我有一个数据帧:df = pd.DataFrame([[1, 2], [1, 3], [4, 6]], columns=['A', 'B']) A B0 1 21 1 32 4 6我想返回一个相同大小的数据帧,其中包含每列的平均值: A B0 2 3.6661 2 3.6662 2 3.666有没有一种简单的方法可以做到这一点?
3 回答
炎炎设计
TA贡献1808条经验 获得超4个赞
这是一个分配:
df.assign(**df.mean())
A B
0 2.0 3.666667
1 2.0 3.666667
2 2.0 3.666667
详
均值可通过以下公式轻松获得:DataFrame.mean
df.mean()
tenor_yrs 14.292857
rates 2.622000
dtype: float64
综上所述,我们可以使用字典解包将现有列替换为结果值。请注意,我们可以使用以下方法将 解压缩到字典中:SeriesSeries**
{**df.mean()}
# {'tenor_yrs': 14.292857142857143, 'rates': 2.622}
假设添加新列的方式是 as ,解压缩使字典键成为函数的参数。并且由于原始数据帧的索引受到尊重,因此会将数据帧的值替换为均值。assigndf.assign(a_given_column=a_value, another_column=some_other_value)df.assign(**df.mean())
慕斯王
TA贡献1864条经验 获得超2个赞
在创建数据帧时,您只能提供一行:
pd.DataFrame(data = [df.mean()], index = df.index)
它提供:
A B
0 2.0 3.666667
1 2.0 3.666667
2 2.0 3.666667
三国纷争
TA贡献1804条经验 获得超7个赞
重新创建数据帧。将平均值系列发送到字典,然后索引定义行数。
pd.DataFrame(df.mean().to_dict(), index=df.index)
# A B
#0 2.0 3.666667
#1 2.0 3.666667
#2 2.0 3.666667
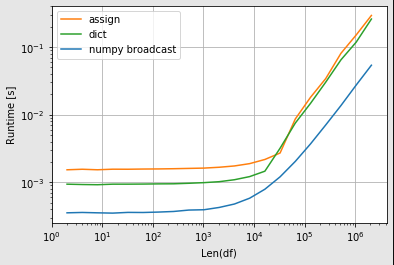
相同的概念,但首先创建完整阵列可以节省大量时间。
pd.DataFrame(np.broadcast_to(df.mean(), df.shape),
index=df.index,
columns=df.columns)
以下是一些时间。当然,这将略微取决于列数,但是当您提供整个数组开始时,您可以看到存在相当大的差异
import perfplot
import pandas as pd
import numpy as np
perfplot.show(
setup=lambda N: pd.DataFrame(np.random.randint(1,100, (N, 5)),
columns=[str(x) for x in range(5)]),
kernels=[
lambda df: pd.DataFrame(np.broadcast_to(df.mean(), df.shape), index=df.index, columns=df.columns),
lambda df: df.assign(**df.mean()),
lambda df: pd.DataFrame(df.mean().to_dict(), index=df.index)
],
labels=['numpy broadcast', 'assign', 'dict'],
n_range=[2 ** k for k in range(1, 22)],
equality_check=np.allclose,
xlabel="Len(df)"
)
添加回答
举报
0/150
提交
取消