

-
Grouping方式
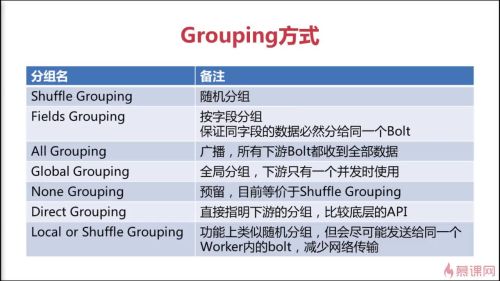 查看全部
查看全部 -
环境搭建:
1.下载安装zookeeper
2.生成一个新的配置文件 zoo.cfg
3.修改配置文件:vi zookeeper-3.4.6/conf/zoo.cfg
添加以下内容:
tickTime=2000
dataDir=/Users/dev/zookeeper-3.4.6/data
clientPort=2181
4.进入zookeeper目录: cd zookeeper-3.4.6
5.启动zookeeper服务: sh bin/zkServer.sh start
6.查看运行状态:echo stat | nc 127.0.0.1 2181
zookeeper集群版配置:
1.生成zoo.cfg.cluster文件,vi zoo.cfg.cluster
内容如下:
tickTime=2000
dataDir=/Users/dev/zookeeper-3.4.6/data
clientPort=2181
server.1=xx.xx.xx.xx:2182
server.2=xx.xx.xx.xx:2182
server.3=xx.xx.xx.xx:2182
syncLimit=2
initLimit=5
2.创建新文件 vi myid
内容如下:
1
3.在每台安装zookeeper的机器上启动服务即可
启动storm
1.进入storm文件:cd apache-storm-0.9.5
2.启动storm服务:
nohup bin/storm nimbus &
nohup bin/storm supervisor &
nohup bin/storm ui &
3.访问:http://localhost:8080/index.html
4.集群模式下,需要更改配置文件 vi conf/storm.yaml, 修改zk配置
提交一个jar包到storm:
1.查看文件:ls examples/storm-starter/
2.提交jar: ./bin/storm jar examples/storm-starter/storm-starter-topologies-0.9.5.jar storm.starter.WordCountTopology wordcount
3.访问http://localhost:8080/index.html 就能看到
4.关闭命令:./bin/storm kill wordcount
查看全部 -
数据可靠性:





Nimbus挂掉,换台机器重启就可
supervisor挂掉,将上面的worker迁移走就可以
worker挂掉,利用ack机制保证数据未处理成功,会通知spout重新发送.需要对记录通过msgId进行去重.也就是spout发送tuple时指定msgId,
spout也挂掉: 可以将数据记录到外部存储,设置checkpoint。查看全部 -
task数逻辑数,就是前面设置的.setNumTasks(7)<br>
worker是进程数
executor是表示线程数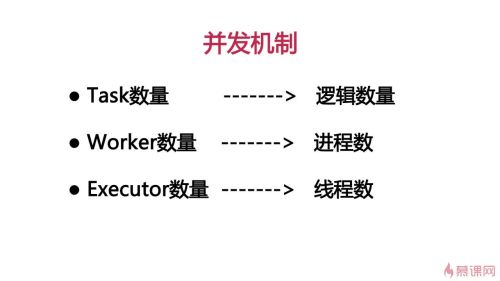 查看全部
查看全部 -
循环运行了100次,而且有7个并发,所有每个单词的数量都是700的倍数
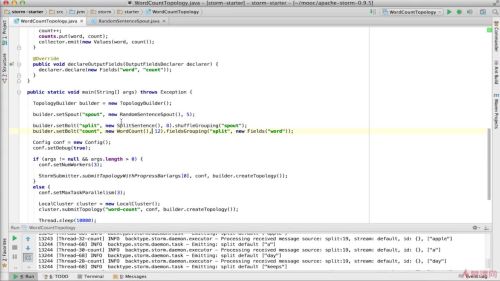 查看全部
查看全部 -
Spout继承BaseRichSpout 并包含几个方法(声明字段、初始化、数据读取和输出)
Spout中 nextTuple方法:随机读取String sentence中的句子通过_collector.emit(next)发送给下游查看全部 -
grouping:
随机发送
按一定规则发送
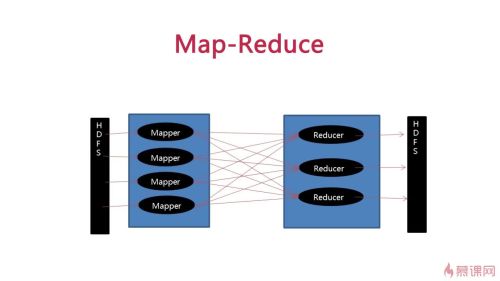
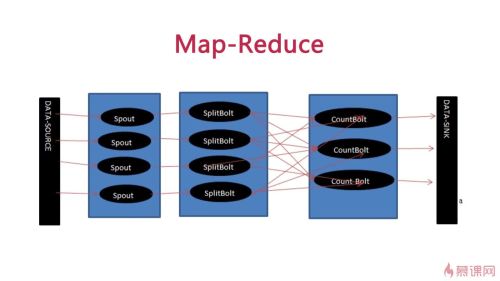
strom: kafka-->数据源结点spout多个(数据来源,发送一个个Tuple给到bolt,同样的Tuple会发到同样的bolt),普通计算结点bolt(可调用其它语言脚本,如java,python)多个(计算完可以持久化到数据库),数据流stream,记录Tuple。
Hdfs: Mapper从hdfs中读取数据并计算,进行整理后(同一个word一定落到同一个reduce里)发送给reduce-再发送给hdfs查看全部 -
$ cd apache-storm-0.9.5
$ cd examples/storm-starter/
$ mv test
$ mvn exec:java "-Dstorm.topology=storm.starter.WordCountTopology"
查看全部 -
storm作业提交运行流程
1.用户编写storm Topolgy(wordCountTopology) 一个用户作业
2.使用client提交Topolgy给nimbus
3.nimbus提派Task给supervisor
4.supervisor为task启动worker
5.worker执行task
--------------------------
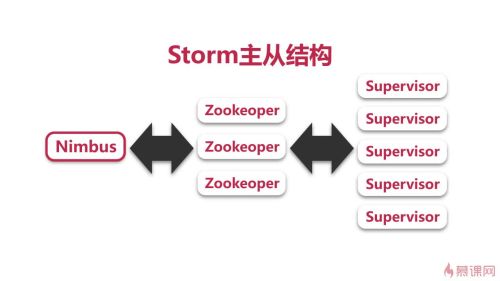
storm采用主从结构,主Nimbus和多个从Supervisor,Nimbus只负责管理性的工作单点问题必须保证主节点是无状态的,重启就能恢复,相关元数据配置信息都是存储在zookeeper上。Supervisor主要听Nimbus的话管理启动和监控worker, worker是真正干活的进程负责数据传输和计算.
-------------------------------
Storm 主从结构
Nimbus 主节点,只负责整体分配工作,不具体干活
Supervisor 从节点,维护每台机器,直接管理干活的Worker
Worker 真正干活的(task)进程,数据计算和传输
DRPC
Storm UI 监控WEB
运行流程
用户编写作业
使用客户端提交给Nimbus
Nimbus指派Task给Supervisor
Supervisor 为task启动Worker
Worker 执行Task 查看全部
查看全部 -
Google发明的几篇论文解决了各个公司升级服务器的弊端,
分布式框架三篇论文;
google file system
bigTable
MapReduce
流式计算和批量计算:
目前有些人希望通过同一API解决批量计算和流式计算:
Summer bird
Clouddataflow批量计算 流式计算
数据到达 计算开始前数据已准备好 计算进行中数据持续到来
计算周期 计算完成后会结束计算 一般会作为服务持续运行
使用场景 时效性要求低的场景 时效性要求高的场景 查看全部
查看全部 -
storm走也提交运行流程
查看全部 -
huh查看全部
-
Storm主从结构
查看全部 -
批量计算与流式计算的区别
查看全部 -
我的笔记test13我的笔记test13我的笔记test13我的笔记test13我的笔记test13
我的笔记test13我的笔记test13我的笔记test13我的笔记test13我的笔记test13我的笔记test13我的笔记test13我的笔记test13我的笔记test13我的笔记test13我的笔记test13我的笔记test13
我的笔记test13我的笔记test13我的笔记test13我的笔记test13我的笔记test13我的笔记test13我的笔记test13我的笔记test13我的笔记test13我的笔记test13我的笔记test13我的笔记test13
我的笔记test13我的笔记test13我的笔记test13我的笔记test13我的笔记test13我的笔记test13我的笔记test13我的笔记test13我的笔记test13我的笔记test13我的笔记test13我的笔记test13
我的笔记test13我的笔记test13我的笔记test13我的笔记test13我的笔记test13我的笔记test13我的笔记test13我的笔记test13我的笔记test13我的笔记test13我的笔记test13我的笔记test13我的笔记test13我的笔记test13我的笔记test13我的笔记test13我的笔记test13我的笔记test13我的笔记test13我的笔记test13我的笔记test13我的笔记test13我的笔记test13我的笔记test13我的笔记test13我的笔记test13我的笔记test13我的笔记test13我的笔记test13我的笔记test13我的笔记test13我的笔记test13我的笔记test13我的笔记test13我的笔记test13我的笔记test13我的笔记test13
查看全部 -
我的笔记test13
查看全部 -
我的笔记test12
查看全部 -
我的笔记test11
查看全部 -
我的笔记test10
查看全部





举报