
































































 夜流歌 ·
夜流歌 ·使用 tf.keras 进行图片分类
既然 tf.keras 是我们在实际工作中使用最多的工具,那么这节课我们首先来学习如何使用 tf.keras 进行图片的分类。
这节课会介绍图像分类网络的常用的网络层、如何处理图片数据以及整体程序的结构。
在这里我们采用的是 Kaggle 上的猫狗分类数据集,该数据集合的数据的标签分为猫和狗两个类别,他们的数量分别为:
- 训练集合 2000 张图片,包括 1000 张狗图片和 1000 张猫图片;
- 验证集合 1000 张图片,包括 500 张狗图片和 500 张猫图片。
我们会按照获取数据、准备数据、训练数据、数据可视化的顺序帮助大家理解图片分类的过程。
通过学习该节课程,我们会得到一个能够分辨猫图片和狗图片、正确率在 70% 以上的分类模型。
1. 获取数据
首先我们要引入我们所需要的程序包:
import tensorflow as tf
import os
import matplotlib.pyplot as plt
其中 os 用于目录的相关操作,而 plt 用于我们的图片绘制工作,然后我们进行数据的下载与解压:
dataset_url = 'https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip'
path_download = os.path.dirname(tf.keras.utils.get_file('cats_and_dogs.zip',
origin=dataset_url,
extract=True))
train_dataset_dir = path_download + '/cats_and_dogs_filtered/train'
valid_dataset_dir = path_download + '/cats_and_dogs_filtered/validation'
这里的第二行操作是使用 Keras 内置的下载工具进行下载,返回的是数据集所在的路径。
我们最后是结合数据集的下载位置与其内部文件建构得到训练数据集与测试数据集所在的目录,
其中 train_dataset_dir 是训练集的目录,而 valid_dataset_dir 是测试集合所在的目录。
可以通过下面的方法来查看数据文件所在的目录。
print(cat_train_dir, cat_validation_dir, dog_train_dir, dog_validation_dir)
然后我们定义一些数据集合与训练的基本参数,留作后面训练之用:
BATCH_SIZE = 64
TRAIN_NUM = 2000
VALID_NUM = 1000
EPOCHS = 15
Height = 128
Width = 128
这些值的具体含义为:
- BATCH_SIZE: 批次的大小,我们会将 BATCH_SIZE 个图片数据同时送给模型进行训练,这个数值大家可以根据自己的内存大小或者显存大小进行调整;
- TRAIN_NUM: 训练集的数量,这里是 2000;
- VALID_NUM: 验证集的数量,这里是 1000;
- EPOCHS: 训练的周期数,将所有的数据通用模型训练一遍称为一个 EPOCH,一般来说,EPOCH 的数值越大,模型在训练集合上的准确率越高,相应的所需要的时间也更长;
- Height: 图片的高度;
- Width: 图片的长度。
2. 数据预处理
这里我们要使用 Keras 内部内置的 ImageDataGenerator 来作为迭代器产生数据。
train_image_generator = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1./255)
valid_image_generator = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1./255)
在这里我们定义了两个图片数据迭代器,同时我们定义了 rescale 参数,在函数内部每张图片的每个像素数据都会乘以 1./255,以将其归一化到 [0, 1] 之间,因为机器学习之中模型的最好输入数据是在 [0, 1] 之间。
然后我们使用文件夹中的数据来初始化这两个图片数据迭代器,这个功能是采用 flow_from_directory 函数来实现的:
train_data_generator = train_image_generator.flow_from_directory(
batch_size=BATCH_SIZE,
directory=train_dataset_dir,
shuffle=True,
target_size=(Height, Width),
class_mode='binary')
valid_data_generator = valid_image_generator.flow_from_directory(
batch_size=BATCH_SIZE,
directory=valid_dataset_dir,
shuffle=True,
target_size=(Height, Width),
class_mode='binary')
其中的几个参数的解释如下:
- batch_size:数据批次的大小,我们之前定义为 64;
- directory:数据存放的文件夹;
- shuffle:数据是否打乱,这里我们选择进行打乱;
- target_size:输出图片的大小,这里我们将长宽都定义为 128;
- class_mode:分类模式,这里我们选择 “binary” 表示这是一个二分类问题,如果是多分类问题,我们可以选择 “categorical”。
至此我们就完成了数据的预处理的工作。
3. 构建模型
这里我们采用传统的顺序结构来定义我们的网络结构,具体如下:
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(16, 3, padding='same', activation='relu',
input_shape=(Height, Width ,3)),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(32, 3, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(64, 3, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dense(1)
])
在这里我们采用了两种新的网络层结构,分别是 Conv2D 层与 MaxPooling2D 层,这两层在后面我们都会详细学习,这里我们可以暂且理解为:
- Conv2D:卷积层,用来提图片的特征;
- MaxPooling2D:池化层,用来降低计算量;
- 一般来说,池化层都会跟在卷积层之后。
然后我们对模型进行编译:
model.compile(optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
model.summary()
在这里我们需要注意的有:
- 优化器我们选择最常用的 adam 优化器,同时我们在训练的过程中记录准确率(accuracy);
- 因为任务是二元分类,因此我们采用的是二元交叉熵(BinaryCrossentropy);
- 因为网络最后一层没有激活函数而直接输出,因此模型产生的数据实际是两个类别的可能性的大小;所以优化器会加上参数
from_logits=True,以表示输出为可能性大小,而不是具体类别。
运行上面代码我们可以得到网络的结构:
Model: "sequential_3"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_9 (Conv2D) (None, 128, 128, 16) 448
_________________________________________________________________
max_pooling2d_9 (MaxPooling2 (None, 64, 64, 16) 0
_________________________________________________________________
conv2d_10 (Conv2D) (None, 64, 64, 32) 4640
_________________________________________________________________
max_pooling2d_10 (MaxPooling (None, 32, 32, 32) 0
_________________________________________________________________
conv2d_11 (Conv2D) (None, 32, 32, 64) 18496
_________________________________________________________________
max_pooling2d_11 (MaxPooling (None, 16, 16, 64) 0
_________________________________________________________________
flatten_3 (Flatten) (None, 16384) 0
_________________________________________________________________
dense_6 (Dense) (None, 512) 8389120
_________________________________________________________________
dense_7 (Dense) (None, 1) 513
=================================================================
Total params: 8,413,217
Trainable params: 8,413,217
Non-trainable params: 0
4. 训练模型
在训练模型的时候,我们会使用之前定义好的图片数据迭代器,同时将训练数据保存在 history 对象之中:
history = model.fit_generator(
train_data_generator,
steps_per_epoch=TRAIN_NUM // BATCH_SIZE,
epochs=EPOCHS,
validation_data=valid_data_generator,
validation_steps=VALID_NUM // BATCH_SIZE)
通过训练,我们可以得到以下的输出:
Epoch 1/15
31/31 [==============================] - 41s 1s/step - loss: 0.7072 - accuracy: 0.5134 - val_loss: 0.6650 - val_accuracy: 0.5167
Epoch 2/15
31/31 [==============================] - 40s 1s/step - loss: 0.6540 - accuracy: 0.5826 - val_loss: 0.6381 - val_accuracy: 0.5448
Epoch 3/15
31/31 [==============================] - 39s 1s/step - loss: 0.5780 - accuracy: 0.6844 - val_loss: 0.5859 - val_accuracy: 0.7208
Epoch 4/15
31/31 [==============================] - 40s 1s/step - loss: 0.5245 - accuracy: 0.7485 - val_loss: 0.5550 - val_accuracy: 0.6719
Epoch 5/15
31/31 [==============================] - 40s 1s/step - loss: 0.4673 - accuracy: 0.7645 - val_loss: 0.5654 - val_accuracy: 0.6865
Epoch 6/15
31/31 [==============================] - 40s 1s/step - loss: 0.3968 - accuracy: 0.8110 - val_loss: 0.5929 - val_accuracy: 0.7208
Epoch 7/15
31/31 [==============================] - 40s 1s/step - loss: 0.3216 - accuracy: 0.8492 - val_loss: 0.6224 - val_accuracy: 0.7104
Epoch 8/15
31/31 [==============================] - 40s 1s/step - loss: 0.2577 - accuracy: 0.8879 - val_loss: 0.6871 - val_accuracy: 0.7115
Epoch 9/15
31/31 [==============================] - 40s 1s/step - loss: 0.2204 - accuracy: 0.9060 - val_loss: 0.6982 - val_accuracy: 0.7250
Epoch 10/15
31/31 [==============================] - 40s 1s/step - loss: 0.1633 - accuracy: 0.9329 - val_loss: 0.9962 - val_accuracy: 0.6896
Epoch 11/15
31/31 [==============================] - 40s 1s/step - loss: 0.1371 - accuracy: 0.9489 - val_loss: 0.8724 - val_accuracy: 0.6990
Epoch 12/15
31/31 [==============================] - 40s 1s/step - loss: 0.0937 - accuracy: 0.9654 - val_loss: 1.1101 - val_accuracy: 0.7052
Epoch 13/15
31/31 [==============================] - 40s 1s/step - loss: 0.0640 - accuracy: 0.9742 - val_loss: 1.0343 - val_accuracy: 0.7083
Epoch 14/15
31/31 [==============================] - 40s 1s/step - loss: 0.0449 - accuracy: 0.9866 - val_loss: 1.1627 - val_accuracy: 0.7167
Epoch 15/15
31/31 [==============================] - 40s 1s/step - loss: 0.0199 - accuracy: 0.9954 - val_loss: 1.2627 - val_accuracy: 0.7156
输出准确率与损失值因人而异,在这里我们在训练集合上得到了 99.54% 的准确率,在验证集上得到了 71.56% 的准确率。
5. 可视化训练过程
在上一步之中,我们特地将训练过程的数据记录进了 history 对象之中;history 对象中的 history 数据对象是一个字典型的结构,其中包含了我们在训练过程中的准确率与损失值等等。
于是我们将其可视化:
acc = history.history['accuracy']
loss = history.history['loss']
val_acc = history.history['val_accuracy']
val_loss = history.history['val_loss']
plt.plot(range(EPOCHS), acc, label='Train Acc')
plt.plot(range(EPOCHS), val_acc, label='Valid Acc')
plt.show()
plt.plot(range(EPOCHS), loss, label='Train Loss')
plt.plot(range(EPOCHS), val_loss, label='Valid Loss')
plt.show()
在这里我们使用了两个图表,第一个图片展示准确率的变化,第二个图片展示损失值的变化。
由此我们可以得到以下两张图片:
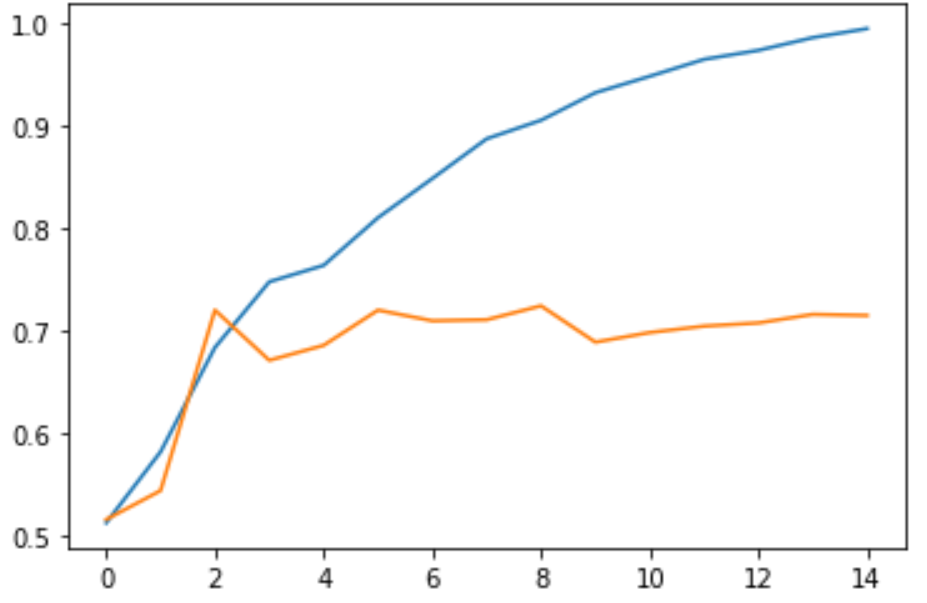
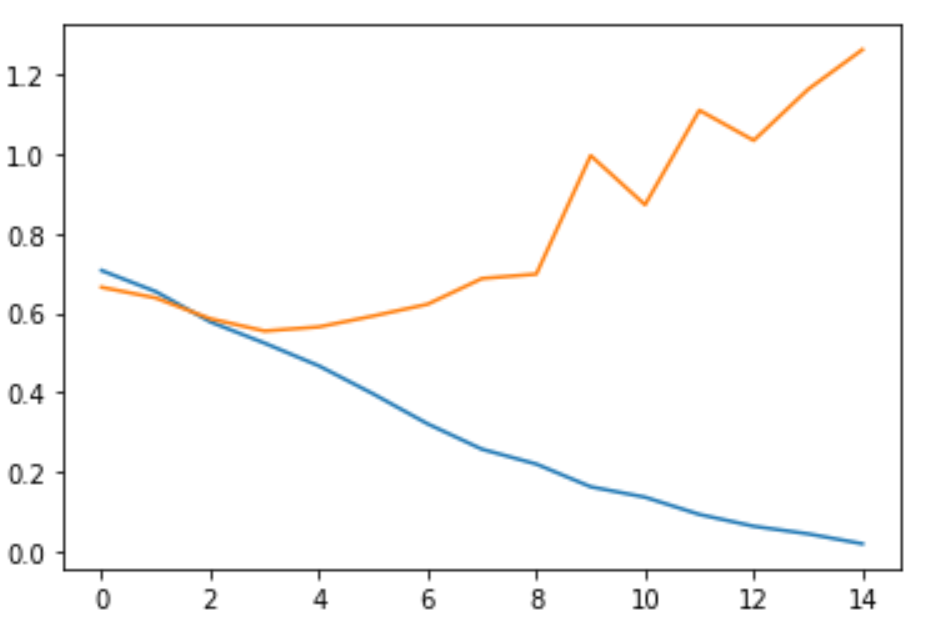
由此可以看出,随着训练的不断迭代,训练集合上的准确率不断上升,损失值不断下降;但是验证集上的准确率在第 3 个 Epoch 以后便趋于平稳,而损失值却在第 3 个 Epoch 之后逐渐上升。这就是我们在训练过程中遇到的过拟合,我们以后会有课程详细介绍过拟合。
6. 完整代码案例代码
import tensorflow as tf
import os
import matplotlib.pyplot as plt
dataset_url = 'https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip'
path_download = os.path.dirname(tf.keras.utils.get_file('cats_and_dogs.zip', origin=dataset_url, extract=True))
train_dataset_dir = path_download + '/cats_and_dogs_filtered/train'
valid_dataset_dir = path_download + '/cats_and_dogs_filtered/validation'
cat_train_dir = path_download + '/cats_and_dogs_filtered/train/cats'
cat_validation_dir = path_download + '/cats_and_dogs_filtered/validation/cats'
dog_train_dir = path_download + '/cats_and_dogs_filtered/train/dogss'
dog_validation_dir = path_download + '/cats_and_dogs_filtered/validation/dogs'
BATCH_SIZE = 64
TRAIN_NUM = 2000
VALID_NUM = 1000
EPOCHS = 15
Height = 128
Width = 128
train_image_generator = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1./255)
valid_image_generator = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1./255)
train_data_generator = train_image_generator.flow_from_directory(batch_size=BATCH_SIZE,
directory=train_dataset_dir,
shuffle=True,
target_size=(Height, Width),
class_mode='binary')
valid_data_generator = valid_image_generator.flow_from_directory(batch_size=BATCH_SIZE,
directory=valid_dataset_dir,
shuffle=True,
target_size=(Height, Width),
class_mode='binary')
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(16, 3, padding='same', activation='relu',
input_shape=(Height, Width ,3)),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(32, 3, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(64, 3, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dense(1)
])
model.compile(optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
model.summary()
history = model.fit_generator(
train_data_generator,
steps_per_epoch=TRAIN_NUM // BATCH_SIZE,
epochs=EPOCHS,
validation_data=valid_data_generator,
validation_steps=VALID_NUM // BATCH_SIZE)
acc = history.history['accuracy']
loss=history.history['loss']
val_acc = history.history['val_accuracy']
val_loss=history.history['val_loss']
epochs_ran = range(EPOCHS)
plt.plot(epochs_ran, acc, label='Train Acc')
plt.plot(epochs_ran, val_acc, label='Valid Acc')
plt.show()
plt.plot(epochs_ran, loss, label='Train Loss')
plt.plot(epochs_ran, val_loss, label='Valid Loss')
plt.show()
7. 小结
在这节之中,我们学习了如何对图片数据进行预处理,同时也了解了图片处理中常用的两种层结构:卷积层和池化层。于此同时,我们也对训练过程进行了可视化操作,并亲眼见证了过拟合的发生。
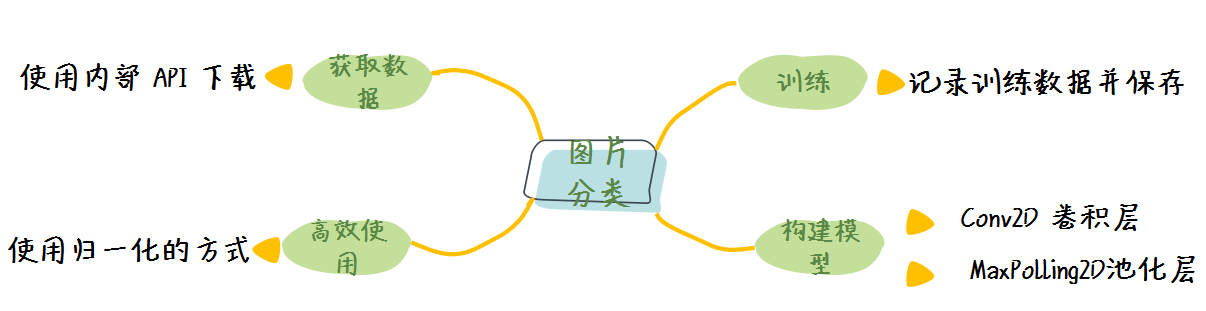
我们这节课所学的大致内容包括:

 2024 imooc.com All Rights Reserved |
2024 imooc.com All Rights Reserved |