我有一个包含两级列索引的数据框。可重现的数据集。df = pd.DataFrame( [ ['Gaz','Gaz','Gaz','Gaz'], ['X','X','X','X'], ['Y','Y','Y','Y'], ['Z','Z','Z','Z']],columns=pd.MultiIndex.from_arrays([['A','A','C','D'], ['Name','Name','Company','Company']])我想重命名重复的 MultiIndex 列,仅当 level-0 和 level-1 组合重复时。然后在末尾添加一个后缀数字。就像下面的那个。下面是我找到的一个解决方案,但它只适用于单级列索引。class renamer():def __init__(self): self.d = dict()def __call__(self, x): if x not in self.d: self.d[x] = 0 return x else: self.d[x] += 1 return "%s_%d" % (x, self.d[x])df = df.rename(columns=renamer())我认为可以修改上述方法以支持多级情况,但我对 pandas/python 太陌生了。提前致谢。@Datanovice 这是为了向您澄清我需要的输出。我有下面的片段。import pandas as pdimport numpy as npdf = pd.DataFrame( [ ['Gaz','Gaz','Gaz','Gaz'], ['X','X','X','X'], ['Y','Y','Y','Y'], ['Z','Z','Z','Z']],columns=pd.MultiIndex.from_arrays([ ['A','A','C','A'], ['A','A','C','A'], ['Company','Company','Company','Name']]))s = pd.DataFrame(df.columns.tolist())cond = s.groupby(0).cumcount()s = [np.where(cond.gt(0),s[i] + '_' + cond.astype(str),s[i]) for i in range(df.columns.nlevels)]s = pd.DataFrame(s)#print(s)df.columns = pd.MultiIndex.from_arrays(s.values.tolist())print(df)目前的结果是——我需要的是最后一段列索引不应该算作重复,因为“AA-Name”与前两个不一样。
2 回答
萧十郎
TA贡献1815条经验 获得超13个赞
可能是执行此操作的更好方法,但您可以从列中返回数据框并对它们应用条件操作并重新分配它们。
df = pd.DataFrame(
[ ['Gaz','Gaz','Gaz','Gaz'],
['X','X','X','X'],
['Y','Y','Y','Y'],
['Z','Z','Z','Z']],
columns=pd.MultiIndex.from_arrays([['A','A','C','A'],
['Name','Name','Company','Company']])
s = pd.DataFrame(df.columns.tolist())
cond = s.groupby([0,1]).cumcount()
s[0] = np.where(cond.gt(0),s[0] + '_' + cond.astype(str),s[0])
s[1] = np.where(cond.gt(0),s[1] + '_' + cond.astype(str),s[1])
df.columns = pd.MultiIndex.from_frame(s)
print(df)
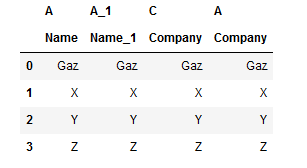
0 A A_1 C D
1 Name Name_1 Company Company
0 Gaz Gaz Gaz Gaz
1 X X X X
2 Y Y Y Y
3 Z Z Z Z
SMILET
TA贡献1796条经验 获得超4个赞
尝试这个 -
arrays = [['A', 'A', 'A', 'A', 'B', 'B', 'B', 'B'],['A', 'A', 'A', 'B', 'C', 'C', 'D', 'D']]
tuples = list(zip(*arrays))
index = pd.MultiIndex.from_tuples(tuples)
df = pd.DataFrame(np.random.randn(3, 8), columns=index)
A B
A A A B C C D D
0 0 0 1 3 1 2 1 4
1 0 1 1 1 1 3 0 1
2 1 1 4 2 3 2 1 4
suffix = pd.DataFrame(df.columns)
suffix['count'] = suffix.groupby(0).cumcount()
suffix['new'] = [((i[0]+'_'+str(j)),(i[1]+'_'+str(j))) for i,j in zip(suffix[0],suffix['count'])]
new_index = pd.MultiIndex.from_tuples(list(suffix['new']))
df.columns = new_index
添加回答
举报
0/150
提交
取消