

-
NameNode总结:
 查看全部
查看全部 -
DataNode介绍:
 查看全部
查看全部 -
SecondaryNameNode介绍:
 查看全部
查看全部 -
NameNode介绍:
 查看全部
查看全部 -
HDFS包含:
 查看全部
查看全部 -
防火墙状态查看
centos 6
service iptables status
临时关闭
service iptables stop
开机启动移除
chkconfig iptables off
查看全部 -
Hadoop3中的三大组件的基本理论和实际操作
Hadoop3的使用,掌握企业实际开发流程
实际案例
查看全部 -
快入入门知识点
查看全部 -
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://Hadoop:19888/jobhistory/logs/</value>
</property>
查看全部 -
分布式
查看全部 -
hadoop三大部分:
分布式存储
分布式计算
集群资源管理
Spark、Flink都会使用资源管理
查看全部 -
hdfs不适合存小文件查看全部
-

使用第三个HDP
查看全部 -
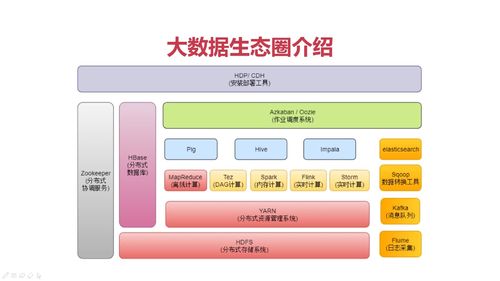
常见框架。
查看全部 -
先把计算和调度管理解耦。
HDFS的主节点可以支持两个以上。
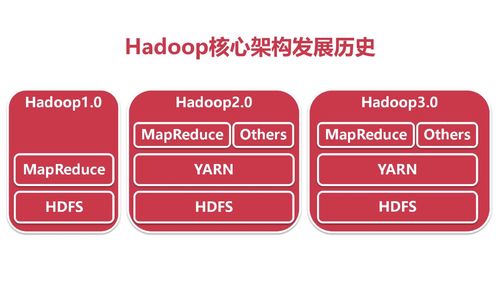 查看全部
查看全部 -

分别是:分布式存储系统,分布式计算框架,集群管理和调度(给程序分配资源)。
Yarm的数据来源和去向都是HDFS.
在Yarm上运行很多的计算框架,例如mapreduce.

HDFS架构分析:
分布式存储:由HDFS决定数据存储在哪个从节点上。
支持主从架构:

Map Reduce架构:
map体现在代码中就是一个类。
reduce就是一个聚合统计程序。

Yarm架构:

总结:数据存储和资源调度都是分布式的主从结构。
查看全部 -
hadoop里面的分布式计算。
通过程序从数据库拉取数据的过程非常慢。
mysql存储在磁盘,磁盘io,即把磁盘数据读到内存里面,再通过网络,传到计算程序里面,这两个是造成慢的主要原因。主要原因是网络io。
即发生了移动数据。
所以考虑把计算程序传输到数据所在的节点。
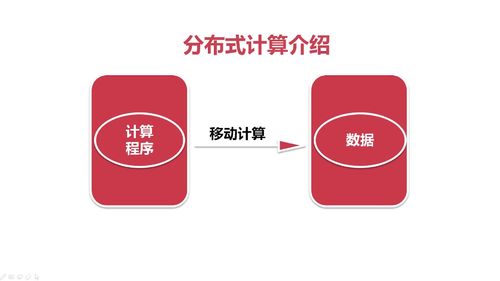
即执行本地计算,就只需做一个磁盘io。
分布式计算:
在本地执行本地计算,多台机器执行,每台计算局部计算。
全局汇总,此时数据集合的传输量比较少,网络io消耗少。
查看全部 -
分布式存储,单机的存储能力有限,运用到多台机器的存储能力。
如何设备一个分布式存储系统。
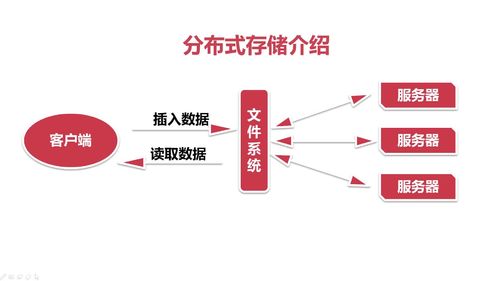
弊端:如何同时有很多请求同时过来,文件系统的请求会阻塞。
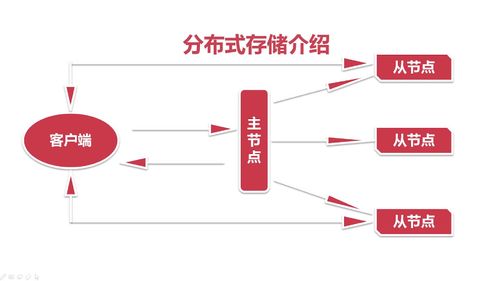
主从架构,你想要操作的数据到底在哪个从节点上,然后客户端直接操作从节点。
主要流程:
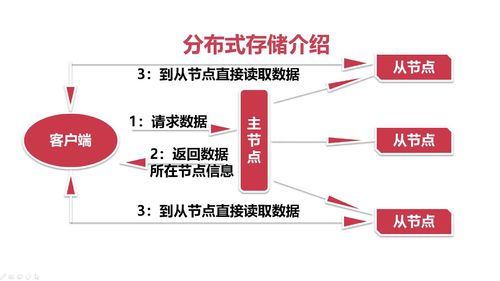 查看全部
查看全部 -
大数据在linux上运行和操作,安装部署、排查、基本的命令。
linux里面的一门shell脚本,如何开发 调试 执行脚本就行了。
javaSE内容,大多数都是java开发,不需要javaweb内容,使用IDEA工具。
数据存储在mysql数据库中。
查看全部 -
核心是数据清洗和计算的逻辑。前端用bi实现
查看全部 -
11

 查看全部
查看全部 -
Tomcat
/webapps/web项目/WEB_INF/classes/config数据库配置文件
main.db.driver= com.mysql.cj.jdbc.Driver
main.db.url = jdbc:mysql://localhost:3306/data?serverTimezone=UTC
main.db.user= root
main.db.password = admin
查看全部 -
Sqoop
mapreduce ←→ mysqlsqoop配置:
1. sqoop-env-template改名sqoop-env.sh
2. SQOOP_HOME
3. mysql驱动jar包,添加到Sqoop的lib目录下
4. 本地安装mysql和开放mysql远程访问权限(去连接集群和windows sq服务)
USE mysql; CREATE USER 'root'@'%' IDENTIFIED BY '密码'; GRANT ALL ON *.* TO 'root'@'%'; ALTER USER 'root'@'%' IDENTIFIED WITH mysql_native_password BY '密码'; FLUSH PRIVILEGES;
5. Hadoop 3.2 版本需要 common-lang.jar 到lib目录
6. mysql创建数据库
CREATE DATABASE data DEFAULT CHARACTER SET= utf8 DEFAULT COLLATE = utf8_general_ci; USE data; CREATE TABLE top10{ dt data, uid varchar(255), length bigint(20) };7. sqoop将hdfs目录的数据导出到mysql表中
sqoop export \ --connect jdbc:mysql://windows的ip:3306/data?serverTimezone=UTC \ --username root \ --password admin \ --table top10 \ --export-dir /res/videoinfojobtop10/20190821 \ #hdfs的路径 --input-fields-terminated-by "\t"
查看全部 -
!数据指标统计-直播时长Top
map阶段获取id和时长,reduce后cleanup函数对数据map集合进行排序
public class VideoInfoTop10Map extends Mapper<LongWritable, Text, Text, LongWritable>{ @Override protected void map(){ //Todo } } public class VideoInfoTop10Reduce extends Reducer<Text, LongWritable, Text, LongWritable>{ HashMap<String, Long> map = new HashMap<>(); @Override protected void reduce(){ //TODO map.put(k2.toSrting(),lengthsum); } //reduce结束后执行 @Override protected void cleanup(Context context){ //配置类中获取dt日期参数 Configuration conf = context.getConfiguration(); String dt = conf.get("dt"); //排序 Map<String,Long> sortedMap = MapUtils.sortValue(map); Set<Map.Entry<String,Long>> entries = sortedMap.entrySet(); Iterator<Map.Entry<String, Long>> it = entries.iterator(); int count=1; while(count<=10 && it.hasNext()){ Map.Entry<String, Long> entry = it.next(); String key = entry.getKey(); Long value = entry.getValue(); //封装k3,v3 Text k3 = new Text(); k3.set(key); LongWritable v3 = new LongWritable(); v3.set(value); context.write(k3,v3); count++; } } } public class VideoInfoTop10Job{ public static void main(String[] args){ //从输入路径获取日期 String[] fields = args[0].split("/"); String tmpdt= fields[fields.length -1]; String dt = DataUtils.transDataFormat(tmpdt); conf.set("dt",dt); //因为context中存放conf信息↑ //Todo } }查看全部 -
!数据指标统计
//对金币数量,总观看pv,粉丝数量,视频开播时长 等指标统计
//自定义数据类型 一个记录管理四个字段
//主播id为key,map节点<k2,v2>为<Text,自定义Writable> //自定义数据类型 public class VideoInfoWritable implements Writable{ private long gold; private long watchnumpv; private long follower; public void set(long gold, long watchnumpv, long follower){ this.gold= gold; this.watchnumpv= watchnumpv; this.follower= follower; } public long getGold(){ return gold; } @Override public void readFields(DataInput dataInput){ this.gold= dataInput.readLong(); this.watchnumpv= dataInput.readLong(); this.follower= dataInput.readLong(); } //读写数据顺序保持一致! @Override public void write(DataOutput dataOutput){ dataOutput.writeLog(gold); dataOutput.writeLog(watchnumpv); dataOutput.writeLog(follower); } //generate添加 //作为v3需要改下字段结构 @Override public String toString(){ return gold+"\t"+watchnumpv+"\t"+follower; } } public class VideoInfoMap extend Mapper<LongWritable,Text,Text,VideoInfoWritable>{ @Override protected void map(LongWritable k1, Text v1, Context context){ String line = v1.toString(); //用之前清洗后的数据 String[] fields = line.split("\t"); String id = fields[0]; long gold = Long.parseLong(fields[1]); long watchnumpv= Long.parseLong(fields[2]); long follower = Long.parseLong(fields[3]); //组装k2,v2 Text k2 = new Text(); k2.set(id); VideoInfoWritable v2 = new VideoInfoWritable(); v2.set(gold, watchnumpv, follower); Context.write(k2, v2); } } public class VideoInfoReduce extends Reducer<Text, VideoInfoWritable, Text, VideoWritable>{ @Override protected void reduce(Text k2, Iterable<VideoInfoWritable> v2s, Context context){ //从v2s把相同key的value取出, 求和 long goldsum=0; long watchnumpvsum=0; long followersum=0; for( VideoInfoWritable v2: v2s){ goldsum+= v2.getGold(); watchnumpvsum += v2.getWatchnumpv(); followersum += v2.getFollower(); } //组装 k3, v3 进行聚合 //Text k3 = k2; VideoInfoWritable v3 = new VideoInfoWritable(); v3.set(goldsum, watchnumpvsum, followersum); context.write(k3, v3); } } public class VideoInfoJob{ //执行任务job //组装map reduce public static void main(String[] args){ try{ if(args.length!=2){ } Configuration conf = new Configuration; Job job= job.getInstance(conf); job.setJarByClass(VideoInfoJob.class); //文件输入输出 FileInputFormat FileOutputFormat //map job.setMapperClass //k2类型 job.setMapOutputKeyClass //v2类型 job.setMapOutpiyValueClass //reduce job.setReducerClass //k3 job.setReducerClass // } } }查看全部 -
数据清洗
//json格式数据提取 //需要fastjson对数据解析 //不需要聚合不需要reduce //k1,v1段固定<LongWritable, Text> //k2,v2类型<Text, Text>k2主播id, v2核心字段,用\t分割 public class DataCleanMap extend Mapper<LongWritable,Text,Text,Text>{ @Override protected void map(LongWritable k1, Text v1, Context context){ String line =v1.toString(); JSONObject jsonObj= JSON.parseObject(line); String id= jsonObj.getString("uid"); int gold= jsonObj.getString("gold"); int watchnumpv= jsonObj.getString("watchnumpv"); if(gold>=0 && watchnumpv >= 0){ Text k2 = new Text(); k2.set(id); Text v2 = new Text(); v2.set(gold+ "\t" + watchnumpv); context.write(k2, v2); } } } public class DataCleanJob{ }查看全部 -
文件->分片-> MAP开始-> 分区 -> 排序 -> 分组 -> MAP结束 -> shuffle -> (reduce端)全局排序 -> 分组 -> reduce
分区:不同数据类型分类
分组:相同k2分一组
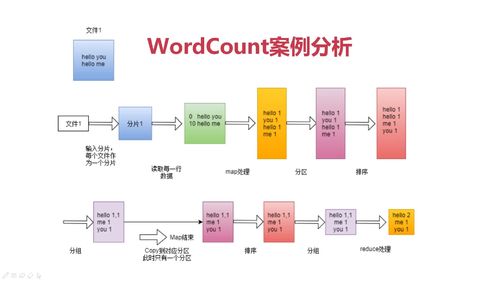
map阶段:
RecordReader类把每个InputSplit解析成<k1,v1>
一个InputSplit对应一个map task
框架对<k2,v2>分区,不同分区由不同reduce task处理,默认一个分区
map节点可以执行reduce归约,为可选项 (Combine)
shuffle:
多个map任务输出按照不同分区网络拷贝不同reduce节点
reduce阶段:
全局合并 排序 分组
reduce方法 输入<k2,{v2...}> 输出<k3,v3>
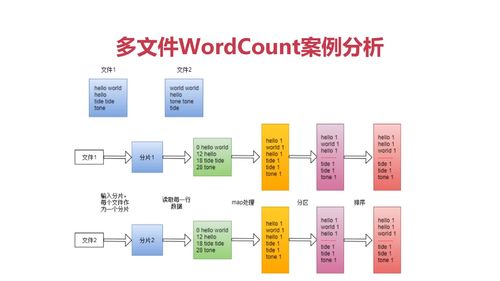
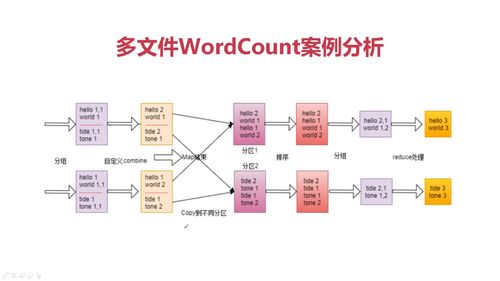 查看全部
查看全部 -
split逻辑运算块: 一个split对应一个mapper任务
K1, V1: K1是相对文本偏移量,V1代表该行文本
Shuffle:一个线程 将map产生结果拉取到reduce端做汇总
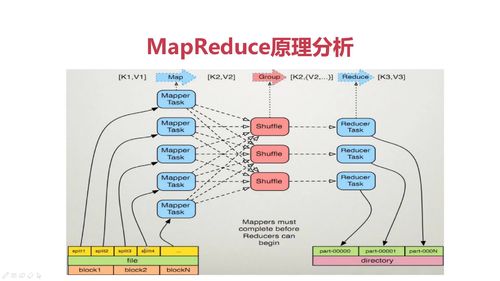 查看全部
查看全部 -
分布式计算: 将计算程序发送到本地 避免大数据传输
局部聚合 -> 数据传输(网络I/O) ->整体聚合
查看全部











举报