我有这样的代码: corpus = [ 'This is the first document.', 'This document is the second document.', 'And this is the third one.', 'This document is the fourth document.', 'And this is the fifth one.', 'This document is the sixth.', 'And this is the seventh one document.', 'This document is the eighth.', 'And this is the nineth one document.', 'This document is the second.', 'And this is the tenth one document.', ] vectorizer = skln.TfidfVectorizer() X = vectorizer.fit_transform(corpus) tfidf_matrix = X.toarray() accumulated = [0] * len(vectorizer.get_feature_names()) for i in range(tfidf_matrix.shape[0]): for j in range(len(vectorizer.get_feature_names())): accumulated[j] += tfidf_matrix[i][j] accumulated = sorted(accumulated)[-CENTRAL_TERMS:] print(accumulated)我在其中打印在CENTRAL_TERMS语料库的所有文档中获得最高 tf-idf 分数的单词。但是,我也想MOST_REPEATED_TERMS从语料库的所有文档中获取单词。这些是具有最高 tf 分数的单词。我知道我可以通过简单地使用来获得CountVectorizer,但我只想使用TfidfVectorizer(为了不先执行vectorizer.fit_transform(corpus)for the TfidfVectorizer,然后执行vectorizer.fit_transform(corpus)for the CountVectorizer。我也知道我可以先使用CountVectorizer(获得 tf 分数)然后使用TfidfTransformer(获得tf-idf 分数)。但是,我认为必须有办法只使用TfidfVectorizer.让我知道是否有办法做到这一点(欢迎提供任何信息)。
2 回答
隔江千里
TA贡献1906条经验 获得超10个赞
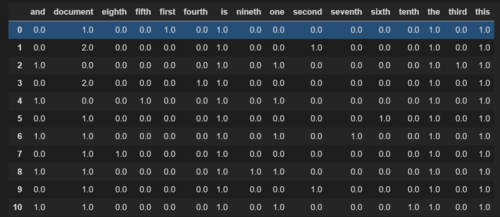
默认情况下,将和相乘后TfidfVectorizer进行l2归一化。因此,当您拥有. 参考这里和这里tfidfnorm='l2'
如果您可以在没有规范的情况下工作,那么有一个解决方案。
import scipy.sparse as sp
import pandas as pd
vectorizer = TfidfVectorizer(norm=None)
X = vectorizer.fit_transform(corpus)
features = vectorizer.get_feature_names()
n = len(features)
inverse_idf = sp.diags(1/vectorizer.idf_,
offsets=0,
shape=(n, n),
format='csr',
dtype=np.float64).toarray()
pd.DataFrame(X*inverse_idf,
columns=features)
喵喵时光机
TA贡献1846条经验 获得超7个赞
你可以像这样完成你的工作
from sklearn.feature_extraction.text import TfidfVectorizer
corpus = [
'This is the first document.',
'This document is the second document.',
'And this is the third one.',
'This document is the fourth document.',
'And this is the fifth one.',
'This document is the sixth.',
'And this is the seventh one document.',
'This document is the eighth.',
'And this is the nineth one document.',
'This document is the second.',
'And this is the tenth one document.',
]
#define the vectorization model
vectorize = TfidfVectorizer (max_features=2500, min_df=0.1, max_df=0.8)
#pass the corpus into the defined vectorizer
vector_texts = vectorize.fit_transform(corpus).toarray()
vector_texts
您必须更改max_features, min_df, max_df值才能最适合您的模型。在我的情况下
out[1]:
array([[0. , 0. , 0. ],
[0. , 0. , 1. ],
[0.70710678, 0.70710678, 0. ],
[0. , 0. , 0. ],
[0.70710678, 0.70710678, 0. ],
[0. , 0. , 0. ],
[0.70710678, 0.70710678, 0. ],
[0. , 0. , 0. ],
[0.70710678, 0.70710678, 0. ],
[0. , 0. , 1. ],
[0.70710678, 0.70710678, 0. ]])
添加回答
举报
0/150
提交
取消