaSet
Deployment支持将pod Rollback到之前的任意revision(仅限于pod-template模板改动)
StatefulSet
StatefulSet:提供对有状态的应用的部署和控制的支持,1.9版本GA
适用场景︰稳定的持久化存储、稳定的网络标志、有序部署有序扩展、有序收缩有序删除、有序自动滚动升级等
Pod的存储必须由PersistentVolume Provisioner 根据请求的Storage Class进行配置,或由管理员预先配置好。
考虑数据安全性,伸缩或删除StatefulSet不会删除关联的存储﹔另外StatefulSet目前要求Headless Service负责Pod的网络身份,用户有责任创建此服务
DaemonSet
DaemonSet:保证在每个Node上都运行一个Pod副本
适用场景∶系统Daemon程序、监控跟踪、日志收集等
Kubernetes 1.6之后,可设置更新策略:支持滚动更新
可指定Node: nodeSelector、nodeAffinity.podAffinity
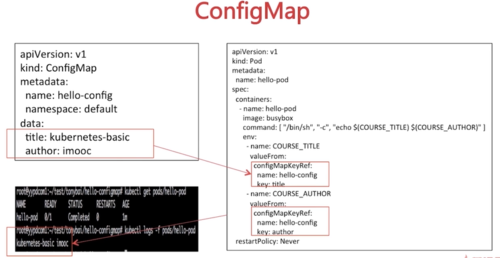
ConfigMap
ConfigMap:常用来向Pod提供非敏感的配置信息
ConfigMap 用于保存配置数据的键值对,可以用来保存单个属性,也可以用来保存配置文件
ConfigMap可以使用命令行基于字面值、文件或目录来创建或通过configmap对象定义文件创建
ConfigMap可以通过三种方式在Pod中使用:环境变量、容器命令行参数或以文件形式通过数据卷插件挂载到Pod中
Secret
Secret解决的是集群内密码、token、密钥等敏感数据的配置问题
常用于与ServiceAccount关联,存储在tmpfs 文件系统中,Pod删除后Secret文件也会对应的删除
支持Opaque , kubernetes.io/Service Account , kubernetes.io/dockerconfigjson三种类型
Secret可以以Volume或者环境变量的方式使用
 查看全部
查看全部 -
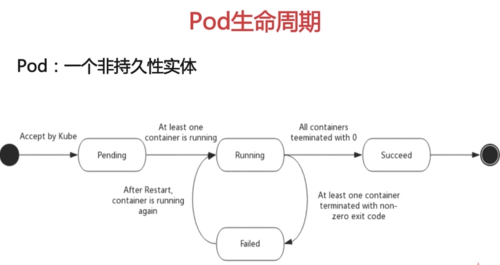
Pod:集群调度基本单元
Pod :一个有特定关系的容器集合
Pod是集群中可以创建和部署的最小且最简的kubernetes对象单元
Pod也是一种封装。它封装了应用容器,存储资源、独立的网络IP以及决定容器如何运行的策略选项
每个Pod中预置一个Pause容器,其名字空间、IPC资源、网络和存储资源被Pod内其他容器共享。Pod中的所有容器紧密协作,并且作为一个整体被管理、调度和运行
Pod生命周期
Pod :一个非持久性实体
查看全部 -

Namespace(名字空间)
Namespace,不仅仅是一个属性,本身也是一个object
Namespace :用于将物理集群划分为多个虚拟集群
Namespace间完全隔离,因此也常被用来隔离不同的用户(及权限)
内置三个Namespaces: default、kube-system和kube-public,Node和PersistentVolume不属于任何namespace
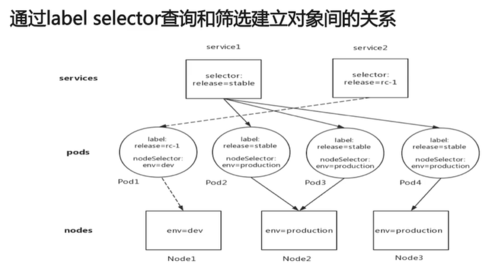
Label(标签)
Label用于建立集群对象之间的灵活的、松耦合的多维关联关系
一个label是一个键-值对,其中的key、value均由用户自己定义
label可以附着在任何对象上,每个对象也可以有任意个标签。标签可在对象定义时附加上,也可以通过命令动态管理标签
Label可以将有组织目的的结构映射到集群对象上,从而形成一个与现实世界管理结构同步对应松耦合的、多维的对象管理结构
Annotations(注解)
Annotations :可以将任意非标识性元数据附加到对象上
Annotations也是以键值对形式呈现
◆工具和库可以检索到并使用这些Annotations元数据
将数据作为Annotation附着在对象上,有利于创建一些用于部署、管理和做内部检查的共享工具或客户端
查看全部 -
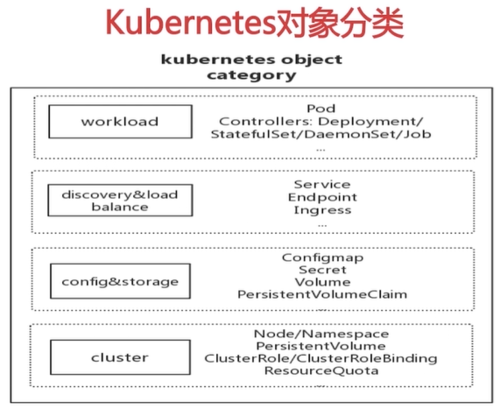
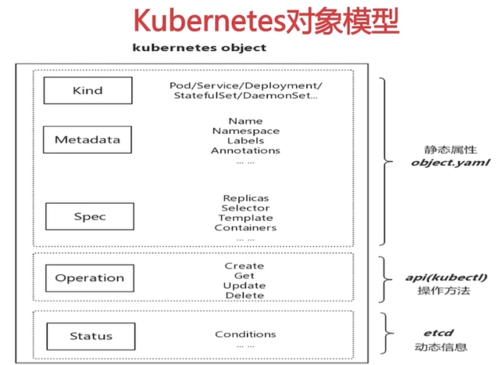
Kubernetes对象
Kubernetes对象∶是一种持久化的、用于表示集群状态的实体
—种声明式的意图的记录,一般使用yaml文件描述对象
Kubernetes集群使用Kubernetes对象来表示集群的状态
通过API/kubectl管理Kubernetes对象
 查看全部
查看全部 -
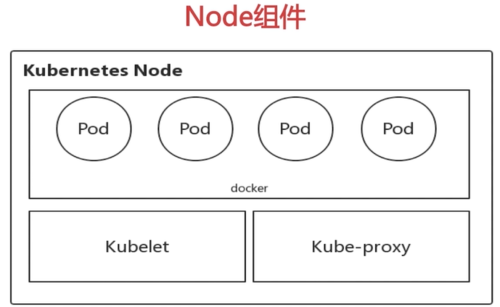
Node:工作负载节点
Node : Kubernetes集群中真正的工作负载节点
Kubernetes集群由多个Node共同承担工作负载,Pod被分配到某个具体的Node上执行
kubernetes通过node controller对node资源进行管理。支持动态在集群中添加或删除Node
每个集群Node上都会部署Kubelet和Kube-proxy两个组件
组件:Kubelet
Kubelet :
位于集群中每个Node上的非容器形式的服务进程组件,Master和node之间的桥梁
处理Master下发到本Node上的Pod创建、启停等管理任务;向APIServer注册Node信息
监控本Node上容器和节点资源情况,并定期向Master汇报节点资源占用情况
组件:Kube-proxy
Kube-proxy:运行在每个Node上
Service抽象概念的实现,将到Service的请求按策略(负载均衡)算法分发到后端Pod(Endpoint)上
默认使用iptables mode实现
支持nodeport模式,实现从外部访问集群内的service
 查看全部
查看全部 -
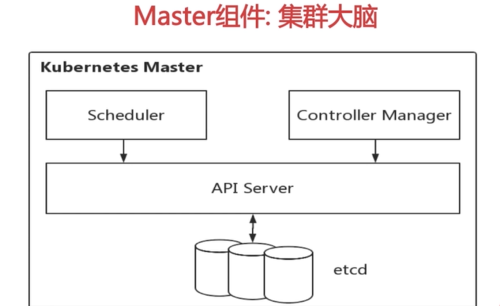
逻辑控制中心
Master
Kubernetes集群大脑,控制平面∶
所有集群的控制命令都传递给Master组件并在其上执行
每个Kubernetes集群至少有一套Master组件(当前默认:一个)
每套master组件包括三个核心组件(apiserver, scheduler
和controller-manager)以及集群数据配置中心etcd
组件:API Server-核心
API Server :
集群控制的唯一入口,是提供Kubernetes集群控制RESTful API的核心组件
集群内各个组件之间数据交互和通信的中枢
提供集群控制的安全机制(身份认证、授权以及admission control)
组件:Scheduler
Scheduler :
通过API Server的Watch接口监听新建Pod副本信息,并通过调度算法为该Pod选择一个最合适的Node
支持自定义调度算法provider
默认调度算法内置预选策略和优选策略,决策考量资源需求、服务质量、软硬件约束、亲缘性、数据局部性等指标参数
组件:ControllerManager
ControllerManager :
集群内各种资源controller的核心管理者
针对每一种具体的资源,都有相应的Controller
保证其下管理的每个Controller所对应的资源始终处于“期望状态”。
组件:Etcd
Etcd :
Kubernetes集群的主数据库,存储着所有资源对象以及状态
默认与Master组件部署在一个Node上
Etcd的数据变更都是通过API Server进行
查看全部 -
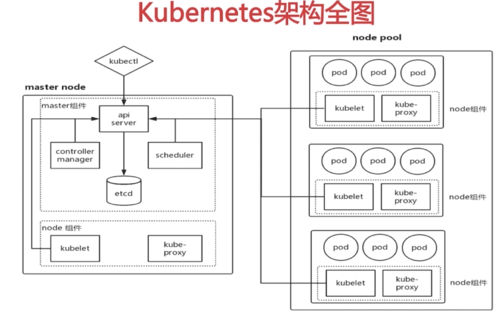 架构图查看全部
架构图查看全部 -
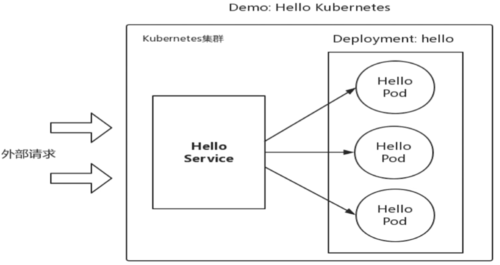
yaml文件
1.service部署
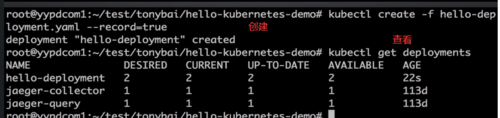
创建服务:kubectl create -f hello-service.yaml --record
查看服务是否创建成功:kubectl get svc |grep hello-service
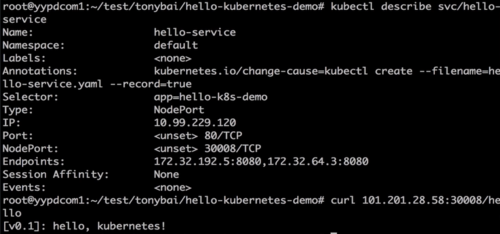
查看服务详细信息:kubectl describe svc/hello-service
访问该服务:curl ip+port/hello
在前台启动一个访问kube内部的busybox容器:kubectl run -i --tty busybox --image=busybox --restart=Never
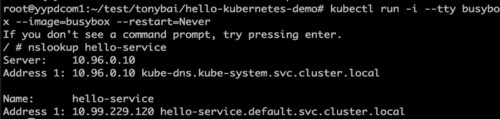
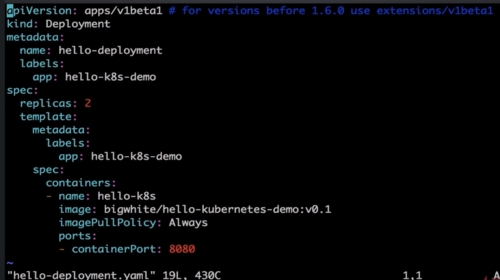
2.deployment部署
hello-deployment文件

3.请求的自动负载均衡
4.服务伸缩
修改deployment文件的replicas
 修改生效
修改生效 日志
日志5.服务版本升级与回退
修改deployment文件版本
监控pod升级过程:逐步替换

快速回滚上一版本:
 查看全部
查看全部 -
容器编排管理平台
Kubernetes作为容器管理平台提供∶
以Pod(容器组)为基本的编排和调度单元以及声明式的对象配置模型(控制器、configmap、secret等)
资源配额与分配管理
健康检查、自愈、伸缩与滚动升级
微服务支撑平台
Kubernetes提供了对微服务的支撑︰
服务发现、服务编排与内部路由支持
服务快速部署和自动负载均衡
提供对“有状态”服务的支持等
可移植的“云平台”
Kubernetes提供∶
新一代应用云化的事实标准,成为面向云原生应用的新可移植层,即新“云平台"
为用户提供简单且一致的容器化应用部署、伸缩和管理机制,形成新的、通用的应用云化模型
云厂商锁定的问题得以解决,云应用支持跨云迁移
Why Kubernetes
从生态圈角度∶
Google的业内最成熟的容器编排管理经验的输出
2017年战胜Docker Swarm和Apache Mesos,成为云原生应用唯─值得绑定的容器编排管理平台
传统云平台提供商的全面支持:Google k8s engine、Red Hat的OpenShift、Microsoft的Azure container service、IBM的cloud container service
从云应用角度,Kubernetes带来的好处∶
容器管理、调度和编排的事实标准∶摆脱锁定,支持跨云
先进的Workload管理之经验模型:Pod和Controllers
原生支持微服务抽象︰服务注册、服务发现和自动负载均衡
查看全部 -
Kubernetes是什么?
Kubernetes是以Google内部容器编排管理平台Borg为原型的开源实现
一个容器编排管理平台
一个微服务支撑平台
一个可移植的“云平台”
查看全部 -
 1查看全部
1查看全部 -
1
 查看全部
查看全部 -
虚拟化在20世纪60年代被提出
VMware虚拟机:提升计算机资源,降低使用成本
亚马逊开启基础设施即服务
以虚拟化方式部署敏感,机密的服务
平台即服务 PaaS
软件即服务 SaaS
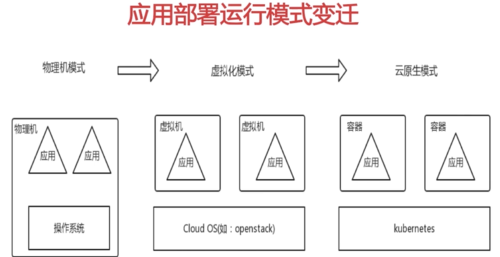
容器化2013-至今
docker:容器新时代
与VM相比,容器具有开发交付流程操作对象同步、执行更为高效、资源占用更为集约等优势。
计算基本单元由虚拟机变为了容器,越来越多应用的构建、部署与运行选择在容器中进行。
云原生:初期2015-至今
基础前提︰应用的容器化和微服务化。容器,作为应用部署、运行和管理的基本单元;
CNCF,Kubernetes : 2015年
CNCF组织的成立为应用上云安全地采用云原生模式提供了更稳、更快、更安全的解决方案,其核心是Kubernetes。
查看全部 -

盛世嫡妃是的发送到饭
查看全部 -
 地方所发生的事达搜索的发送到发的查看全部
地方所发生的事达搜索的发送到发的查看全部


举报