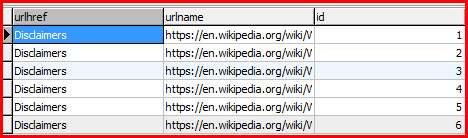
脚本可以执行成功,数据库只有一条数据,这是为什么?

脚本可以执行成功,数据库只有一条数据,这是为什么?
脚本可以执行成功,数据库只有一条数据,这是为什么?
2017-04-08
#我刚刚测试了自己的代码,发现完全没有问题
#首先,这样,你把下面这段代码完全复制到你的运行环境进行测试
from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
import pymysql.cursors
resp = urlopen("https://en.wikipedia.org/wiki/Main_Page").read().decode("utf-8")
soup = BeautifulSoup(resp,"html.parser")
listUrls = soup.findAll("a",href=re.compile(r"^/wiki/"))
for url in listUrls:
if not re.search("\.(jpg|JPG)$", url["href"]):
print(url.get_text(),"<---->","https://en.wikipedia.org"+url["href"])
#这里要缩进,不然后面面取得URL的值就是for遍历的卒子后一个值,才会出现在打印过程中没有问题,
#但是插入数据库出现问题,
#不过我觉得在遍历过程的外面连接数据库可能好点,我觉得每一次遍历都会连接数据库的代价太高了
connection=pymysql.connect(
host='localhost',
user='root',
password='lqmysql',
db='wikiurl',
charset='utf8mb4'
)
try:
with connection.cursor() as cursor:
sql="insert into `urls`(`urlhref`,`urlname`)values(%s,%s)"
cursor.execute(sql,(url.get_text(),"https://en.wikipedia.org"+url["href"]))
connection.commit()
finally:
connection.close()
#查看自己的运行结果,应该没有什么问题,我的就是这样的
#
#
#然后,你复制下面这段代码去测试一下
from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
import pymysql.cursors
resp = urlopen("https://en.wikipedia.org/wiki/Main_Page").read().decode("utf-8")
soup = BeautifulSoup(resp,"html.parser")
listUrls = soup.findAll("a",href=re.compile(r"^/wiki/"))
for url in listUrls:
if not re.search("\.(jpg|JPG)$", url["href"]):
print(url.get_text(),"<---->","https://en.wikipedia.org"+url["href"])
connection=pymysql.connect(
host='localhost',
user='root',
password='lqmysql',
db='wikiurl',
charset='utf8mb4'
)
try:
with connection.cursor() as cursor:
sql="insert into `urls`(`urlhref`,`urlname`)values(%s,%s)"
cursor.execute(sql,(url.get_text(),"https://en.wikipedia.org"+url["href"]))
connection.commit()
finally:
connection.close()
#这一次,应该只有一条语句插入了
#每次运行完,可视化数据库软件要记得刷新一下from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
import pymysql.cursors
resp = urlopen("https://en.wikipedia.org/wiki/Main_Page").read().decode("utf-8")
soup = BeautifulSoup(resp,"html.parser")
listUrls = soup.findAll("a",href=re.compile("^/wiki/"))
for url in listUrls:
if not re.search("\.(jgp||JPG)$", url["href"]):
print(url.get_text(),"<---->","https://en.wikipedia.org"+url["href"])
#这里要缩进,不然后面面取得URL的值就是for遍历的卒子后一个值,才会出现在打印过程中没有问题,
#但是插入数据库出现问题,
#不过我觉得在遍历过程的外面连接数据库可能好点,我觉得每一次遍历都会连接数据库的代价太高了
connection=pymysql.connect(
host='localhost',
user='root',
password='lqmysql',
db='wikiurl',
charset='utf8mb4'
)
try:
with connection.cursor() as cursor:
sql="insert into `urls`(`urlhref`,`urlname`)values(%s,%s)"
cursor.execute(sql,(url.get_text(),"https://en.wikipedia.org"+url["href"]))
connection.commit()
finally:
connection.close()from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
import pymysql.cursors
resp = urlopen("https://en.wikipedia.org/wiki/Main_Page").read().decode("utf-8")
soup = BeautifulSoup(resp,"html.parser")
listUrls = soup.findAll("a",href=re.compile("^/wiki/"))
for url in listUrls:
if not re.search("\.(jgp||JPG)$", url["href"]):
print(url.get_text(),"<---->","https://en.wikipedia.org"+url["href"])
connection=pymysql.connect(
host='localhost',
user='root',
password='lqmysql',
db='wikiurl',
charset='utf8mb4'
)
try:
with connection.cursor() as cursor:
sql="insert into `urls`(`urlhref`,`urlname`)values(%s,%s)"
cursor.execute(sql,(url.get_text(),"https://en.wikipedia.org"+url["href"]))
connection.commit()
finally:
connection.close()
举报