老师能帮忙看下这个是怎么回事吗,谢谢
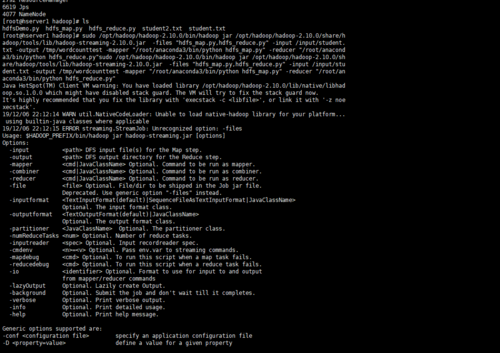
sudo /opt/hadoop/hadoop-2.10.0/bin/hadoop jar /opt/hadoop/hadoop-2.10.0/share/hadoop/tools/lib/hadoop-streaming-2.10.0.jar -files "hdfs_map.py,hdfs_reduce.py" -input /input/student.txt -output /tmp/wordcounttest -mapper "/root/anaconda3/bin/python hdfs_map.py" -reducer "/root/anaconda3/bin/python hdfs_reduce.py"sudo /opt/hadoop/hadoop-2.10.0/bin/hadoop jar /opt/hadoop/hadoop-2.10.0/share/hadoop/tools/lib/hadoop-streaming-2.10.0.jar -files "hdfs_map.py,hdfs_reduce.py" -input /input/student.txt -output /tmp/wordcounttest -mapper "/root/anaconda3/bin/python hdfs_map.py" -reducer "/root/anaconda3/bin/python hdfs_reduce.py"
#!/opt/anaconda3/bin/python
#-*- coding:utf-8 -*-
import sys
def read_input(file):
for line in file:
yield line.split()
def main():
data=read_input(sys.stdin)
for words in data:
for word in words:
print("%s%s%d" % (word,'\t',1))
if __name__=='__main__':
main()#!/opt/anaconda3/bin/python
# -*- coding:utf-8 -*-
import sys
from operatorimportitemgetter
from itertoolsimport groupby
def read_mapper_output(file,separator='\t'):
for line in file:
yieldline.rstrip().split(separator,1)
def main():
data=read_mapper_output(sys.stdin)
for current_word,group in groupby(data,itemgetter(0)):
total_count=sum(int(count) for current_word,count in group)
print("%s%s%d"%(current_word,'\t',total_count))
if __name__=='__main__':
main()