
































































 夜流歌 ·
夜流歌 ·使用 TensorFlow 加载 pandas.DataFrame 数据
DataFrame,直译叫做“数据帧”,是一种二位数据,也就是说 DataFrame 是一种以表格形式存储数据的数据格式。
因为在机器学习之中最常用的表格数据格式是 CSV 格式的表格数据,因此机器学习领域的 DataFrame 绝大多数都是由 CSV 文件读取而来的。因此这节课我们主要学习如何从 CSV 数据之中读取 DataFrame 数据并且将其转化为 TensorFlow 能够使用的数据集合。
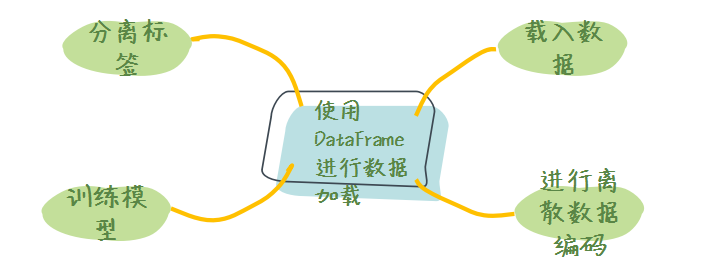
总体来说使用 DataFrame 加载数据大致分为四步:
- 使用 pandas 读取数据文件为 DataFrame;
- 对 于DataFrame 进一步处理;
- 将 DataFrame 数据转化为 tf.data.Dataset;
- 进一步的数据处理与使用。
那么在接下来我们会以一个之前学习过的泰坦尼克数据集作为简单的示例来带领大家使用 pandas.DataFrame 读取并加载数据。
1. 使用 pandas 读取数据文件为 DataFrame
首先我们需要在机器上安装 pandas,如果在安装 TensorFlow 的过程中没有自动安装 pandas ,那么我们就需要手动安装 pandas :
pip install pandas
对于 CSV 文件,我们只需要使用 pd.read_csv() 函数就可以正确地读取CSV文件中的数据为 DataFrame 格式数据。
具体来说,我们可以通过以下代码进行操作:
import pandas as pd
import tensorflow as tf
train_file = tf.keras.utils.get_file("train.csv", "https://storage.googleapis.com/tf-datasets/titanic/train.csv")
train_df = pd.read_csv(train_file)
train_df.head()
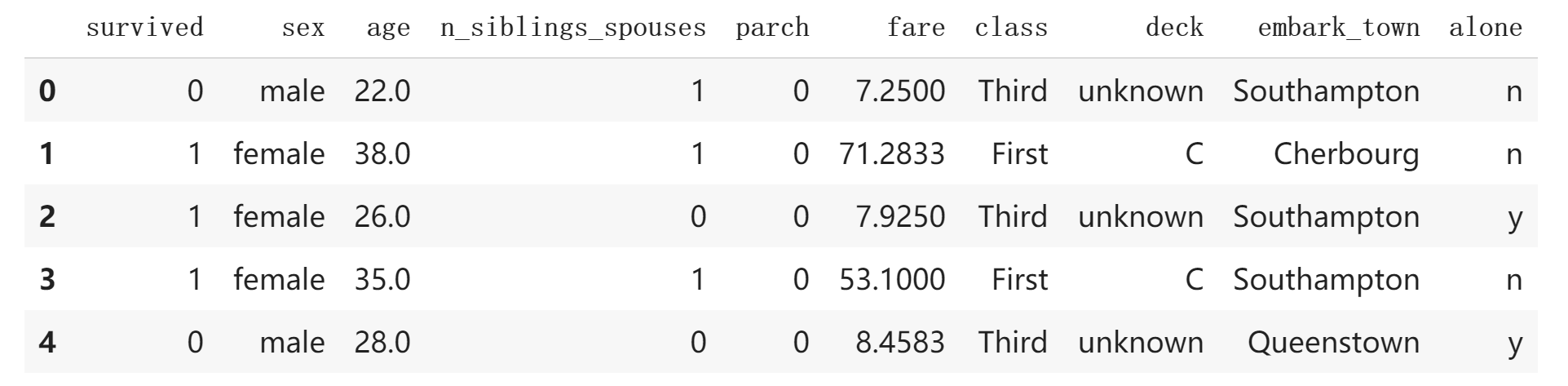
其中,tf.keras.utils.get_file 是我们之前学习过的获得数据集合文件。而最后一行的 train_df.head() 是显示数据集合的前 5 条数据,我们可以得到输出为:
2. 对 DataFrame 进一步处理
在这一个步骤之中,我们要进行的工作主要有:
- 离散数据离散化,并且进行编码;
- 分离标签与数据。
对于离散数据离散化,我们可以使用 pandas 内置的 pd.Categorical() 方法进行;而后我们需要进行的是离散数据的编码,此时我们可以通过 DataFrame.xxx.cat.codes 来实现,其中 xxx 为 DataFrame 的属性。
具体我们可以通过以下代码实现:
train_df['sex'] = pd.Categorical(train_df['sex'])
train_df['sex'] = train_df.sex.cat.codes
train_df['deck'] = pd.Categorical(train_df['deck'])
train_df['deck'] = train_df.deck.cat.codes
train_df['embark_town'] = pd.Categorical(train_df['embark_town'])
train_df['embark_town'] = train_df.embark_town.cat.codes
train_df['alone'] = pd.Categorical(train_df['alone'])
train_df['alone'] = train_df.alone.cat.codes
train_df['classes'] = pd.Categorical(train_df['class'])
train_df['classes'] = train_df.classes.cat.codes
train_df.pop('class')
train_df.head()
我们可以得到如下输出:
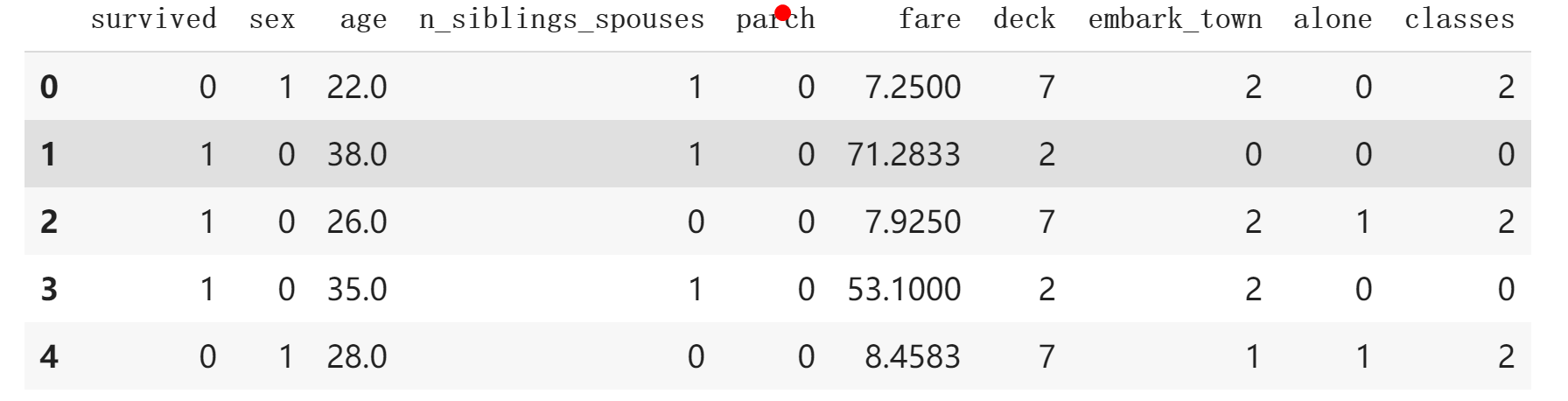
可以发现,之前的离散数据现在都已经使用整数进行编码了。
要分离标签与数据,我们可以直接通过 pop() 函数来实现:
labels = train_df.pop('survived')
3. 构建 tf.data.Dataset 数据集
在这一步,我们可以使用之前的方法 tf.data.Dataset.from_tensor_slices 来进行数据集的构造。
对于该示例,我们可以通过以下代码实现:
train_dataset = tf.data.Dataset.from_tensor_slices((train_df.values, labels.values))
train_dataset = train_dataset.shuffle(len(train_df)).batch(32)
4. 数据集的使用
在这里,我们使用和之前相似的模型进行演示,于是我们首先定义一个分类器,然后进行训练。
具体代码如下所示:
model = tf.keras.Sequential([
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid'),
])
model.compile(
loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
model.fit(train_dataset, epochs=30)
我们可以得到结果:
......
Epoch 29/30
20/20 [==============================] - 0s 1ms/step - loss: 0.4398 - accuracy: 0.8086
Epoch 30/30
20/20 [==============================] - 0s 2ms/step - loss: 0.4332 - accuracy: 0.8214
我们可以发现,我们的模型在训练集合上达到了 82% 的准确率。
5. 小结
在本节课之中,我们学习了如何使用 pandas.DataFrame 来进行数据集合的加载。在加载的过程之中,我们首先要读取数据,然后对离散数据进行进一步的处理,再者构建 tf.data.Dataset 用于以后的训练使用。

 2026 imooc.com All Rights Reserved |
2026 imooc.com All Rights Reserved |