

-
概率分析
例子:
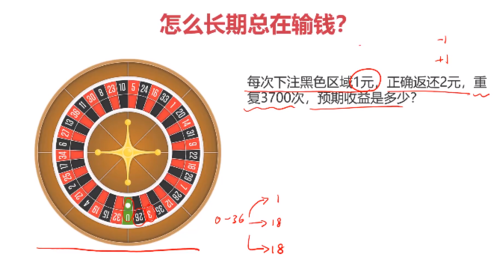
玩一次输赢的概率:
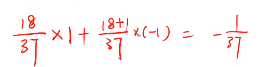
如果进行3700次:
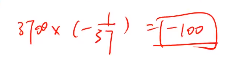
长久下去基本上都是输的
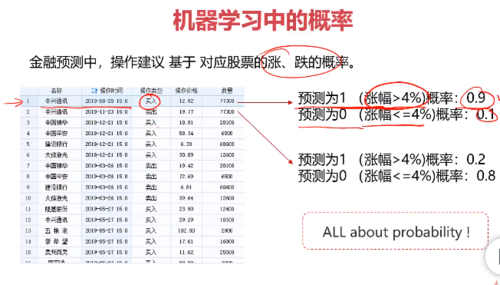
概率分析在人工智能中的应用:
分类,人面识别的情况,预测不同类别可能性的概率

>0 , 值得玩
<0, 不值得玩
在某种情况A发生下的B发生的概率: 条件概率的情况

现实的情况,就是在某种分布的条件之下计算某个事情发生的可能性

你出门的概率 1/4 ,女神出门的概率1/2 ,遇到女神的概率是1/2
全概率的情况:


总结出来

贝叶斯公式:

贝叶斯公式与全概率、条件概率公式的关系:
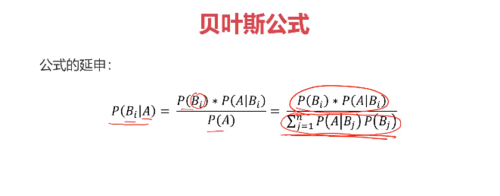
条件概率公式/全概率公式 = 贝叶斯公式

所谓的后验概率就是上面的 P( Bi | A )
朴素贝叶斯:
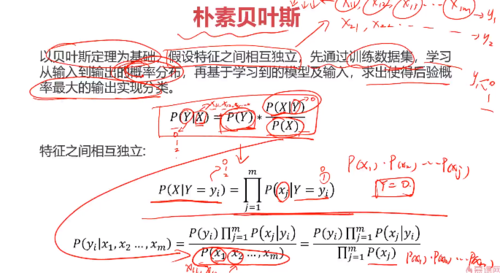
朴素贝叶斯的案例:
基于用户的性别、年龄和使用的设备,预测用户是否购买产品

yi 先计算 y=1 或 =0 的各自概率 乘以 xj|yi 计算 x1,x2, x3都为0的概率 / xj 每个x在各自组里面是0的概率
注意:y = 1 的概率和y!= 1的概率总和不为1
查看全部 -
同型矩阵:行数、列数分别相同的矩阵
负矩阵:矩阵元素互为相反数关系的矩阵(负矩阵必定为同型矩阵)
矩阵的加法:矩阵元素分别相加(互为同型矩阵才能进行加法运算)
矩阵的加法满足交换律、结合律,即:
A+B=B+A
A+B+C=A+(B+C)
矩阵的减法可以理解为对负矩阵的加法,即:
A-B=A+(-B)
矩阵的数乘:数与矩阵元素分别相乘
矩阵的数乘满足交换律、结合律、分配律
矩阵与矩阵相乘:行列元素依次相乘并求和(第一个矩阵列数等于第二个矩阵行数)
矩阵与矩阵相乘不满足交换律,满足结合律、分配律
查看全部 -
sklearn库中引入CategoricalNB失败,但是高斯NB和多项式NB都是有的,请问这是库的问题吗还是我引入错了
代码为
from sklearn.naive_bayes import CategoricalNB
返回信息为
ImportError: cannot import name 'CategoricalNB' from 'sklearn.naive_bayes' (E:\Anaconda3\lib\site-packages\sklearn\naive_bayes.py)
查看全部 -
实战: 利用朴素贝叶斯判断客户消费意愿
调用sklearn朴素贝叶斯模块的CategoricalNB, 训练模型基于用户信息,预测购买商品的概率。
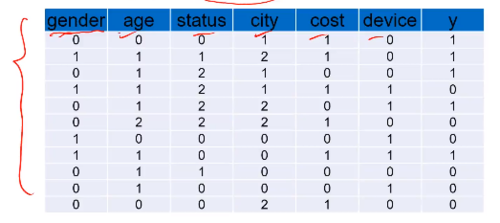
任务一:基于上面的数据,建立朴素贝叶斯模型
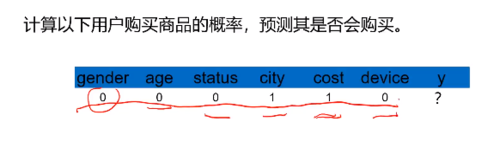
任务二:基于模型,判断上面用户会否购买
具体实现代码展示:
import pandas as pd //导入pandas库
import numpy as np //导入numpy库
data = pd.read_csv("chapter3_data.csv") //将数据预先储存为一个csv文件,然后加载到开发环境中来
data.head() //读取数据
#x赋值 x = data.drop(["y"], axis=1) //将y的一列单独去掉,axis=0为行,axis=1为列
print(x)
#y赋值 y = data.loc([: , "y"])
print(y)
#建立模型
from sklearn.naive_bayes import CategoricalNB //从sklearn包的naive_bayes之中导入 CategoricalNB
model = CategoricalNB() //建立模型实例
model.fit(x , y) //训练模型
y_predict_proba = model.predict_proba(x) //预测y=1or=0的概率
y_predict = model.predict(x) //输出y的预测值
#计算模型准确率
from sklearn.metrics import accuracy_score
accuracy = accuracy_score(y, y_predict)
print(accuracy)
任务二:
#测试样品x的预测
X_test = np.array([[0,0,0,1,1,0]]) //先将其转化成为数组形式
print(X_test)
y_predict_proba = model.predict_proba(X_test) //预测样品的购买或不购买的概率
print(y_predict_proba)
y_test = model.predict(X_test) //输出样品的预测值
print(y_test)
查看全部 -
积分:反导数
不定积分
定积分
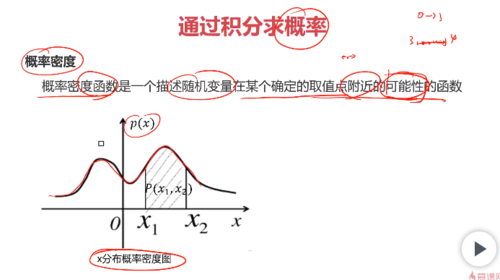
概率密度函数的概念:
 查看全部
查看全部 -
模型求解(AI相关的模型)与梯度下降法

偏导数,用于两个或以上的自变量的情况
寻找适合的a 和 b 值
目标:尽可能使模型模拟出来的y值接近实际的y值,使两者差值的平方最小化

引入损失函数,使导数后的平方抵消,由于存在m个样品,也除以m
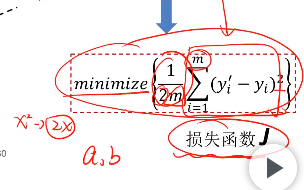
应用梯度下降法来计算收敛

最后获得一条最优解
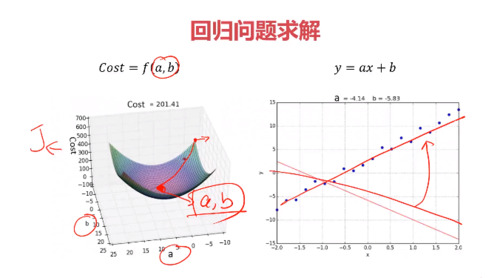 查看全部
查看全部 -
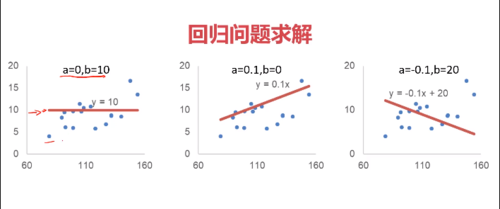
房价预测的模型:因子和房价存在线性关系
则 y =a x + b
深度学习中的矩阵运算
根据用户信息 ,预测是否消费,模仿人的神经结构系统建立深度学习模型
深度学习的基本框架 : A^2 = x * theta^1, y = A* theta^2
查看全部 -
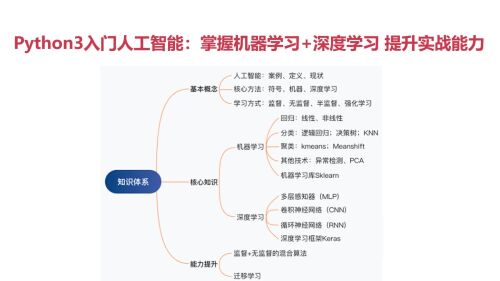

学习大纲总结
查看全部 -
一、实战 - 朴素贝叶斯的使用
调用sklearn 朴素贝叶斯模块CategoricalNB, 训练模型基于用户基本信息,预测其购买商品的概率。
import pandas as pd import numpy as np # 数据加载 data = pd.read_csv("data.csv") data.head() # X赋值 X = data.drop(['y'], axis = 1) # y 赋值 y = data.loc[:, 'y'] # 建立模型 # pip install sklearn from sklearn.native_bayes import CategoricalNB # 建立模型实例 model = CategoricalNB() # 模型训练 model.fit(X, y) y_predict_prob = model.predict_proba(X) # 输出预测y y_predict = model.predict(X) # 计算模型准确率 from sklearn.metrics import accuracy_score accuracy = accuracy_score(y, y_predict) # 测试样本的预测 X_test = np.array([0,0,0,1,1,0]) y_test_proba = model.predict_proba(X_test) y_test = model.predict(X_test)查看全部 -
一、贝叶斯公式
在已知一些条件下(部分事件发生的概率),实现对目标事件发生概率更准确的预测
P(B|A) = P(B) * P(A|B) / P(A)
贝叶斯公式则是利用条件概率和全概率公式计算后验概率
二、朴素贝叶斯
以贝叶斯定理为基础,假设特征之间相互独立,先通过训练数据集,学习从输入到输出的概率分布,再基于学习到的模型及输入,求出使得后验概率最大的输出实现分类。
P(Y|X) = P(Y) * P(X|Y) / P(X)
查看全部 -
一、条件概率与全概率
条件概率:事件A已经发生的条件下事件B发生的概率 P(B|A)
P(B|A) = P(AB) / P(A) # P(AB) AB同时发生的概率
全概率:将复杂事件A的概率求解问题,转化为在不同情况下发生的简单事件的概率的求和问题
查看全部 -
一、概率基础知识
矩阵、微积分 ---> 回归;概率 ---> 分类
概率:可能性的度量 likehood
查看全部 -
一、Python 实现微分与积分
使用 sympy 包
import sympy as sp
x = sp.Symbol('x')
y = 3 * x ** 2 # ** 幂运算
# 求导(求微分)
f1 = sp.diff(y)
# 求积分
F1 = sp.integrate(f1, x)
# 求极限
x = 0 时
L1 = sp.limit(y1, x, 0)
查看全部 -
一、积分
逆运算:导数推出原函数 --> 积分
不定积分:函数f的不定积分,是一个可导函数F且其导数等于原来的函数f
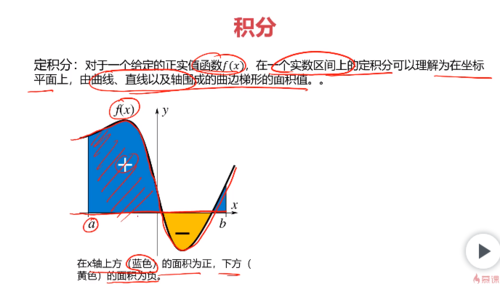
定积分:对于一个给定的正实数函数f(x),在一个实数区间上的定积分可以理解为在坐标平面上,由曲线、直线以及轴围成的曲边梯形的面积值。
作用:求面积,确定概率

查看全部 -
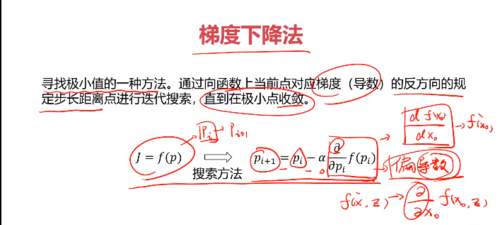
一、梯度下降法 (梯度即导数)
寻找极小值的一种方法。通过向函数上当前点对应梯度(导数)的反方向的规定步长距离点进行迭代搜索,直到在极小点收敛。
核心:从一个点出发,沿着导数的反方向逐步逼近极值点。
查看全部




举报