
































































 夜流歌 ·
夜流歌 ·过拟合问题
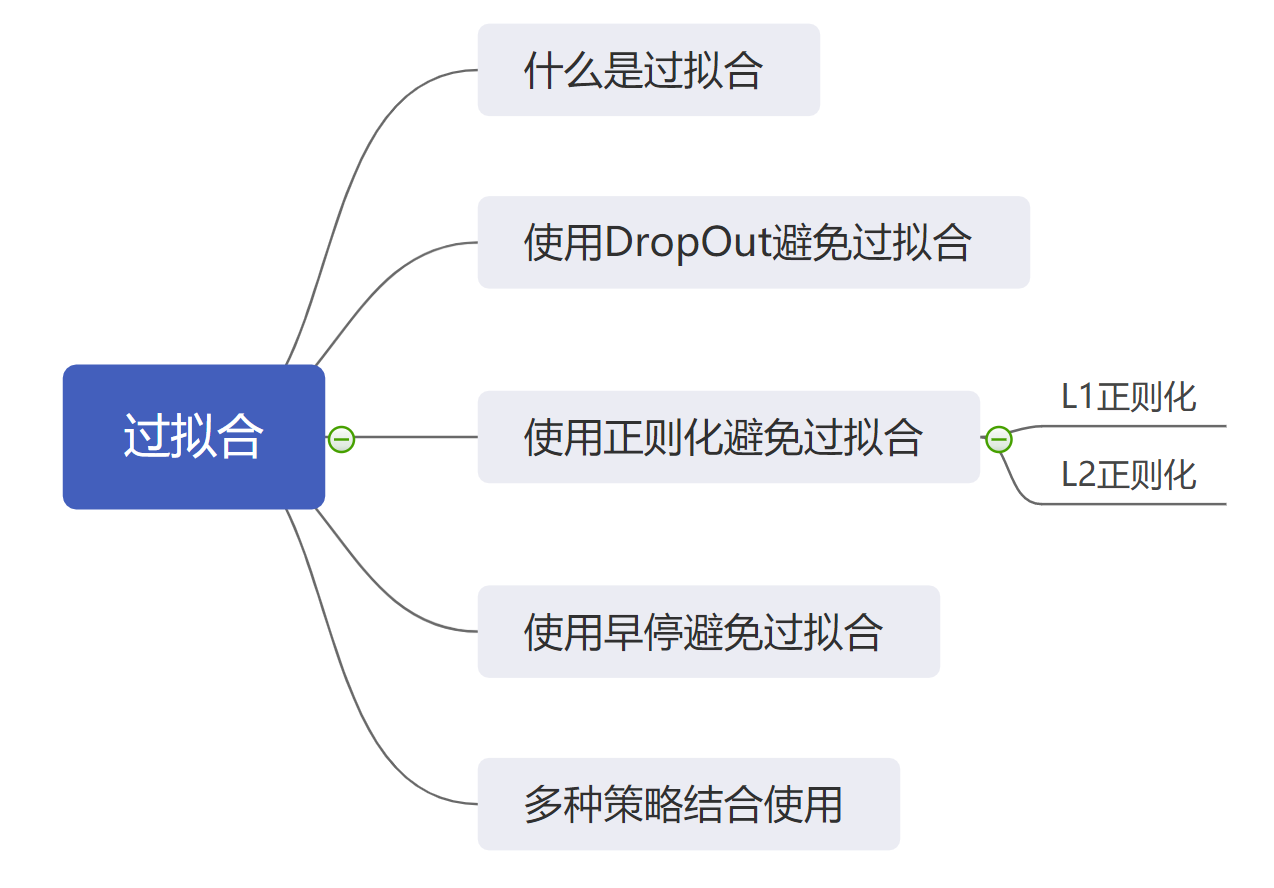
在我们之前的学习之中,我们或多或少都会遇到一些训练时间的问题。比如“训练时间越长是不是最后的结果就会越好?”等问题。答案当然是否定的,这是因为在训练的过程之中会遭遇到“过拟合”的问题,这是一种随着训练时间不断加长而产生的问题,那么这节课我们就来学习一下什么是过拟合,同时了解一下 TensorFlow 之中的避免过拟合的简单的方法。
这节课之中,我们使用之前学习过的猫狗分类的例子进行示例演示。
1. 什么是过拟合
过拟合,简单来说就是“学习过度”,也就是说模型在训练集合上的精度越来越高,但是却在测试集上的精度越来越低的情况。
这是因为网络模型在训练集合上学习到了太多的“没用的”特征,以至于模型的泛化能力下降。如下面两幅图所示,其中蓝色代表训练集合上的指标,而黄色代表测试集合上的指标。
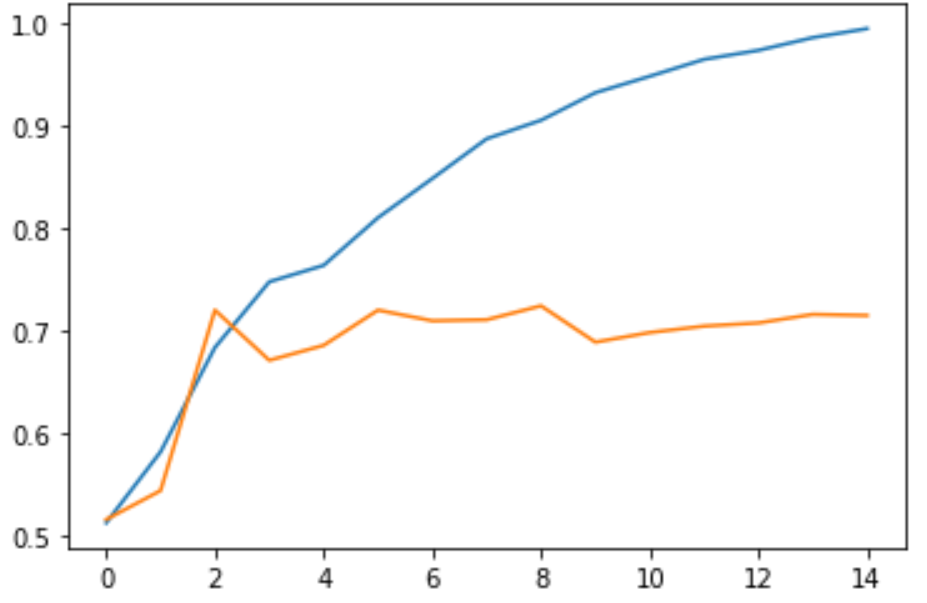
改图为准确率的曲线,通过上图我们可以看到,随着不断地训练,模型在训练集合上的准确率逐渐逼近100%,而训练集合上的准确率却一直在70%徘徊。
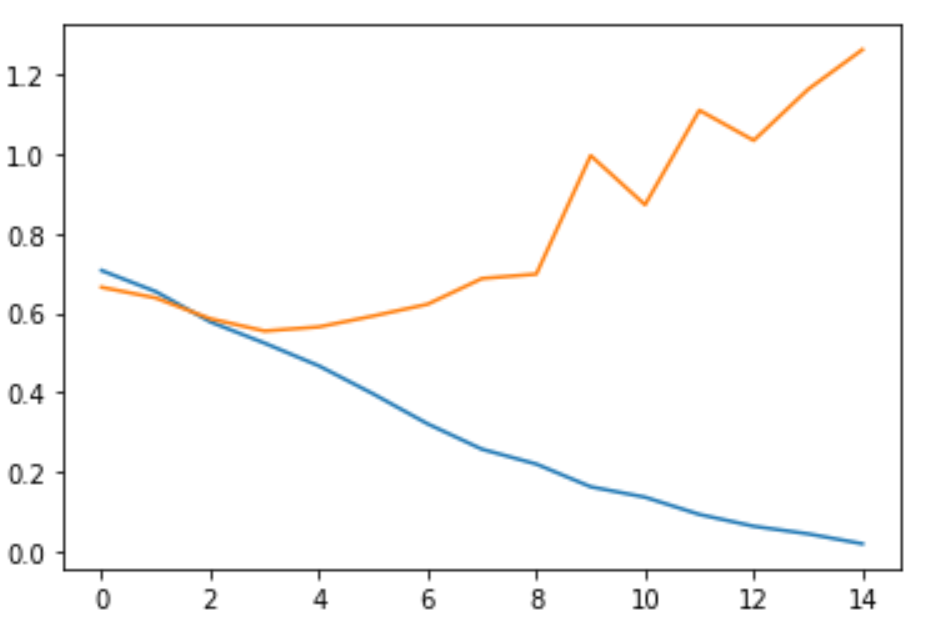
改图为损失 Loss 的曲线,通过上图我们可以看到,随着不断地训练,模型在训练集合上的损失逐渐逼近0,而训练集合上的损失却在第三个迭代之后不断升高。
那么接下来我们就来学习一下如何在 TensorFlow 之中简单地避免过拟合。这节课之中,我们要学习的方法有三种:
- 使用 DropOut ;
- 使用正则化;
- 使用早停策略。
值得注意的是,上述图表已经在之前的课程使用 tf.keras 进行图片分类之中给出,它的完整代码为:
import tensorflow as tf
import os
import matplotlib.pyplot as plt
# 获取数据
dataset_url = 'https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip'
path_download = os.path.dirname(tf.keras.utils.get_file('cats_and_dogs.zip', origin=dataset_url, extract=True))
# 获得数据的路径
train_dataset_dir = path_download + '/cats_and_dogs_filtered/train'
valid_dataset_dir = path_download + '/cats_and_dogs_filtered/validation'
# 定义相关的超参数
BATCH_SIZE = 64
TRAIN_NUM = 2000
VALID_NUM = 1000
EPOCHS = 15
Height = 128
Width = 128
# 创建训练集与测试集的迭代器
train_image_generator = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1./255)
valid_image_generator = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1./255)
train_data_generator = train_image_generator.flow_from_directory(batch_size=BATCH_SIZE,
directory=train_dataset_dir,
shuffle=True,
target_size=(Height, Width),
class_mode='binary')
valid_data_generator = valid_image_generator.flow_from_directory(batch_size=BATCH_SIZE,
directory=valid_dataset_dir,
shuffle=True,
target_size=(Height, Width),
class_mode='binary')
# 定义一个线性模型
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(16, 3, padding='same', activation='relu',
input_shape=(Height, Width ,3)),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(32, 3, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(64, 3, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dense(1)
])
# 编译模型
model.compile(optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
model.summary()
# 训练模型
history = model.fit_generator(
train_data_generator,
steps_per_epoch=TRAIN_NUM // BATCH_SIZE,
epochs=EPOCHS,
validation_data=valid_data_generator,
validation_steps=VALID_NUM // BATCH_SIZE)
# 获取训练的记录
acc = history.history['accuracy']
loss=history.history['loss']
val_acc = history.history['val_accuracy']
val_loss=history.history['val_loss']
epochs_ran = range(EPOCHS)
# 绘制训练过程中的各种指标
plt.plot(epochs_ran, acc, label='Train Acc')
plt.plot(epochs_ran, val_acc, label='Valid Acc')
plt.show()
plt.plot(epochs_ran, loss, label='Train Loss')
plt.plot(epochs_ran, val_loss, label='Valid Loss')
plt.show()
2. 使用 DropOut
在产生过拟合的原因之中,一个重要的原因就是“网络参数过多”,也就是网络模型的学习能力过强,从而导致它会学习到很多没用的信息,从而导致过拟合情况的发生。而使用 DropOut 就是在一定程度上降低网络参数,降低它的学习能力。
它的实现比较简单:
tf.keras.layers.Dropout(frac)
可以看出,它是一个网络层,它的参数 frac 是一个 0 到 1 的小数,该网络层会按照 frac 的概率随机丢掉一些参数,从而达到降低网络参数数量的目的。在使用的过程之中,我们只需要将该网络层嵌入到模型的需要 DropOut 的网络层之前即可。
于是我们可以将上述的网络模型修改为:
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(16, 3, padding='same', activation='relu',
input_shape=(Height, Width ,3)),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Conv2D(32, 3, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Conv2D(64, 3, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Flatten(),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(1)
])
然后我们运行代码,便可以得到网络的结构为:
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_3 (Conv2D) (None, 128, 128, 16) 448
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 (None, 64, 64, 16) 0
_________________________________________________________________
dropout (Dropout) (None, 64, 64, 16) 0
_________________________________________________________________
conv2d_4 (Conv2D) (None, 64, 64, 32) 4640
_________________________________________________________________
max_pooling2d_4 (MaxPooling2 (None, 32, 32, 32) 0
_________________________________________________________________
dropout_1 (Dropout) (None, 32, 32, 32) 0
_________________________________________________________________
conv2d_5 (Conv2D) (None, 32, 32, 64) 18496
_________________________________________________________________
max_pooling2d_5 (MaxPooling2 (None, 16, 16, 64) 0
_________________________________________________________________
dropout_2 (Dropout) (None, 16, 16, 64) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 16384) 0
_________________________________________________________________
dropout_3 (Dropout) (None, 16384) 0
_________________________________________________________________
dense_2 (Dense) (None, 512) 8389120
_________________________________________________________________
dropout_4 (Dropout) (None, 512) 0
_________________________________________________________________
dense_3 (Dense) (None, 1) 513
=================================================================
Total params: 8,413,217
Trainable params: 8,413,217
Non-trainable params: 0
然后我们在训练结束后便可以看到模型训练结果的准确率曲线为:
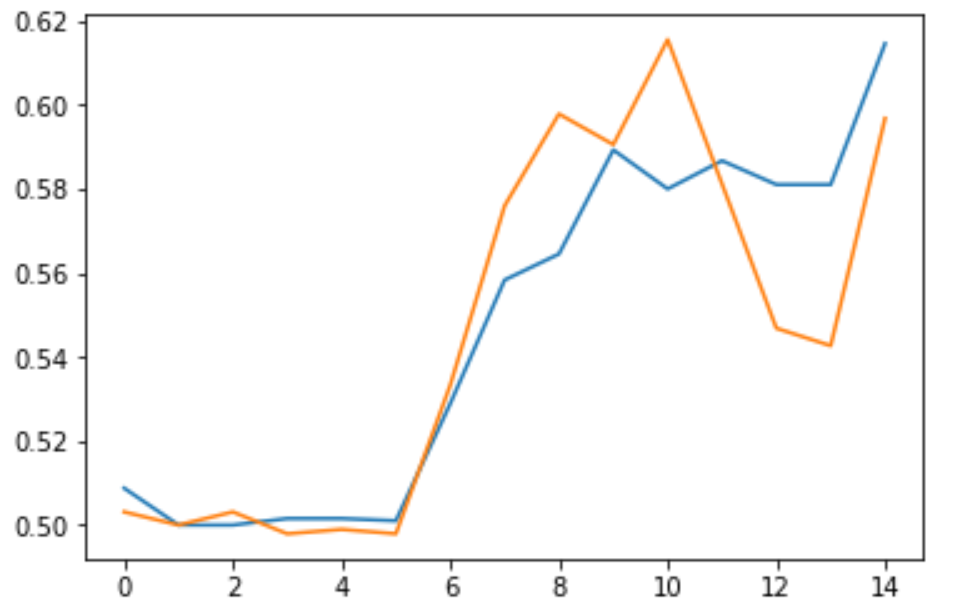
而模型训练结果的损失Loss曲线为:
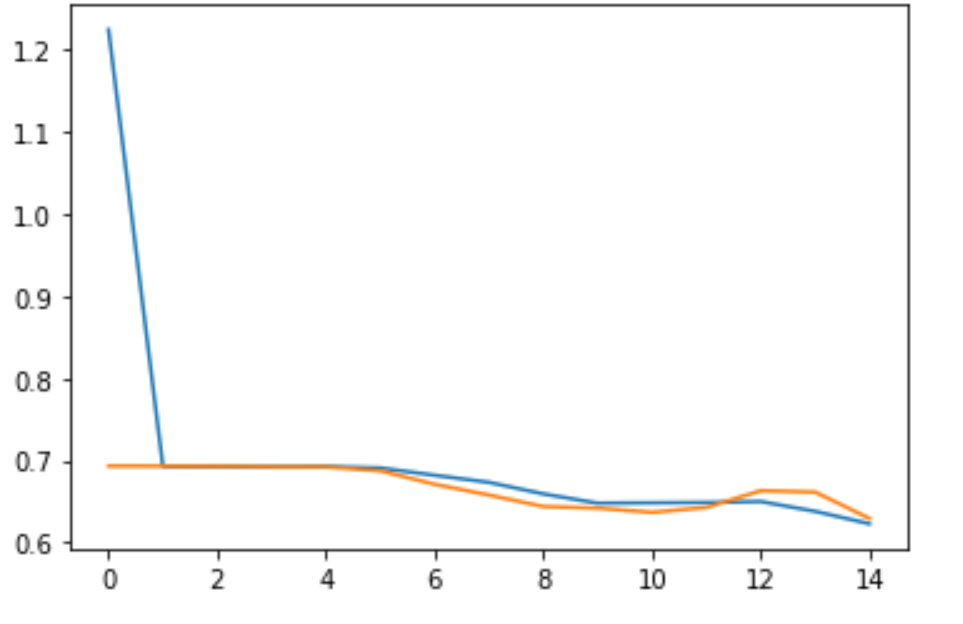
可以看到,与之前的模型相比,我们现在的模型在一定程度上降低了过拟合。对于准确率,它并没有像之前一样保持徘徊,而是和训练集保持了一致;对于损失,它也没有上升,反而是一直处于一个较低的值。
3. 使用正则化
正则化是一种比较高级的防止过拟合产生的方法。它是通过网络的参数来计算网络的“代价”,然后将代价最小化来实现降低网络规模的目的。它主要包括两种方式, L1 正则化与 L2 正则化,这两种方式都涉及到很多的数学原理,因此这里不做过多的展开,我们可以进行一个简单的区分:
- L1 正则化,代价与网络参数成正比;
- L2 正则化,代价与网络参数的平方成正比。
而在实践的过程之中,我们最常使用的就是 L2 正则化。
具体来说,我们可以通过将支持正则化的网络层添加相应的正则化参数即可实现该网络层的正则化。比如对于 Dense 网络层来说,我们可以添加参数:
tf.keras.laysers.Dense(64, kernel_regularizer=tf.keras.regularizers.l2(0.001)),
而其中的 0.001 参数就是“代价”与网络参数的平方成正比的参数。也就是说:
代价 = 0.001 * (网络参数**2)
于是我们可以将我们的模型再次修改为:
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(16, 3, padding='same', activation='relu',
input_shape=(Height, Width ,3),
kernel_regularizer=tf.keras.regularizers.l2(0.001)),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(32, 3, padding='same', activation='relu',
kernel_regularizer=tf.keras.regularizers.l2(0.001)),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(64, 3, padding='same', activation='relu',
kernel_regularizer=tf.keras.regularizers.l2(0.001)),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(512, activation='relu',
kernel_regularizer=tf.keras.regularizers.l2(0.001)),
tf.keras.layers.Dense(1)
])
在这里,我们为卷积层和稠密层增加了L2正则化。我们可以看到网络的模型结构为:
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_9 (Conv2D) (None, 128, 128, 16) 448
_________________________________________________________________
max_pooling2d_9 (MaxPooling2 (None, 64, 64, 16) 0
_________________________________________________________________
conv2d_10 (Conv2D) (None, 64, 64, 32) 4640
_________________________________________________________________
max_pooling2d_10 (MaxPooling (None, 32, 32, 32) 0
_________________________________________________________________
conv2d_11 (Conv2D) (None, 32, 32, 64) 18496
_________________________________________________________________
max_pooling2d_11 (MaxPooling (None, 16, 16, 64) 0
_________________________________________________________________
flatten_3 (Flatten) (None, 16384) 0
_________________________________________________________________
dense_4 (Dense) (None, 512) 8389120
_________________________________________________________________
dense_5 (Dense) (None, 1) 513
=================================================================
Total params: 8,413,217
Trainable params: 8,413,217
Non-trainable params: 0
我们可以发现,网络的参数并没有发生变化,这是因为正则化并不会引入新的参数,也不会减少参数。
在训练结束后我们可以得到模型训练结果的准确率曲线为:
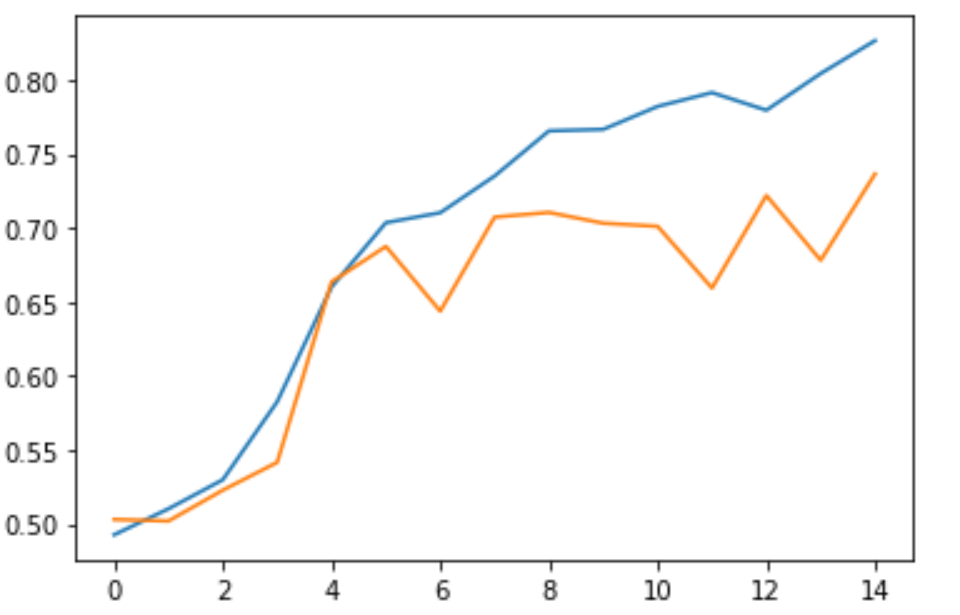
而模型训练结果的损失Loss曲线为:
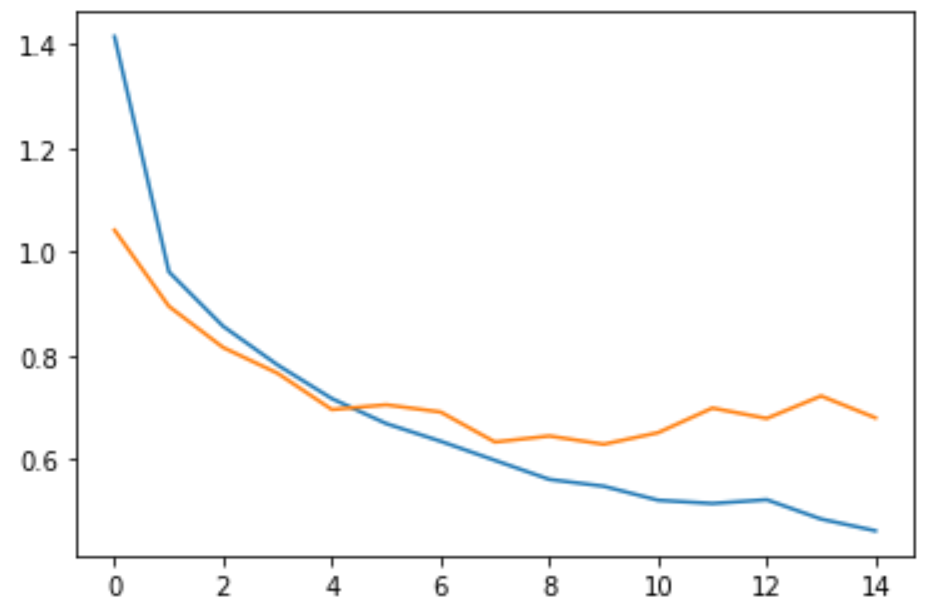
可以看到,与之前的模型相比,我们现在的模型在一定程度上降低了过拟合。对于损失这一点尤为明显,它只在第 7 个 Epoch 出现了上升,同时并没有像之前一样上升的如此剧烈。
4. 使用早停策略
这个策略会使用到我们下节课学习到的回调函数,但是这也是方式过拟合产生的一种手段。它的思想比较简单:
“如果你在验证集上的准确率或者损失持续没有提升,那么我就把你停止掉,不让你继续训练。”
在 TensorFlow 之中,我们可以通过以下的回调方式来实现早停:
callback = tf.keras.callbacks.EarlyStopping(monitor='loss', patience=3)
其中EarlyStopping的常用参数包括:
- monitor: 指定哪一个指标作为监控的标准,一般为损失或者准确率,这里是损失;
- patience:忍耐限度,如果经过了 patience 个 epoch ,monitor 指标还没有提升,那么会停止训练。
于是我们可以将模型还原为之前的模型,同时在训练的代码中添加相应的早停回调。
callback = tf.keras.callbacks.EarlyStopping(monitor='val_loss', patience=2)
history = model.fit_generator(
train_data_generator,
steps_per_epoch=TRAIN_NUM // BATCH_SIZE,
epochs=EPOCHS,
validation_data=valid_data_generator,
validation_steps=VALID_NUM // BATCH_SIZE,
callbacks=[callback])
在这里我们在训练的过程之中添加了一个EarlyStopping的回调。
在训练结束后我们可以得到损失的准确率的曲线为:
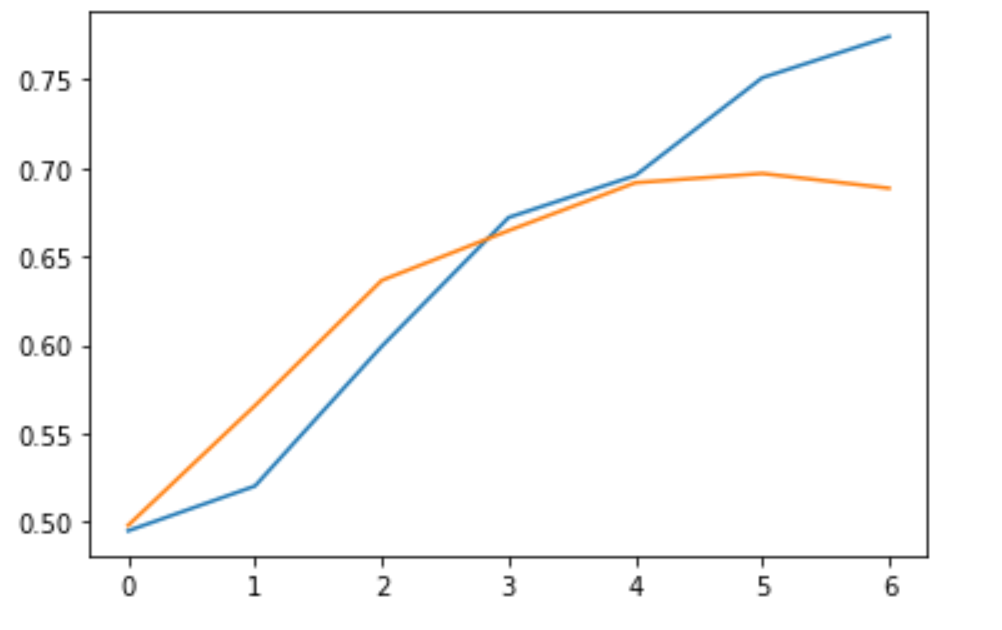
同时损失的曲线为:
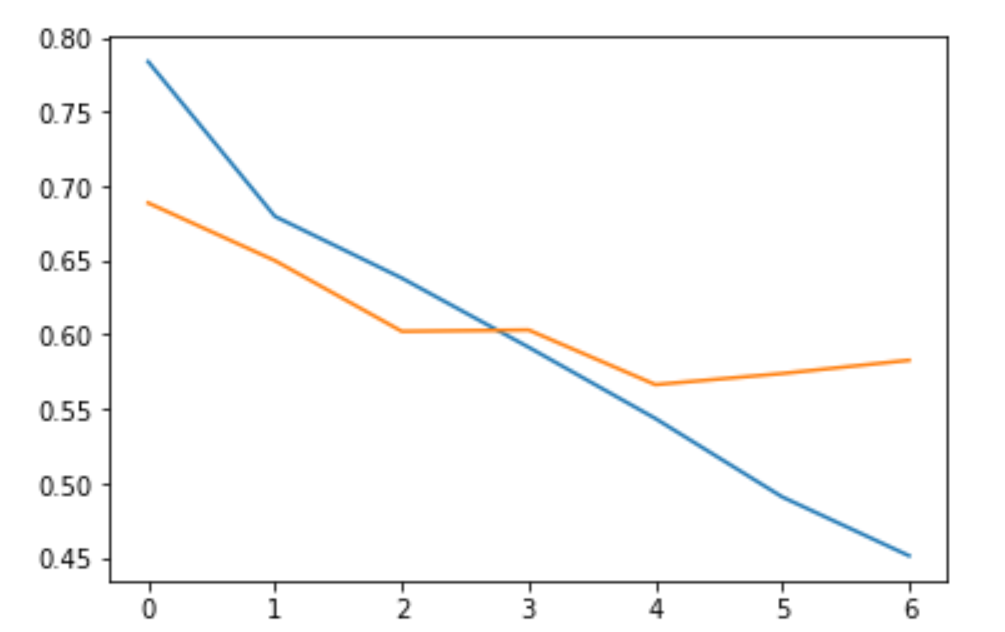
我们可以看到, 该模型在第 7 个 Epoch 就停止了继续训练,这是因为它的 Loss 在最近的两个 Epoch 并没有持续的提升,从而避免了后面不必要的训练过程。
5. 小结
在这节课之中,我们学习了什么是过拟合,同时了解了如何在 TensorFlow 之中避免过拟合的发生,我们可以采用的方法有 DropOut 、正则化以及早停策略。而在实际的应用之中,大家可以根据自己需要将不同的放过发结合起来使用,这样才能达到比较良好的效果。

 2026 imooc.com All Rights Reserved |
2026 imooc.com All Rights Reserved |