我正在尝试在大型数据集上使用全息视图创建交互式图形。下面是一个名为trackData.cvs的数据文件示例Event Time ID Venue Javeline 11:25:21:012345 JVL DomeShot pot 11:25:22:778929 SPT Dome4x4 11:25:21:993831 FOR Track4x4 11:25:22:874293 FOR TrackShot pot 11:25:21:087822 SPT DomeJaveline 11:25:23:878792 JVL DomeLong Jump 11:25:21:892902 LJP AquaticLong Jump 11:25:22:799422 LJP Aquatic这就是我读取数据并绘制散点图的方式。trackData = pd.read_csv('trackData.csv')scatter = hv.Scatter(trackData, 'Time', 'ID')scatter因为这个数据集非常大,散点图的放大和缩小非常慢,希望加快这个过程。我研究并发现了在大型数据集上推荐的全息视图抽取,但我不知道如何在上面的代码中使用。我尝试过的大多数情况似乎都会引发错误。另外,有没有办法确保将时间列转换为微量?在此先感谢您的帮助
2 回答
婷婷同学_
TA贡献1844条经验 获得超8个赞
Datashader 确实不处理此处使用的分类轴,但这与其说是软件的限制,不如说是我的想象——它应该如何处理它们?Datashader 散点图 (Canvas.points) 适用于位于连续索引 2D 平面上的大量点。这样的图近似于 2D 概率分布函数,累积每个像素的点以显示该区域的密度,并揭示像素之间的空间模式。
分类轴不具有与连续数值轴相同的属性,因为相邻值之间没有空间关系。特别是在这种情况下,ID 字段的排序没有明显的意义(它似乎是体育赛事类型的字母代码),所以我看不出像 Datashader 那样累积每个像素的 ID 值有任何意义设计做的。即使您将 ID 转换为数字,您也只会得到看似随机的噪声(如果 ID 值比垂直像素多),或者会出现一系列参差不齐的线条(如果 ID 值比像素少)。
在这里,也许只有几十个左右的唯一 ID 值,但有很多很多次测量?在这种情况下,大多数人会使用每个 ID 的框、小提琴、直方图或脊图来查看每个 ID 值的值分布。Datashader 点图是一个 2D 直方图,但如果一个轴是分类的,那么您实际上是在处理一组 1D 直方图,而不是单个组合的 2D 直方图,所以如果您想要的话,只需使用直方图。
如果您确实想尝试将每个 ID 的所有点绘制为原始点,您可以使用https://examples.pyviz.org/iex_trading/IEX_stocks.html中的垂直尖峰事件来做到这一点。您还可以添加一些垂直抖动,然后使用 Datashader,但这不是目前直接支持的东西,并且它没有普通 Datashader 绘图所做的明确数学解释(就近似密度函数而言)。
慕娘9325324
TA贡献1783条经验 获得超5个赞
的缺点decimate()是它会降低您的数据点的采样率。
我认为你需要datashader()这里,但 datashader 不喜欢这ID是一个分类变量而不是一个数值。
因此,一个解决方案可能是将您的分类变量转换为数字代码。有关hvPlot(我更喜欢)和HoloViews ,请参见下面的
代码示例:
import io
import pandas as pd
import hvplot.pandas
import holoviews as hv
# dynspread is for making point sizes larger when using datashade
from holoviews.operation.datashader import datashade, dynspread
# sample data
text = """
Event Time ID Venue
Javeline 11:25:21:012345 JVL Dome
Shot pot 11:25:22:778929 SPT Dome
4x4 11:25:21:993831 FOR Track
4x4 11:25:22:874293 FOR Track
Shot pot 11:25:21:087822 SPT Dome
Javeline 11:25:23:878792 JVL Dome
Long Jump 11:25:21:892902 LJP Aquatic
Long Jump 11:25:22:799422 LJP Aquatic
"""
# create dataframe and parse time
df = pd.read_csv(io.StringIO(text), sep='\s{2,}', engine='python')
df['Time'] = pd.to_datetime(df['Time'], format='%H:%M:%S:%f')
df = df.set_index('Time').sort_index()
# get a column that converts categorical id's to numerical id's
df['ID'] = pd.Categorical(df['ID'])
df['ID_code'] = df['ID'].cat.codes
# use this to overwrite numerical yticks with categorical yticks
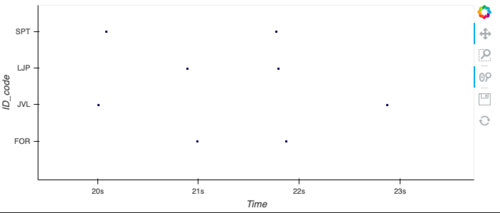
yticks=[(0, 'FOR'), (1, 'JVL'), (2, 'LJP'), (3, 'SPT')]
# this is the hvplot solution: set datashader=True
df.hvplot.scatter(
x='Time',
y='ID_code',
datashade=True,
dynspread=True,
padding=0.05,
).opts(yticks=yticks)
# this is the holoviews solution
scatter = hv.Scatter(df, kdims=['Time'], vdims=['ID_code'])
dynspread(datashade(scatter)).opts(yticks=yticks, padding=0.05)
有关数据着色器和抽取的更多信息: http ://holoviews.org/user_guide/Large_Data.html
结果图:
添加回答
举报
0/150
提交
取消