给定一个字符串,例如i am a string.我可以使用该包生成该字符串的 n 元语法nltk,其中 n 根据指定范围变化。from nltk import ngrams s = 'i am a string'for n in range(1, 3): for grams in ngrams(s.split(), n): print(grams)给出输出:('i',)('am',)('a',)('string',)('i', 'am')('am', 'a')('a', 'string')有没有办法使用生成的 ngram 的组合来“重建”原始字符串?或者,用下面评论者的话说,有没有一种方法可以将句子分成连续的单词序列,其中每个序列的最大长度为 k(在本例中 k 为 2)。[('i'), ('am'), ('a'), ('string')][('i', 'am'), ('a'), ('string')][('i'), ('am', 'a'), ('string')][('i'), ('am'), ('a', 'string')][('i', 'am'), ('a', 'string')]这个问题与这个问题类似,但又增加了一层复杂性。工作解决方案- 改编自此处。我有一个可行的解决方案,但对于较长的字符串来说它真的很慢。def get_ngrams(s, min_=1, max_=4): token_lst = [] for n in range(min_, max_): for idx, grams in enumerate(ngrams(s.split(), n)): token_lst.append(' '.join(grams)) return token_lst def to_sum_k(s): for len_ in range(1, len(s.split())+1): for i in itertools.permutations(get_ngrams(s), r=len_): if ' '.join(i) == s: print(i)to_sum_k('a b c')
2 回答
温温酱
TA贡献1752条经验 获得超4个赞
编辑:
这个答案基于这样的假设:问题是根据 ngram 重建未知的唯一字符串。对于任何对此问题感兴趣的人,我都会将其保留为活动状态。评论中澄清的实际问题的实际答案可以在这里找到。
编辑结束
一般来说没有。考虑例如情况n = 2和s = "a b a b"。那么你的ngrams将是
[("a"), ("b"), ("a", "b"), ("b", "a")]
然而,在这种情况下生成这组 ngram 的字符串集将是由以下方式生成的所有字符串:
(ab(a|(ab)*a?))|(ba(b|(ba)*b?)
或者n = 2, s = "a b c a b d a", 其中"c"和"d"可以在生成字符串中任意排序。例如“abdabc a”也是一个有效的字符串。此外,还会出现与上述相同的问题,任意数量的字符串都可以生成 ngram 集合。
话虽这么说,有一种方法可以测试一组 ngram 是否唯一标识一个字符串:
将您的字符串集视为非确定性状态机的描述。每个 ngram 可以定义为一个状态链,其中单个字符是转换。作为 ngrams [("a", "b", "c"), ("c", "d"), ("a", "d", "b")] 的示例,我们将构建以下内容状态机:
0 ->(a) 1 ->(b) 2 ->(c) 3
0 ->(c) 3 ->(d) 4
0 ->(a) 1 ->(d) 5 ->(b) 6
现在执行该状态机的确定。如果存在可以从 ngram 重建的唯一字符串,则状态机将具有最长的转换链,该转换链不包含任何循环并包含我们构建原始状态机的所有 ngram。在这种情况下,原始字符串只是该路径的各个状态转换重新连接在一起。否则,存在可以从提供的 ngram 构建的多个字符串。
12345678_0001
TA贡献1802条经验 获得超5个赞
虽然我之前的答案假设问题是根据 ngram 找到未知字符串,但这个答案将处理找到使用 ngram 构造给定字符串的所有方法的问题。
假设允许重复,解决方案相当简单:生成所有可能的数字序列,总和等于原始字符串的长度,且数字不大于n并使用这些序列来创建 ngram 组合:
import numpy
def generate_sums(l, n, intermediate):
if l == 0:
yield intermediate
elif l < 0:
return
else:
for i in range(1, n + 1):
yield from generate_sums(l - i, n, intermediate + [i])
def combinations(s, n):
words = s.split(' ')
for c in generate_sums(len(words), n, [0]):
cs = numpy.cumsum(c)
yield [words[l:u] for (l, u) in zip(cs, cs[1:])]
编辑:正如@norok2
(感谢您的工作)在评论中 所指出的,使用替代的 cumsum 实现似乎比为此用例提供的实现更快。 结束编辑numpy
如果不允许重复,事情就会变得更加棘手。在这种情况下,我们可以使用我之前的答案中定义的非确定性有限自动机,并根据自动机的遍历构建我们的序列:
def build_state_machine(s, n):
next_state = 1
transitions = {}
for ng in ngrams(s.split(' '), n):
state = 0
for word in ng:
if (state, word) not in transitions:
transitions[(state, word)] = next_state
next_state += 1
state = transitions[(state, word)]
return transitions
def combinations(s, n):
transitions = build_state_machine(s, n)
states = [(0, set(), [], [])]
for word in s.split(' '):
new_states = []
for state, term_visited, path, cur_elem in states:
if state not in term_visited:
new_states.append((0, term_visited.union(state), path + [tuple(cur_elem)], []))
if (state, word) in transitions:
new_states.append((transitions[(state, word)], term_visited, path, cur_elem + [word]))
states = new_states
return [path + [tuple(cur_elem)] if state != 0 else path for (state, term_visited, path, cur_elem) in states if state not in term_visited]
作为示例,将为字符串生成以下状态机"a b a":
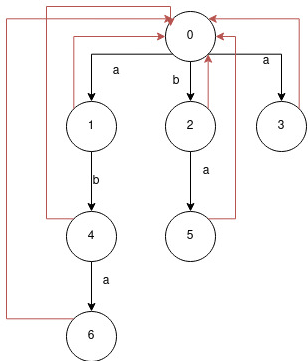
红色连接表示切换到下一个 ngram,需要单独处理(如果在循环中则需要单独处理),因为它们只能遍历一次。
添加回答
举报
0/150
提交
取消