
































































 夜流歌 ·
夜流歌 ·在 TensorFlow 之中使用注意力模型
在之前的学习之中,我们学习了很多的网络模型,比如 CNN、RNN 等基本的网络模型,虽然这些模型是根据人的信息处理方式来进行设计并实现的,但是这些模型都有一些特点,那就是只是会根据输入的数据进行机械地输出。那么我们这节课便要来学习一下更加 “贴近人的信息处理方式的方法”———— 注意力机制。
1. 什么是注意力机制
顾名思义,注意力机制,“Attention”,就是模仿人的注意力来进行网络模型的设计与实现。
我们每个人在日常生活之中,无时无刻不在使用着注意力,比如:
- 我们在看电视的时候会忽略掉电视周围的环境;
- 我们在学习的时候会对书本的注意力集中度较高;
- 我们在听音乐的时候对音乐本身的注意力较高,反而对周围的噪音注意力较小。
在神经网络之中采用注意力可以机制可以通过模仿人类的注意力行为,来对数据之中的重要的细节赋予更高的权重,反而对于一些不重要的细节来赋予较低的权重。
举个例子,如下图所示,有一只手拿着一朵花在以堆草丛之前,那么我们人在观察这种图片的时候,一般会将更多的注意力集中在这朵花和这只手上,而不是将注意力放在背景的草丛中。因此我们要让我们的网络模型学会如何使用注意力机制,从而其实将注意力更多地放在花和手上。

2. 注意力的分类
注意力按照存在的地方大概可以分为四类:
- 空间注意力,就是我们上述图片所表述的注意力,它主要是强调我们在空间之上要注意哪些地方;
- 时间注意力,图片没有时间注意力,像音频、视频等连续的数据会使用到时间注意力,表示我们在哪个时间段要提高注意力;
- 通道注意力,众所周知,一般的图片包含三个通道:R、G、B,那么通道注意力就是强调在哪个通道之上给予更高的注意力权重;
- 混合注意力,使用上述两种及其以上的注意力,从而达到更好的效果。
在接下来的例子之中,我们会以通道注意力为例子进行演示如何使用注意力机制。
3. 通道上的注意力机制的实现 ——SELayer
SENet 是一个使用通道注意力的模型,它可以对不同的通道求得不同的权重,进而对他们加权,从而实现通道域上的注意力机制。
SELayer 是 SENet 之中的一个网络层,是 SENet 的核心部分,我们可以将其单独摘出来作为一个通道域上的注意力。
SELayer 的网络图如下图所示:
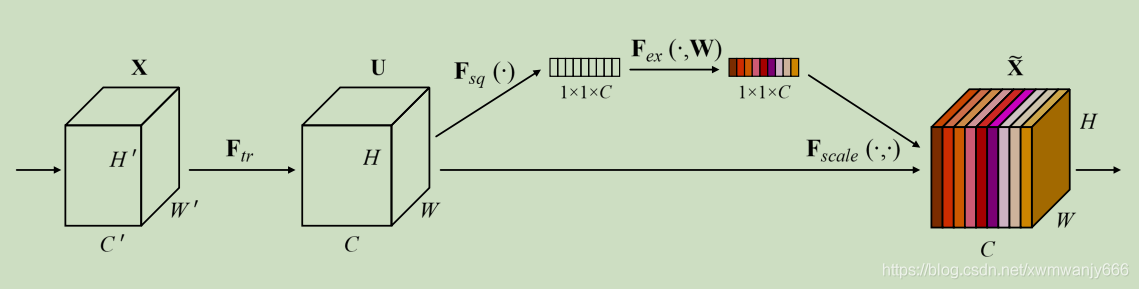
在上图之中,我们可以发现,对于已经求得的特征(第二个正方体),SELayer 首先使用卷积网络,将其变为 1 * 1 * C 的特征,然后对于该特征进行一定的处理,处理结束之后的每一个通道的一个数字就代表着原特征图的相应通道的权重。最后我们将求得的权重乘到原特征上去便可以得到加权后的特征,这就表示我们已经在通道域上实现了注意力机制。
在 TensorFlow 之中,我们可以通过继承 tf.keras.laysers.Layer 类来定义自己的网络层,于是我们可以将我们的 SELayer 定义为如下:
class SELayer(tf.keras.Model):
def __init__(self, filters, reduction=16):
super(SELayer, self).__init__()
self.filters = filters
self.reduction = reduction
self.GAP = tf.keras.layers.GlobalAveragePooling2D()
self.FC = tf.keras.models.Sequential([
tf.keras.layers.Dense(units=self.filters // self.reduction, input_shape=(self.filters, )),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Activation('relu'),
tf.keras.layers.Dense(units=filters),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Activation('sigmoid')
])
self.Multiply = tf.keras.layers.Multiply()
def call(self, inputs, training=None, mask=None):
x = self.GAP(inputs)
x = self.FC(x)
x = self.Multiply([x, inputs])
return x
在初始化的函数之中,我们定义了我们需要用到的网络层以及相应的结构,通过 call 函数与初始化函数,我们可以得到该层的执行方式:
- 首先数据会经过一个全局平均池化,来变成一个 1* 1 * c 形状的特征;
- 然后经过我们定义的 FC 层,来计算出一个 1 * 1 * c 的权重,其中 FC 层包括;
- 一个全连接层;
- 一个 DropOut 层用于避免过拟合;
- 一个批次正则化层,这是便于更好地进行训练;
- 一个 relu 激活函数;
- 另外一个全连接层;
- 另外一个 DropOut 层;
- 另外一个批次正则化层;
- 一个 sigmoid 激活函数;
- 在得到权重之后,我们便使用矩阵的乘法,将原来的输出与权重相乘,从而得到在最终的结果。
4. 使用通道注意力机制的完整代码
在定义了我们的注意力层之后,我们便可以着手将注意力机制应用到我们之前的任务之中,在这里我们以以前学习过的猫和狗分类为例子,添加我们的 Attention 机制,并且查看最终的结果:
import tensorflow as tf
import os
import matplotlib.pyplot as plt
dataset_url = 'https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip'
path_download = os.path.dirname(tf.keras.utils.get_file('cats_and_dogs.zip', origin=dataset_url, extract=True))
train_dataset_dir = path_download + '/cats_and_dogs_filtered/train'
valid_dataset_dir = path_download + '/cats_and_dogs_filtered/validation'
BATCH_SIZE = 64
TRAIN_NUM = 2000
VALID_NUM = 1000
EPOCHS = 15
Height = 128
Width = 128
train_image_generator = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1./255)
valid_image_generator = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1./255)
train_data_generator = train_image_generator.flow_from_directory(batch_size=BATCH_SIZE,
directory=train_dataset_dir,
shuffle=True,
target_size=(Height, Width),
class_mode='binary')
valid_data_generator = valid_image_generator.flow_from_directory(batch_size=BATCH_SIZE,
directory=valid_dataset_dir,
shuffle=True,
target_size=(Height, Width),
class_mode='binary')
class SELayer(tf.keras.Model):
def __init__(self, filters, reduction=16):
super(SELayer, self).__init__()
self.filters = filters
self.reduction = reduction
self.GAP = tf.keras.layers.GlobalAveragePooling2D()
self.FC = tf.keras.models.Sequential([
tf.keras.layers.Dense(units=self.filters // self.reduction, input_shape=(self.filters, )),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Activation('relu'),
tf.keras.layers.Dense(units=filters),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Activation('sigmoid')
])
self.Multiply = tf.keras.layers.Multiply()
def call(self, inputs, training=None, mask=None):
x = self.GAP(inputs)
x = self.FC(x)
x = self.Multiply([x, inputs])
return x
def build_graph(self, input_shape):
input_shape_without_batch = input_shape[1:]
self.build(input_shape)
inputs = tf.keras.Input(shape=input_shape_without_batch)
_ = self.call(inputs)
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(16, 3, padding='same', activation='relu',
input_shape=(Height, Width ,3)),
tf.keras.layers.MaxPooling2D(),
SELayer(16),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Conv2D(32, 3, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(),
SELayer(32),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Conv2D(64, 3, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(),
SELayer(64),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Flatten(),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(1)
])
model.compile(optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
model.summary()
history = model.fit_generator(
train_data_generator,
steps_per_epoch=TRAIN_NUM // BATCH_SIZE,
epochs=EPOCHS,
validation_data=valid_data_generator,
validation_steps=VALID_NUM // BATCH_SIZE)
acc = history.history['accuracy']
loss=history.history['loss']
val_acc = history.history['val_accuracy']
val_loss=history.history['val_loss']
epochs_ran = range(EPOCHS)
plt.plot(epochs_ran, acc, label='Train Acc')
plt.plot(epochs_ran, val_acc, label='Valid Acc')
plt.show()
plt.plot(epochs_ran, loss, label='Train Loss')
plt.plot(epochs_ran, val_loss, label='Valid Loss')
plt.show()
通过运行代码,我们可以得到运行的结果:
Found 2000 images belonging to 2 classes.
Found 1000 images belonging to 2 classes.
Model: "sequential_7"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_4 (Conv2D) (None, 128, 128, 16) 448
_________________________________________________________________
max_pooling2d_4 (MaxPooling2 (None, 64, 64, 16) 0
_________________________________________________________________
se_layer_3 (SELayer) (None, 64, 64, 16) 117
_________________________________________________________________
dropout_8 (Dropout) (None, 64, 64, 16) 0
_________________________________________________________________
conv2d_5 (Conv2D) (None, 64, 64, 32) 4640
_________________________________________________________________
max_pooling2d_5 (MaxPooling2 (None, 32, 32, 32) 0
_________________________________________________________________
se_layer_4 (SELayer) (None, 32, 32, 32) 298
_________________________________________________________________
dropout_11 (Dropout) (None, 32, 32, 32) 0
_________________________________________________________________
conv2d_6 (Conv2D) (None, 32, 32, 64) 18496
_________________________________________________________________
max_pooling2d_6 (MaxPooling2 (None, 16, 16, 64) 0
_________________________________________________________________
se_layer_5 (SELayer) (None, 16, 16, 64) 852
_________________________________________________________________
dropout_14 (Dropout) (None, 16, 16, 64) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 16384) 0
_________________________________________________________________
dropout_15 (Dropout) (None, 16384) 0
_________________________________________________________________
dense_14 (Dense) (None, 512) 8389120
_________________________________________________________________
dropout_16 (Dropout) (None, 512) 0
_________________________________________________________________
dense_15 (Dense) (None, 1) 513
=================================================================
Total params: 8,414,484
Trainable params: 8,414,246
Non-trainable params: 238
_________________________________________________________________
Epoch 1/15
31/31 [==============================] - 56s 2s/step - loss: 0.7094 - accuracy: 0.5114 - val_loss: 0.6931 - val_accuracy: 0.5310
Epoch 2/15
31/31 [==============================] - 48s 2s/step - loss: 0.6930 - accuracy: 0.4990 - val_loss: 0.6927 - val_accuracy: 0.5869
......
Epoch 14/15
31/31 [==============================] - 54s 2s/step - loss: 0.6174 - accuracy: 0.6348 - val_loss: 0.6309 - val_accuracy: 0.7240
Epoch 15/15
31/31 [==============================] - 47s 2s/step - loss: 0.6030 - accuracy: 0.6446 - val_loss: 0.6195 - val_accuracy: 0.7565
于是我们可以发现,我们的模型最终达到了 75% 的准确率,大家可以和之前的模型的结果做一个比较。
同时大家也可以根据自己对 CNN 和 MaxPooling 的理解来调整模型以及相应的参数,从而达到一个更好的效果。
5. 小结
通过这节课的学习,我们了解了什么是注意力机制,并且了解了注意力的分类(空间、时间、通道、混合),并且手动实现了一个通道域的注意力机制,并且最后进行了实现。

 2026 imooc.com All Rights Reserved |
2026 imooc.com All Rights Reserved |