我正在Keras中训练一个模型,我使用以下代码保存了所有内容。filepath = "project_model.hdh5"checkpoint = ModelCheckpoint("project_model.hdf5", monitor='loss', verbose=1, save_best_only=False, mode='auto', period=1)然后,我使用以下代码来运行训练。for _ in range(20): for j in range(len(mfcc_data_padded_transposed[j])): batch_input=[mfcc_data_padded_transposed[j]] batch_input = np.array(batch_input) batch_input = batch_input/np.max(batch_input) batch_output = [y_labels_mfcc[j]] batch_output = np.array(batch_output) input_lengths2 = input_lengths_mfcc[j] label_lengths2 = label_lengths_mfcc[j] input_lengths2 = np.array(input_lengths2) label_lengths2 = np.array(label_lengths2) inputs = {'the_input': batch_input, 'the_labels': batch_output, 'input_length': input_lengths2, 'label_length': label_lengths2} outputs = {'ctc': np.zeros([1])} model.fit(inputs, outputs, epochs=1, verbose =1, callbacks=[checkpoint])我做了上面的操作来试验检查点,因为我不确定我是否正确使用它。现在,此培训的学习率为 .001。现在,在运行训练循环一段时间后,如果我决定将学习速率更改为.002,我是否必须运行与模型相关的所有代码(模型结构,然后是优化等)?假设我这样做了,我如何从停止训练时的先前状态加载?另一个问题是,如果我重新启动PC,并使用我之前在这里共享的检查点代码运行jupyter单元格,这会替换以前保存的文件吗?加载保存的文件和权重并从那里恢复训练的理想方法是什么?我问这个问题的原因是,当我遵循Keras文档时,它似乎只是从头开始。
1 回答
杨魅力
TA贡献1811条经验 获得超6个赞
现在,在运行训练循环一段时间后,如果我决定将学习速率更改为.002,我是否必须运行与模型相关的所有代码(模型结构,然后是优化等)?
您可以在训练期间或加载模型后更新学习速率。
请记住,学习速率不属于模型架构,它属于优化器(在模型编译期间分配)。学习速率是一个超参数,用于调节梯度下降期间权重更新的大小(表示如下 alpha):
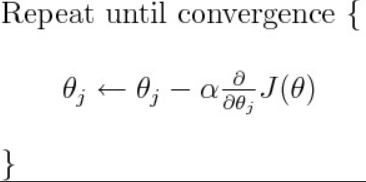
因此,在初始训练之后,您可以加载(保存的)模型,使用新的学习速率更新优化器(并可能将自定义对象分配给编译器),然后继续训练。请记住,在长时间训练模型后更改优化程序本身可能会产生较差的准确性结果,因为您的模型现在必须根据新优化器的权重计算重新校准。
如何从停止训练时的先前状态加载?
在 Keras 中,您可以选择保存/加载整个模型(包括架构、权重、优化器状态,或仅保存权重,或仅保存/加载架构(源)。
要保存/加载整个模型:
from keras.models import load_model
model.save('my_model.h5')
model = load_model('my_model.h5')
要仅保存/加载模型权重:
model.save_weights('my_model_weights.h5')
model.load_weights('my_model_weights.h5')
您还可以在模型加载期间分配自定义对象:
model = load_model(filepath, custom_objects={'loss': custom_loss})
另一个问题是,如果我重新启动PC,并使用我之前在这里共享的检查点代码运行jupyter单元格,这会替换以前保存的文件吗?
取决于检查点中使用的文件路径:“如果文件路径是权重。{epoch:02d}-{val_loss:.2f}.hdf5,则模型检查点将与纪元编号和验证丢失一起保存在文件名中“。因此,如果对文件路径使用唯一格式,则可以避免覆盖以前保存的模型。源
加载保存的文件和权重并从那里恢复训练的理想方法是什么?
例:
# Define model
model = keras.models.Sequential()
model.add(L.InputLayer([None],dtype='int32'))
model.add(L.Embedding(len(all_words),50))
model.add(keras.layers.Bidirectional(L.SimpleRNN(5,return_sequences=True)))
# Define softmax layer for every time step (hence TimeDistributed layer)
stepwise_dense = L.Dense(len(all_words),activation='softmax')
stepwise_dense = L.TimeDistributed(stepwise_dense)
model.add(stepwise_dense)
import keras.backend as K
# compile model with adam optimizer
model.compile('adam','categorical_crossentropy')
# print learning rate
print(f"Model learning rate is: {K.get_value(model.optimizer.lr):.3f}")
# train model
model.fit_generator(generate_batches(train_data), len(train_data)/BATCH_SIZE,
callbacks=[EvaluateAccuracy()], epochs=1)
# save model (weights, architecture, optimizer state)
model.save('my_model.h5')
# delete existing model
del model
结果
Model learning rate is: 0.001
Epoch 1/1
1341/1343 [============================>.] - ETA: 0s - loss: 0.4288
Measuring validation accuracy...
Validation accuracy: 0.93138
from keras.models import load_model
# create new adam optimizer with le-04 learning rate (previous: 1e-03)
adam = keras.optimizers.Adam(lr=1e-4)
# load model
model = load_model('my_model.h5', compile=False)
# compile model and print new learning rate
model.compile(adam, 'categorical_crossentropy')
print(f"Model learning rate is: {K.get_value(model.optimizer.lr):.4f}")
# train model for 3 more epochs with new learning rate
print("Training model: ")
model.fit_generator(generate_batches(train_data),len(train_data)/BATCH_SIZE,
callbacks=[EvaluateAccuracy()], epochs=3,)
结果:
Model learning rate is: 0.0001
Training model:
Epoch 1/3
1342/1343 [============================>.] - ETA: 0s - loss: 0.0885
Measuring validation accuracy...
Validation accuracy: 0.93568
1344/1343 [==============================] - 41s - loss: 0.0885
Epoch 2/3
1342/1343 [============================>.] - ETA: 0s - loss: 0.0768
Measuring validation accuracy...
Validation accuracy: 0.93925
1344/1343 [==============================] - 39s - loss: 0.0768
Epoch 3/3
1343/1343 [============================>.] - ETA: 0s - loss: 0.0701
Measuring validation accuracy...
Validation accuracy: 0.94180
添加回答
举报
0/150
提交
取消