我正在尝试从音频(.wav文件)中提取MFCC功能,我已经尝试过,但它们给出了完全不同的结果:python_speech_featureslibrosaaudio, sr = librosa.load(file, sr=None)# librosahop_length = int(sr/100)n_fft = int(sr/40)features_librosa = librosa.feature.mfcc(audio, sr, n_mfcc=13, hop_length=hop_length, n_fft=n_fft)# psffeatures_psf = mfcc(audio, sr, numcep=13, winlen=0.025, winstep=0.01)情节本身更接近librosa的情节,但比例更接近python_speech_features。(请注意,这里我计算了80个mel条柱并取了前13个;如果我只用13个箱子进行计算,结果看起来也大不相同)。代码如下:stfts = tf.signal.stft(audio, frame_length=n_fft, frame_step=hop_length, fft_length=512)spectrograms = tf.abs(stfts)num_spectrogram_bins = stfts.shape[-1]lower_edge_hertz, upper_edge_hertz, num_mel_bins = 80.0, 7600.0, 80linear_to_mel_weight_matrix = tf.signal.linear_to_mel_weight_matrix( num_mel_bins, num_spectrogram_bins, sr, lower_edge_hertz, upper_edge_hertz)mel_spectrograms = tf.tensordot(spectrograms, linear_to_mel_weight_matrix, 1)mel_spectrograms.set_shape(spectrograms.shape[:-1].concatenate(linear_to_mel_weight_matrix.shape[-1:]))log_mel_spectrograms = tf.math.log(mel_spectrograms + 1e-6)features_tf = tf.signal.mfccs_from_log_mel_spectrograms(log_mel_spectrograms)[..., :13]features_tf = np.array(features_tf).T我想我的问题是:哪个输出更接近MFCC的实际样子?
2 回答
繁星coding
TA贡献1797条经验 获得超4个赞
这里至少有两个因素可以解释为什么你会得到不同的结果:
mel尺度没有单一的定义。 实现两种方式:Slaney和HTK。其他包可能会并且将使用不同的定义,从而导致不同的结果。话虽如此,整体情况应该是相似的。这就引出了第二个问题...
Librosapython_speech_features默认情况下,将能量作为第一个(索引零)系数(默认情况下),这意味着当您要求例如13 MFCC时,您实际上得到12 + 1。appendEnergyTrue
换句话说,您没有比较13对13的系数,而是13对12的系数。能量可以具有不同的量级,因此由于不同的色标,会产生完全不同的图像。librosapython_speech_features
现在,我将演示这两个模块如何产生类似的结果:
import librosa
import python_speech_features
import matplotlib.pyplot as plt
from scipy.signal.windows import hann
import seaborn as sns
n_mfcc = 13
n_mels = 40
n_fft = 512
hop_length = 160
fmin = 0
fmax = None
sr = 16000
y, sr = librosa.load(librosa.util.example_audio_file(), sr=sr, duration=5,offset=30)
mfcc_librosa = librosa.feature.mfcc(y=y, sr=sr, n_fft=n_fft,
n_mfcc=n_mfcc, n_mels=n_mels,
hop_length=hop_length,
fmin=fmin, fmax=fmax, htk=False)
mfcc_speech = python_speech_features.mfcc(signal=y, samplerate=sr, winlen=n_fft / sr, winstep=hop_length / sr,
numcep=n_mfcc, nfilt=n_mels, nfft=n_fft, lowfreq=fmin, highfreq=fmax,
preemph=0.0, ceplifter=0, appendEnergy=False, winfunc=hann)
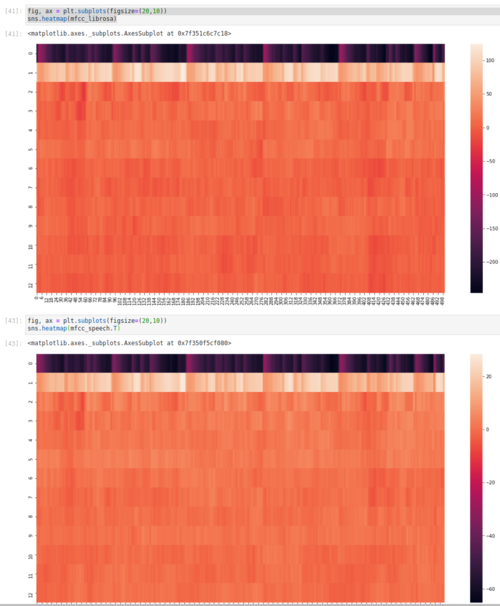
如您所见,比例不同,但整体情况看起来非常相似。请注意,我必须确保传递给模块的许多参数是相同的。
12345678_0001
TA贡献1802条经验 获得超5个赞
这就是那种让我彻夜难眠的东西。这个答案是正确的(而且非常有用!)但并不完整,因为它没有解释两种方法之间的巨大差异。我的答案增加了一个重要的额外细节,但仍然无法实现完全匹配。
正在发生的事情很复杂,最好用下面的冗长代码块来解释,该代码块与另一个包进行比较。librosapython_speech_featurestorchaudio
首先,请注意torchaudio的实现有一个参数,其默认值(False)模仿librosa实现,但如果设置为True将模仿python_speech_features。在这两种情况下,结果仍然不准确,但相似之处是显而易见的。
log_mels其次,如果你深入研究torchaudio实现的代码,你会看到一个注释,即默认值不是“教科书实现”(torchaudio的话,但我信任他们),而是为Librosa兼容性而提供的;火炬音频中从一个切换到另一个的关键操作是:
mel_specgram = self.MelSpectrogram(waveform)
if self.log_mels:
log_offset = 1e-6
mel_specgram = torch.log(mel_specgram + log_offset)
else:
mel_specgram = self.amplitude_to_DB(mel_specgram)
第三,你会非常合理地想知道你是否可以强迫librosa正确行动。答案是肯定的(或者至少是“它看起来像它”),直接获取mel频谱图,取它的基本对数,并使用它,而不是原始样本,作为librosa mfcc函数的输入。有关详细信息,请参阅下面的代码。
最后,要小心,如果您使用此代码,请检查查看不同功能时发生的情况。第 0 个特征仍然具有严重的无法解释的偏移,并且较高的特征往往会彼此远离。这可能很简单,比如引擎盖下的不同实现或略有不同的数字稳定性常数,或者它可能是可以通过微调来修复的东西,比如选择填充,或者可能是某个地方的分贝转换中的引用。我真的不知道。
下面是一些示例代码:
import librosa
import python_speech_features
import matplotlib.pyplot as plt
from scipy.signal.windows import hann
import torchaudio.transforms
import torch
n_mfcc = 13
n_mels = 40
n_fft = 512
hop_length = 160
fmin = 0
fmax = None
sr = 16000
melkwargs={"n_fft" : n_fft, "n_mels" : n_mels, "hop_length":hop_length, "f_min" : fmin, "f_max" : fmax}
y, sr = librosa.load(librosa.util.example_audio_file(), sr=sr, duration=5,offset=30)
# Default librosa with db mel scale
mfcc_lib_db = librosa.feature.mfcc(y=y, sr=sr, n_fft=n_fft,
n_mfcc=n_mfcc, n_mels=n_mels,
hop_length=hop_length,
fmin=fmin, fmax=fmax, htk=False)
# Nearly identical to above
# mfcc_lib_db = librosa.feature.mfcc(S=librosa.power_to_db(S), n_mfcc=n_mfcc, htk=False)
# Modified librosa with log mel scale (helper)
S = librosa.feature.melspectrogram(y=y, sr=sr, n_mels=n_mels, fmin=fmin,
fmax=fmax, hop_length=hop_length)
# Modified librosa with log mel scale
mfcc_lib_log = librosa.feature.mfcc(S=np.log(S+1e-6), n_mfcc=n_mfcc, htk=False)
# Python_speech_features
mfcc_speech = python_speech_features.mfcc(signal=y, samplerate=sr, winlen=n_fft / sr, winstep=hop_length / sr,
numcep=n_mfcc, nfilt=n_mels, nfft=n_fft, lowfreq=fmin, highfreq=fmax,
preemph=0.0, ceplifter=0, appendEnergy=False, winfunc=hann)
# Torchaudio 'textbook' log mel scale
mfcc_torch_log = torchaudio.transforms.MFCC(sample_rate=sr, n_mfcc=n_mfcc,
dct_type=2, norm='ortho', log_mels=True,
melkwargs=melkwargs)(torch.from_numpy(y))
# Torchaudio 'librosa compatible' default dB mel scale
mfcc_torch_db = torchaudio.transforms.MFCC(sample_rate=sr, n_mfcc=n_mfcc,
dct_type=2, norm='ortho', log_mels=False,
melkwargs=melkwargs)(torch.from_numpy(y))
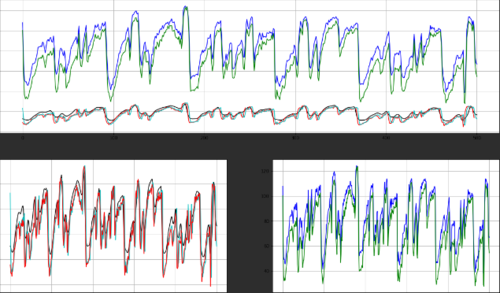
feature = 1 # <-------- Play with this!!
plt.subplot(2, 1, 1)
plt.plot(mfcc_lib_log.T[:,feature], 'k')
plt.plot(mfcc_lib_db.T[:,feature], 'b')
plt.plot(mfcc_speech[:,feature], 'r')
plt.plot(mfcc_torch_log.T[:,feature], 'c')
plt.plot(mfcc_torch_db.T[:,feature], 'g')
plt.grid()
plt.subplot(2, 2, 3)
plt.plot(mfcc_lib_log.T[:,feature], 'k')
plt.plot(mfcc_torch_log.T[:,feature], 'c')
plt.plot(mfcc_speech[:,feature], 'r')
plt.grid()
plt.subplot(2, 2, 4)
plt.plot(mfcc_lib_db.T[:,feature], 'b')
plt.plot(mfcc_torch_db.T[:,feature], 'g')
plt.grid()
老实说,这些实现都没有令人满意:
Python_speech_features采取了一种莫名其妙的奇怪方法,用能量替换第0个特征,而不是用它来增强,并且没有常用的delta实现。
默认情况下,Librosa是非标准的,没有警告,并且缺乏一种明显的方法来增加能量,但在图书馆的其他地方具有高度胜任的delta函数。
Torchaudio将模拟两者,也具有多功能的delta功能,但仍然没有干净,明显的能量获取方式。
添加回答
举报
0/150
提交
取消