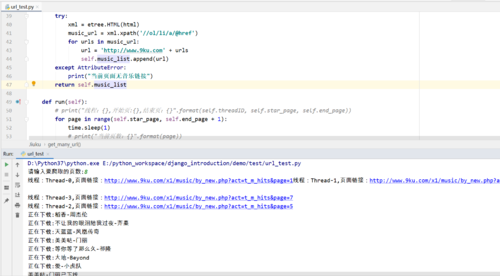
代码出现问题
import requests,time,random
from lxml import etree
from multiprocessing import Pool
from threading import Thread
from urllib import request
user_agent = [
"Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)",
"Mozilla/4.0 (compatible; MSIE 7.0; AOL 9.5; AOLBuild 4337.35; Windows NT 5.1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
]
headers={"User-Agent": random.choice(user_agent)}
filk=r'C:\Users\25063\Desktop\音乐'
class jiuku(Thread):
url='http://www.9ku.com/x1/music/by_new.php?act=t_m_hits&page='
def __init__(self,star_page,end_page):
super(jiuku,self).__init__()
self.star_page=star_page
self.end_page=end_page
self.music_list=[]
def get_one_html(self,page):
'''获取一个页面的html'''
now_url=self.url+str(page)
print(now_url)
r=requests.get(now_url,headers=headers)
return r.text
def get_many_url(self,html):
'''根据html解析得到音乐的url'''
xml=etree.HTML(html)
music_url=xml.xpath('//ol/li/a/@href')
for urls in music_url:
url='http://www.9ku.com'+urls
self.music_list.append(url)
return self.music_list
def down_one_music(self,url):
r=requests.get(url,headers=headers)
xml=etree.HTML(r.text)
title=xml.xpath('//div[@class="playingTit"]/h1/text()')[0]
singer=xml.xpath('//div[@class="playingTit"]/h2/a/text()')[0]
music=title+'-'+singer
music_id=url.split('/')[-1].split('.')[0]#获取音乐的id
print('正在下载:{}'.format(music))
music_url='http://mp3.9ku.com/m4a/{}.m4a'.format(music_id)
request.urlretrieve(music_url,filk+music+'.mp3')
def run(self):
for page in range(self.star_page,self.end_page):
time.sleep(1)
html=self.get_one_html(page)
music_list=self.get_many_url(html)
pool=Pool()
'''使用多进程进行下载,但是出错'''
pool.map(self.down_one_music,[url for url in music_list])
# for i in music_list:
# self.down_one_music(i)
def main():
number = int(input('请输入要爬取的页数:'))
if number <= 4:
a = [i for i in range(0, number+1)]
a1_min = min(a)
a1_max = max(a)
down = jiuku(a1_min, a1_max)
down.start()
else:
a = [i for i in range(0, number)]
d = number / 4 # 得到的数是一个浮点数
e = int(d) # 这一步是对浮点数变为整数,程序会将整数后面的小数全部清理这是的e就会小于d
if d > e: # 判断如果e小于b则就需要将每个小列表中的数量为e+1
step = e + 1
b = [a[i:i + step] for i in range(0, len(a), step)]
else:
step = e
b = [a[i:i + step] for i in range(0, len(a), step)]
a1_max = max(b[0])
a1_min = min(b[0])
a2_max = max(b[1])
a2_min = min(b[1])
a3_max = max(b[2])
a3_min = min(b[2])
a4_max = max(b[3])
a4_min = min(b[3])
down = jiuku(a1_min, a1_max)
down.start()
down1 = jiuku(a2_min, a2_max)
down1.start()
down2 = jiuku(a3_min, a3_max)
down2.start()
down3 = jiuku(a4_min, a4_max)
down3.start()
if __name__ == '__main__':
main()
# def main():
# a=int(input('da:'))
# d=int(input('agd:'))
# down=jiuku(a,d)
# down.run()
# if __name__ == '__main__':
# main()上面的代码 我是打算使用多进程家多线程进行下载但是出错 为什么?