我有一项仅对 influxDB 进行查询(读/写)的服务。我想对此进行单元测试,但我不知道该怎么做,我读过很多关于模拟的教程。很多涉及像go-sqlmock这样的组件。但由于我使用的是 influxDB,所以无法使用它。我还发现我尝试使用的其他组件(例如goMock或testify)过于复杂。我认为要做的是创建一个存储库层,一个应该实现我运行/测试所需的所有方法的接口,并通过依赖注入传递具体类。我认为这可行,但这是最简单的方法吗?我想到处都有存储库,即使对于小型服务,只是为了它们可测试,似乎是过度设计的。如果需要,我可以给你代码,但我认为我的问题有点理论性多于实际性。这是模拟自定义数据库进行单元测试的最简单方法。
2 回答
aluckdog
TA贡献1847条经验 获得超7个赞
如果目标是验证查询是否有效并实际针对流入执行,则没有针对流入实际执行这些查询的快捷方式。这些通常被认为是“集成”测试。我发现使用 docker-compose,这些测试可以与单元测试一样可靠,并且足够快,可以集成到 CI 中。在 CI 中执行测试使本地工程师能够轻松运行这些测试来验证他们的查询更改。
我想到处都有存储库,即使对于小型服务,只是为了它们可测试,似乎是过度设计的。
我发现这是一个相当两极分化的讨论。测试实现是一种具体的实现,为可靠、可重复的测试铺平了道路,这些测试支持轻松隔离和执行代码的特定组件。
我想对此进行单元测试,但我不知道该怎么做,
我认为这是非常微妙的,IMO 单元测试查询提供了负值。价值来自于使用存储库接口,允许您的单元测试显式配置您将从 influx 收到的响应,以便充分运用您的应用程序代码。这不会提供有关流入的反馈,这就是为什么集成测试对于验证您的应用程序是否可以针对流入进行有效配置、连接和查询至关重要。当您部署应用程序时,这种验证会隐式发生,此时就反馈而言,它比在本地和通过集成测试在 CI 中验证它要昂贵得多。
我创建了一个图表来尝试说明这些差异:
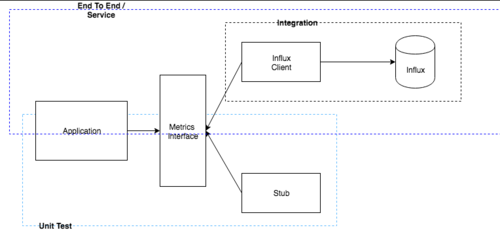
使用存储库的单元测试侧重于您的应用程序代码,并且对与流入有关的任何内容提供很少的反馈/价值。集成测试对于验证您的客户端很有用(可能会扩展到您的应用程序,具体取决于测试的执行位置,但我更喜欢将其绑定到客户端,因为您已经获得了来自接口和调用的静态反馈)。最后,正如 @Markus 指出的那样,从集成测试到 e2e 测试的步骤非常小,并且允许您测试完整的服务。
慕哥6287543
TA贡献1831条经验 获得超10个赞
根据其定义,如果您测试与外部资源的集成,我们谈论的是集成测试,而不是单元测试。所以我们这里有两个问题需要解决。
单元测试
您通常要做的就是拥有一个接受接口的数据访问层,这反过来又很容易模拟,并且您可以对应用程序逻辑进行单元测试。
package main
import (
"errors"
"fmt"
)
var (
values = map[string]string{"foo": "bar", "bar": "baz"}
Expected = errors.New("Expected error")
)
type Getter interface {
Get(name string) (string, error)
}
// ErrorGetter implements Getter and always returns an error to test the error handling code of the caller.
// ofc, you could (and prolly should) use some mocking here in order to be able to test various other cases
type ErrorGetter struct{}
func (e ErrorGetter) Get(name string) (string, error) {
return "", Expected
}
// MapGetter implements Getter and uses a map as its datasource.
// Here you can see that you actually get an advantage: you decouple your logic from the data source,
// making refactoring (and debugging) **much** easier WTSHTF.
type MapGetter struct {
data map[string]string
}
func (m MapGetter) Get(name string) (string, error) {
if v, ok := m.data[name]; ok {
return v, nil
}
return "", fmt.Errorf("No value found for %s", name)
}
type retriever struct {
g Getter
}
func (r retriever) retrieve(name string) (string, error) {
return r.g.Get(name)
}
func main() {
// Assume this is test code. No tests possible on playground ;)
bad := retriever{g: ErrorGetter{}}
s, err := bad.retrieve("baz")
if s != "" || err == nil {
panic("Something went seriously wrong")
}
// Needs to fail as well, as "baz" is not in values
good := retriever{g: MapGetter{values}}
s, err = good.retrieve("baz")
if s != "" || err == nil {
panic("Something went seriously wrong")
}
s, err = good.retrieve("foo")
if s != "bar" || err != nil {
panic("Something went seriously wrong")
}
}
在上面的示例中,我实际上必须实现两个 Getter 来覆盖所有测试用例,因为我无法使用模拟库,但您明白了。
至于过度工程:简单明了,不,这不是过度工程。这就是我个人所说的正确的工艺。从长远来看,习惯它是值得的。也许不是在这个项目中,但在未来的一个项目中。
集成测试
狡猾的。我倾向于做的是在提交之前确保我的查询是正确的;)
在极少数情况下,我确实想在 CI 中验证我的查询,例如,我通常创建一个 Makefile,它反过来启动一个 docker(-compose),它提供我想要集成的内容,然后运行测试。
- 2 回答
- 0 关注
- 291 浏览
添加回答
举报
0/150
提交
取消