我想使用 PyArrow 将以下 Pandas 数据框存储在镶木地板文件中:import pandas as pddf = pd.DataFrame({'field': [[{}, {}]]})field列的类型是字典列表: field0 [{}, {}]我首先定义相应的 PyArrow 架构:import pyarrow as paschema = pa.schema([pa.field('field', pa.list_(pa.struct([])))])然后我使用from_pandas():table = pa.Table.from_pandas(df, schema=schema, preserve_index=False)这将引发以下异常:Traceback (most recent call last): File "<stdin>", line 1, in <module> File "table.pxi", line 930, in pyarrow.lib.Table.from_pandas File "/anaconda3/lib/python3.6/site-packages/pyarrow/pandas_compat.py", line 371, in dataframe_to_arrays convert_types)] File "/anaconda3/lib/python3.6/site-packages/pyarrow/pandas_compat.py", line 370, in <listcomp> for c, t in zip(columns_to_convert, File "/anaconda3/lib/python3.6/site-packages/pyarrow/pandas_compat.py", line 366, in convert_column return pa.array(col, from_pandas=True, type=ty) File "array.pxi", line 177, in pyarrow.lib.array File "error.pxi", line 77, in pyarrow.lib.check_status File "error.pxi", line 87, in pyarrow.lib.check_statuspyarrow.lib.ArrowTypeError: Unknown list item type: struct<>我做错了什么还是 PyArrow 不支持?我使用 pyarrow 0.9.0、pandas 23.4、python 3.6。
3 回答
拉莫斯之舞
TA贡献1820条经验 获得超10个赞
根据这个 Jira 问题,在 2.0.0 版中实现了混合结构和列表嵌套级别的嵌套 Parquet 数据的读取和写入。
以下示例通过执行往返来演示实现的功能:pandas 数据框 -> parquet 文件 -> pandas 数据框。使用的 PyArrow 版本是 3.0.0。
最初的熊猫数据框有一个字典类型列表的字段和一个条目:
field
0 [{'a': 1}, {'a': 2}]
示例代码:
import pandas as pd
import pyarrow as pa
import pyarrow.parquet
df = pd.DataFrame({'field': [[{'a': 1}, {'a': 2}]]})
schema = pa.schema(
[pa.field('field', pa.list_(pa.struct([('a', pa.int64())])))])
table_write = pa.Table.from_pandas(df, schema=schema, preserve_index=False)
pyarrow.parquet.write_table(table_write, 'test.parquet')
table_read = pyarrow.parquet.read_table('test.parquet')
table_read.to_pandas()
输出数据帧与输入数据帧相同,因为它应该是:
field
0 [{'a': 1}, {'a': 2}]
千巷猫影
TA贡献1829条经验 获得超7个赞
这是重现此错误的片段:
#!/usr/bin/env python3
import pandas as pd # type: ignore
def main():
"""Main function"""
df = pd.DataFrame()
df["nested"] = [[dict()] for i in range(10)]
df.to_feather("test.feather")
print("Success once")
df = pd.read_feather("test.feather")
df.to_feather("test.feather")
if __name__ == "__main__":
main()
请注意,从熊猫到羽毛,没有任何中断,但是一旦从羽毛加载数据帧并尝试写回它,它就会中断。
要解决这个问题,只需更新到 pyarrow 2.0.0:
pip3 install pyarrow==2.0.0
截至 2020 年 11 月 16 日可用的 pyarrow 版本:
0.9.0, 0.10.0, 0.11.0, 0.11.1, 0.12.0, 0.12.1, 0.13.0, 0.14.0, 0.15.1, 0.16.0, 0.17.0, 0.17.1., 10 0、1.0.1、2.0.0
翻翻过去那场雪
TA贡献2065条经验 获得超14个赞
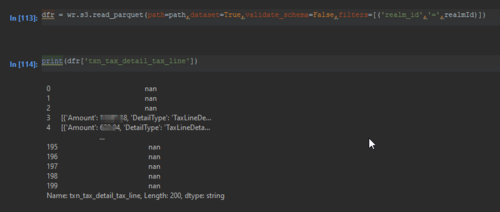
我已经能够将列中有数组的 Pandas 数据帧保存为镶木地板,并通过将对象的数据帧 dtypes 转换为 str 将它们从镶木地板读回数据帧。
def mapTypes(x):
return {'object': 'str', 'int64': 'int64', 'float64': 'float64', 'bool': 'bool',
'datetime64[ns, ' + timezone + ']': 'datetime64[ns, ' + timezone + ']'}.get(x,"str") # string is default if type not mapped
table_names = [x for x in df.columns]
table_types = [mapTypes(x.name) for x in df.dtypes]
parquet_table = dict(zip(table_names, table_types))
df_pq = df.astype(parquet_table)
import awswrangler as wr
wr.s3.to_parquet(df=df_pq,path=path,dataset=True,database='test',mode='overwrite',table=table.lower(),partition_cols=['realmid'],sanitize_columns=True)
下图显示了使用 AWS datawrangler 库从存储在 s3 中的镶木地板文件读取到数据帧,我也使用 pyarrow 完成了此操作
添加回答
举报
0/150
提交
取消