
伪分布式安装:
1 关闭防火墙和selinux
直接关闭防火墙: systemctl stop firewalld.service
禁止firewall开机启动 : systemctl disable firewalld.service
查看防火墙状态:firewall-cmd --state
关闭selinux vi /etc/selinux/config
把SELINUX=enforcing 改成SELINUX=disabled
2 设置静态ip(前面已经有讲过)。
3设置主机名 绑定域名(可以不做)
绑定域名:vi /etc/hosts
添加上你的静态ip 及你想用的域名
4 重点:配置ssh无秘钥登录
生成秘钥 ssh-keygen -t rsa 一路enter
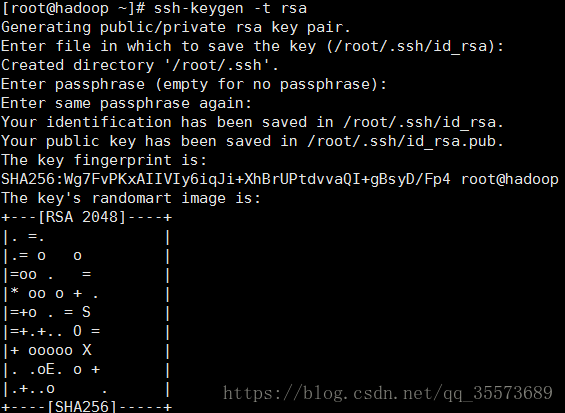
ls -al 找到生成的文件:
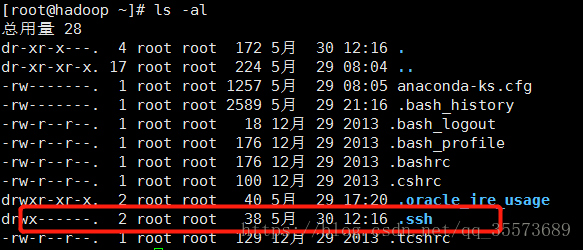
cd .ssh 可以看到一个公钥一个私钥

cp ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys(此处名称必须是这个)

使用ssh连接测试 ssh localhost
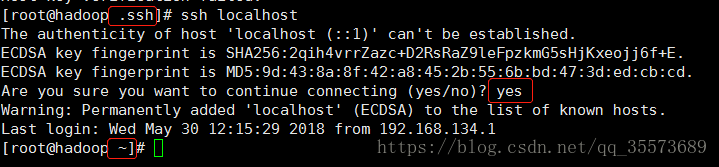
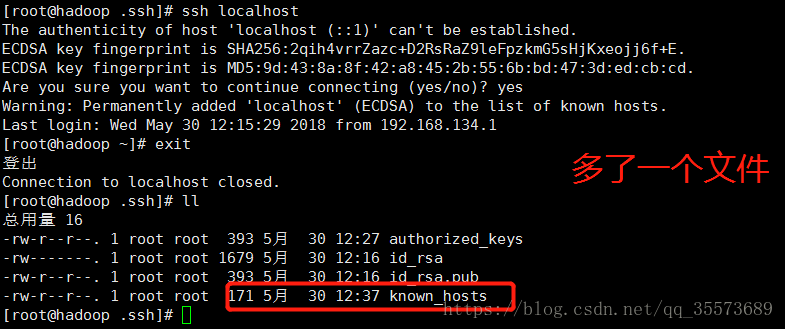
下次可以直接登录
5安装jdk 参考单机安装
6安装hadoop 参考单机安装
7在core-site.xml中添加如下配置 并在/usr/data/目录下创建tmp目录 mkdir -p usr/data/tmp
*注意,如果你没有配置域名的话,下面配置中的hadoop.dragon.org 都可以用localhost老
<configuration> <property> <name>fs.default.name</name> <value>hdfs://hadoop.dragon.org:9000</value> #指定namenode的主机和端口号,主机可以在/etc/host/修改配置 </property> <property> <name>hadoop.tmp.dir</name> #hadoop的临时目录 <value>/usr/data/tmp</value> </property> </configuration>
hdfs-site.xml配置修改如下
<configuration> <property> <name>dfs.replication</name> <value>1</value> #配置几个副本,伪分布模式为1 </property> <property> <name>dfs.permissions</name> <value>false</value> #是否进行权限检查 </property> </configuration>
mapred-site.xml
<configuration> <property> <name>mapred.job.tracker</name> <value>hadoop.dragon.org:9001</value> # 指定jobtrack主机和端口号 </property> </configuration>
配置数据节点配置文件slaves 和辅助名称节点master 把localhost修改为主机名hadoop.dragon.org
至此配置完成
8对namenode进行格式化操作 在hadoop目录下执行 ./hadoop namenode -format
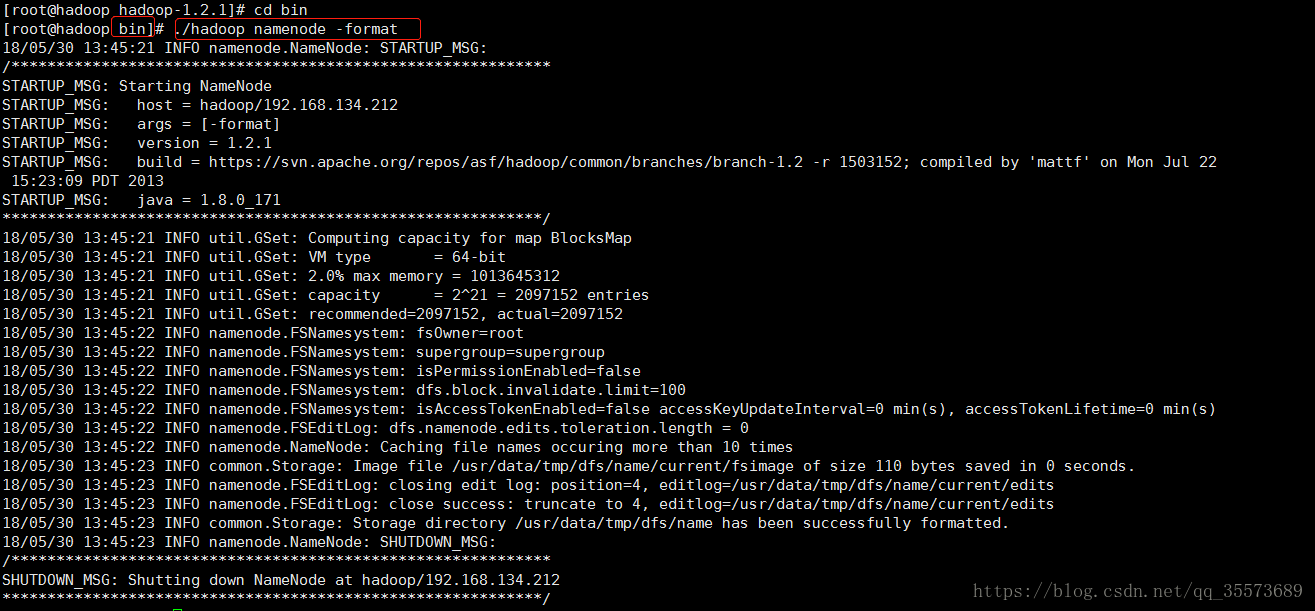

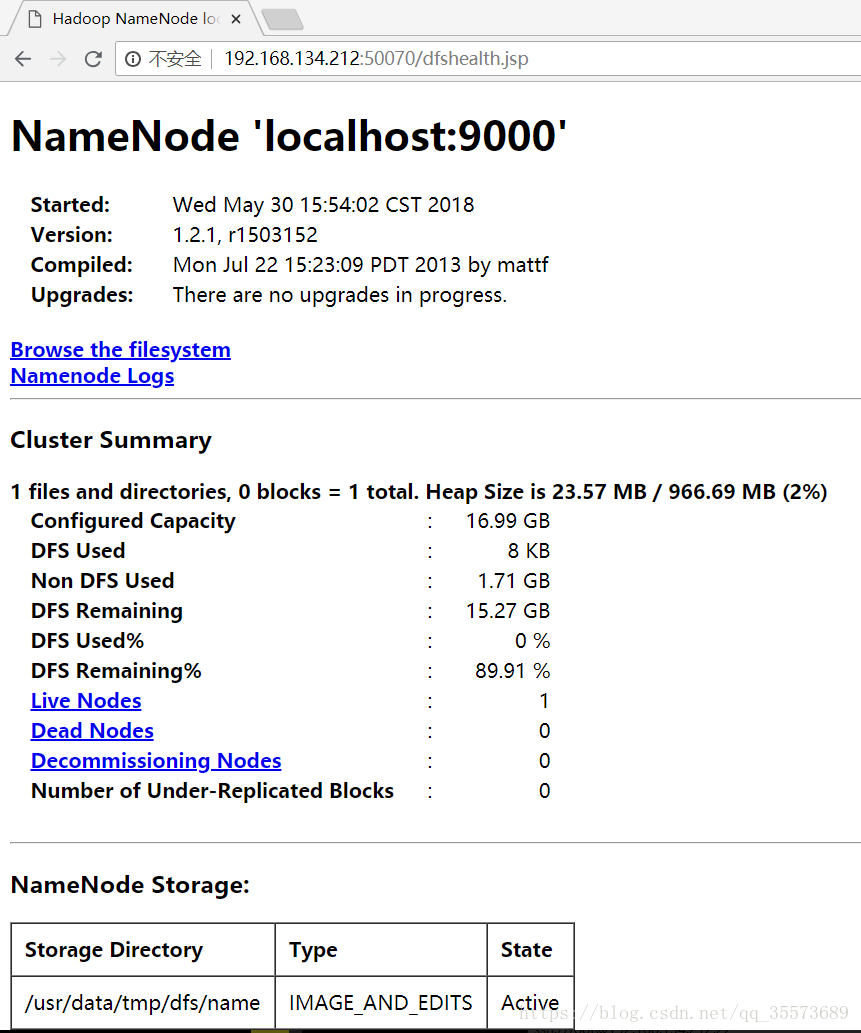
访问地址:
启动start-mapred.sh 会启动jobtrack 和tasktrack

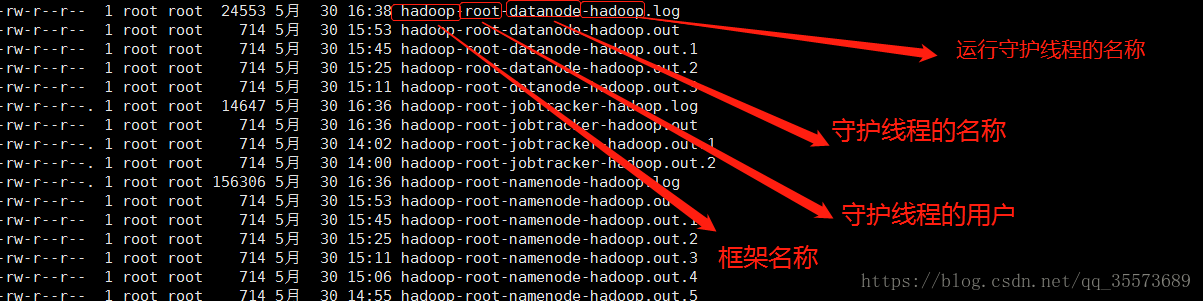
日志怎么看?有log和out两种日志类型,out记录标准输出和标准错误,日志内容比较少,系统默认保留最新的五个文件。
测试hadoop自带的wordcount
操作文件系统, 这一块首先要学习一下hadoop的命令,hadoop fs 【命令】 ,至少要了解 hadoop fs的大概意思。命令解释很快会在下一篇中补充。
假设我们要把一些文件保存到/wc/input/目录中(路径自定义),因为没有这个目录,要新建一个。
hadoop fs -mkdir /wc
hadoop fs -mkdir /wc/input
把hadoop下conf目录下xml文件拷贝到 /wc/input/下
hadoop fs -put /usr/hadoop/hadoop-1.2.1/conf/*.xml /wc/input/
执行统计查询:
cd /usr/hadoop/hadoop-1.2.1
hadoop jar hadoop-examples-1.2.1.jar wordcount /wc/input/ /wc/output/ (这个输出路径只能够使用一次)
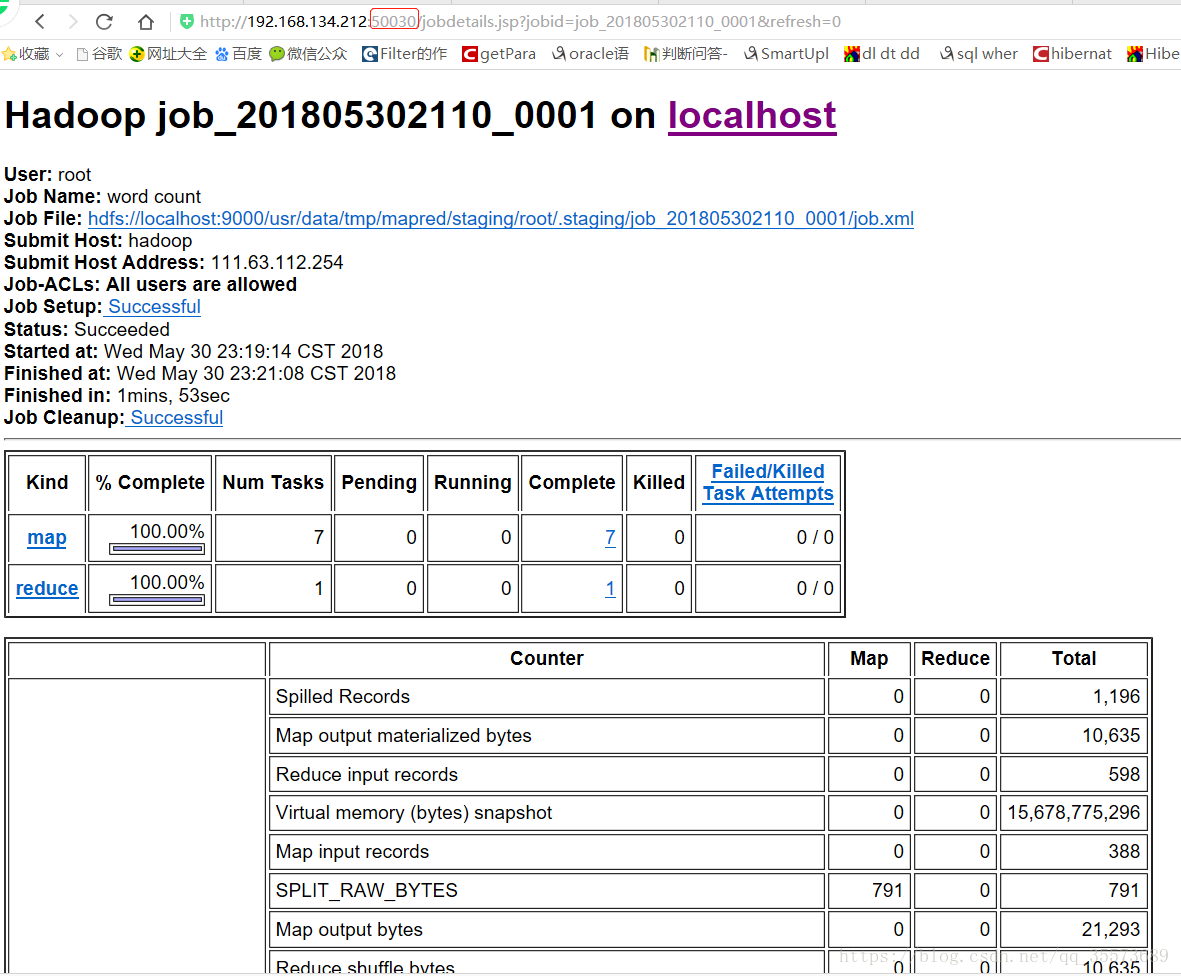
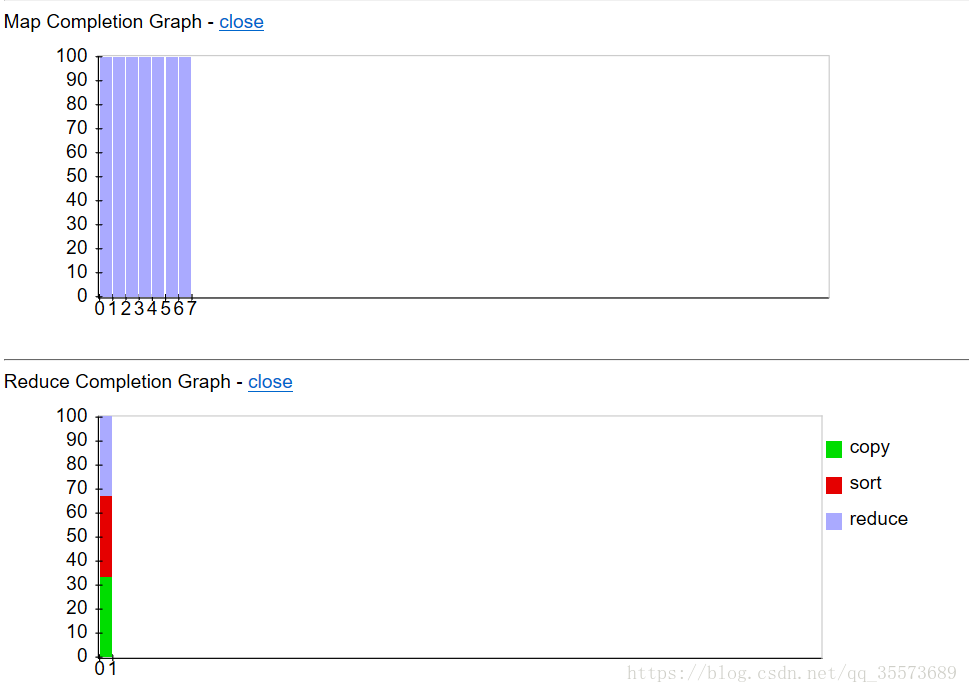
下面两幅图是一个页面可以用来实时监测map reduce的执行了多少
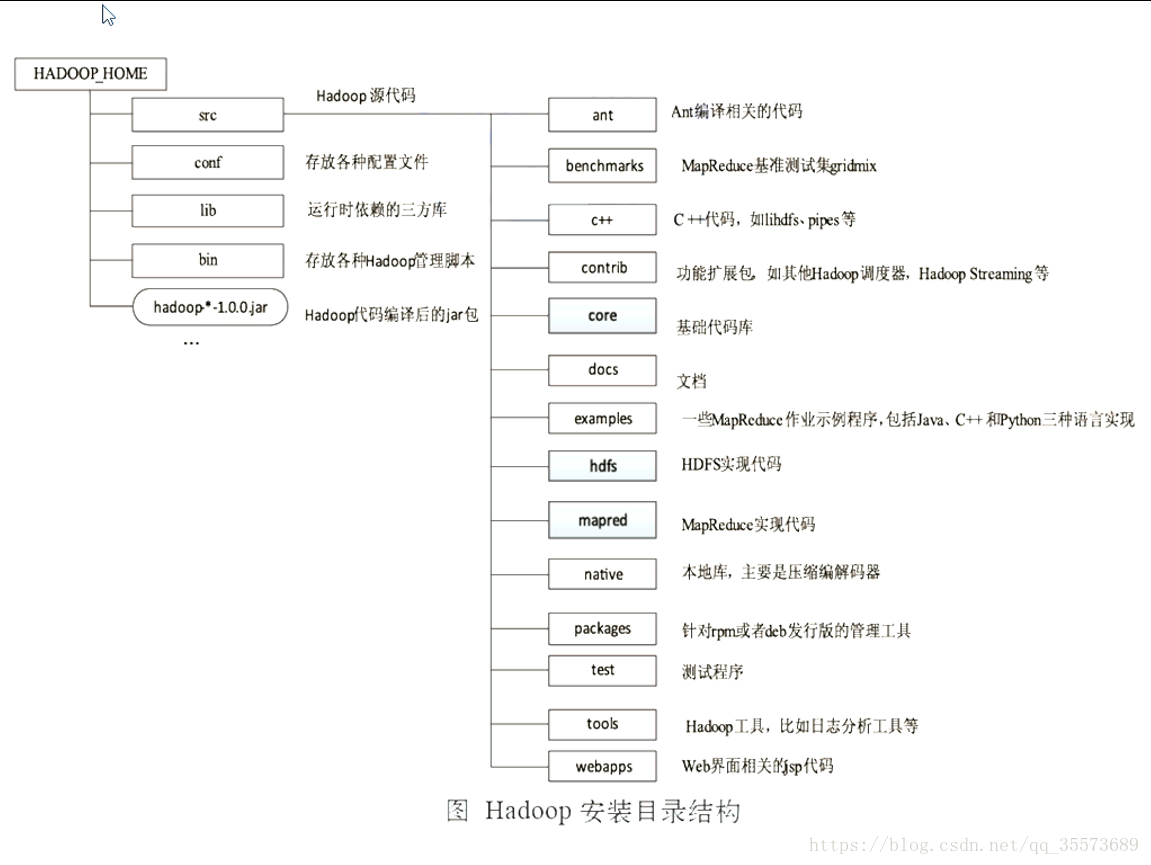
hadoop的目录结构:
共同学习,写下你的评论
评论加载中...
作者其他优质文章



