

1. 概述
过去十年,图计算无论在学术界还是工业界热度持续升高。相伴而来的是,全世界的数据正以几何级数形式增长。在这种情况下,对于数据的存储和查询的要求越来越高。因此,图数据库也在这个背景下引起了足够的重视。根据世界知名的数据库排名网站 DB-Engines.com 的统计,图数据库至 2013 年以来,一直是“增速最快”的数据库类别。虽然相比关系型数据库,图数据库的占比还是很小。但由于具有更加 graph native 的数据形式,以及针对性的关系查询优化,图数据库已经成为了关系型数据库无法替代的数据库类型。此外,随着数据量的持续爆炸性上涨,人们对于数据之间的关系也越来越重视。人们希望通过挖掘数据之间的关系,来获取商业上的成功,以及获得更多人类社会的知识。因此我们相信,天生为存储数据关系和数据挖掘而优化的图数据库会在数据库中持续保持高速增长。
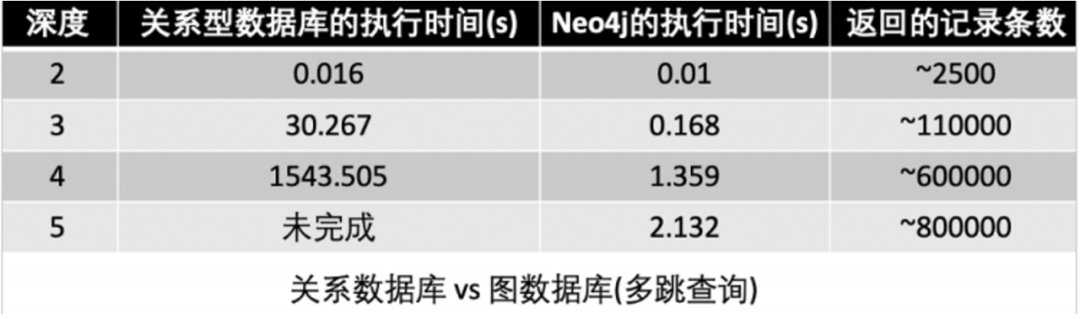
图1: 关系型和图数据库在关系查询的性能对比
图1 显示了查询数据之间多跳关系(图的深度优先或者广度优先搜索)的关系型数据库和图数据库的性能差异。(这里我们虽然以 Neo4j 为例,但 Nebula 无论在性能还是在可扩展性上都是优于 Neo4j 的)。
虽然关系查询性能胜于关系型数据库,当前主流的图数据库在多跳查询(高深度图遍历)上的性能还是灾难性的。尤其对于大数据量, 分布式系统来说更是如此。而存储的性能又往往是数据库性能的瓶颈。在我们的简单测试(单机,1GB/s SSD, 73GB 数据)中,简单的三跳查询并返回属性 P50 延迟可以达到 3.3s,P99 延迟可以达到 9.0s。而且随着查询语句的复杂度提升,系统很可能变得不可用。
目前,Nebula 使用 RocksDB 作为底层存储引擎。我们知道图数据库的主要 workload 是对于关系的多层次遍历,一次查询往往需要多次对存储引擎的读取。因此对 RocksDB 一次读取的性能劣势在图查询中会被多次放大。这也是为什么多跳图查询延迟巨大。反过来说,对于单次 RocksDB 查询的性能提升也将在 Nebula 查询中被多次放大。因此如何优化 RocksDB,使得 RocksDB 适配图数据库的 workload,成为优化存储端性能的重中之重。
RocksDB 的核心数据结构是 LSM-Tree。所有 key 和 value 都存于 LSM-Tree 中。但这种设计有一个缺点:由于 value 往往比 key 大,LSM-Tree 中大部分的空间是用来存 value 的。一旦 value 特别大,那么 LSM-Tree 会需要更深的 level 来存储数据。而 LSM-Tree 的读写性能是直接跟层数负相关的。层数越深,可能带来的读写放大就越多,性能也就越差。因此我们提出使用 KV 分离来存储图数据库:将值较小的数据存在 LSM-Tree 中,而将值较大的数据存在 log 中。这样操作,大 value 并不存在 LSM-Tree 中,LSM-Tree 的高度会降低。而 RocksDB 相邻两层的 size 是 10 倍关系,即便减少一层 LSM-Tree 高度,也能大大增加 Cache 的可能性,从而提高读性能。此外,KV 分离带来的读写放大的减少也能加快读写速度。
在我们的测试中,我们发现 KV 分离对于图查询的性能具有巨大提升。对于小 value 的查询延迟降低可以高达 80.7%。而对于大 value 的查询,延迟降低相对较少,但也可以达到 52.5%。考虑到大部分大 value 的数据是冷数据而且占绝大多数的,因此总体性能的提升将更接近于对于小 value 的查询。
值得注意的是,Nebula 从 3.0.0 版本开始已经提供了 KV 分离的功能。用户可以通过 nebula-storaged 的配置文件来配置 KV 分离的功能。
2. KV 分离技术
上文说到 LSM-Tree 存在比较严重的读写放大问题。这是因为每次 Compaction 都需要同时对 key 和 value 进行 Compaction,而且这个放大率会随着数据库的数据增加而增大(对于 100GB 数据,写放大可以达到 300 多倍)。这对 LevelDB 来说也许不是那么严重的问题。因为 LevelDB 是为 HDD 设计的。对 HDD 来说,随机读写性能远远低于顺序读写(1,000 倍差距)。只要读写放大比例小于 1,000 就是合算的。但对于 SSD 来说,随机和顺序读写性能差距没那么大,尤其对于 NVMe SSD(如下图)。
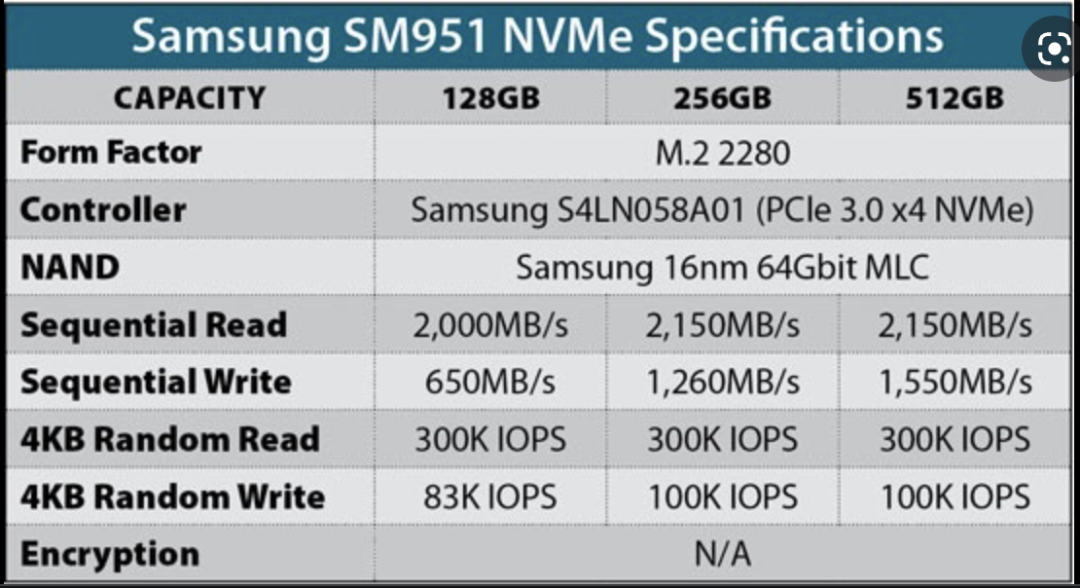
图2. NVMe SSD 性能
因此大量的读写放大会浪费带宽。于是,Lu. etc 在 2016 年提出了 KV 分离的存储结构:
https://www.usenix.org/system/files/conference/fast16/fast16-papers-lu.pdf。论文的核心思想是比较小的 key 存在 LSM-Tree 中,value 放在 log 中。这样 LSM-Tree 每一层可以存更多的 KV,同样的数据量,层级会比较低,这样可以提高读写的效率。对于写没那么多的 workload,Compaction 时省下来的写带宽可也可以降低读的 P99 延迟。当然这个设计也有一定的问题。相比 SSTable 中的 KV 绝对有序而言,log 中的 value 只是相对有序(按照 key 排序)。因为每次插入数据都是 append 到 log 中,必须依赖后续的 Garbage Collection(下简称 GC)来使 log 中的数据也变得相对有序。因此对于大规模的范围查询 Range Query,并且是小 value(64B),性能可能会差。
目前 RocksDB 的最新版本已经支持了 KV 分离:http://rocksdb.org/blog/2021/05/26/integrated-Blob-db.html。它将分离后的 value 存到了多个 log 上(.blob file)。每一个 SST 对应多个 Blob。Blob 的 GC 是在 SST Compaction 的时候触发。
3. Nebula KV 分离性能测试
在这里,我们测试 Nebula 在不同的数据和查询下的 KV 分离的性能,包括:
-
不查询属性的拓扑查询
-
分别对小 value 和大 value 点的属性查询
-
对边的属性查询
-
数据插入
-
没有大 value 情况下 KV 分离的影响。
3.1 测试环境
本次测试主要使用了一台物理机。Node A 具有 56 核 Intel® Xeon® CPU E5-2697 v3 @ 2.60GHz,256GB 内存,图数据存储在 1.5 TB 的 NVMe SSD 上。
测试数据都是由 LDBC(https://github.com/ldbc)生成。为了测试 KV 分离效果,我们准备了两类数据:一类全是小 value,另一类是大 value 和小 value 混合。对于前者,我们使用默认 LDBC 的设置,如图 3。
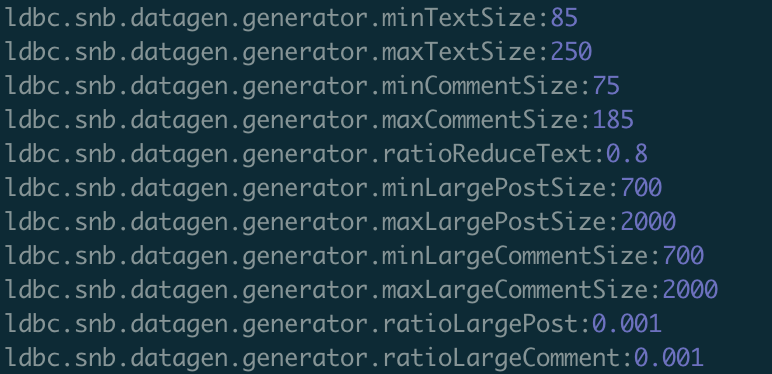
图3. LDBC 默认 Text 和 Comment value 设置
对于后者我们将 text、comment、large post 和 large comment 全部设置成 min size 4KB、max size 64KB。这是属于大 value,由 REPLY_OF 边连接。我们保留 Person 的默认设置,属于小 value,由 KNOW 边连接,其 value 的具体分布参考表 1。
| Bucket | Percentage |
|---|---|
| 0-32B | 2.67% |
| 32B-128B | 0.04% |
| 128B-160B | 96.60% |
| 160B-192B | 0.69% |
表1. Person value 大小分布
据此我们准备了两个数据,见表2。
| 数据集 | value 大小 | 数据集大小 | Comment |
|---|---|---|---|
| Data1 | < 200B Person | ||
| Default for others | 37GB | scale * 30 | |
| Data2 | <200B Person | ||
| Min 4K, Max 64K for others | 73GB | scale * 3 |
表2. 数据集详情
这里我们使用 nebula-bench 中不同的测试语句,包括 1 跳、2 跳、3 跳查询和 FindShortestPath(测试中缩写 FSP)、INSERT 语句。此外,我们还添加了 5 跳查询来测试更极限的性能情况。同一测试重复执行 5 次,后文将使用 NoSep 和 Sep 分别指代未配置 KV 分离和配置了 KV 分离。
3.2 KV 分离后 RocksDB 的内部结构
我们分别使用 KV 分离和不分离的方式导入数据集 Data2。对于 KV 分离的设置,我们设置大于某个阈值的数据存在 Blob 中(分离),小于阈值的数据存在 SST 中(不分离)。这里以 100B 阈值为例。
对于 NoSep,导入数据后,一共有 13GB 数据,217 个 SST。对于 Sep,导入数据后,一共有 16GB 数据,39 个 SST。图 4. 和图 5. 分别显示 NoSep 和 Sep 的 LSM-Tree 内部情况。
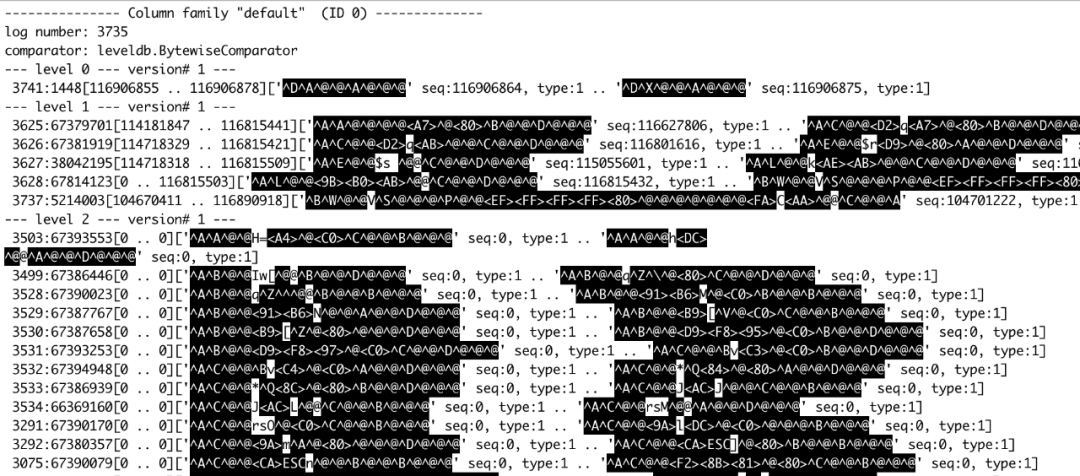
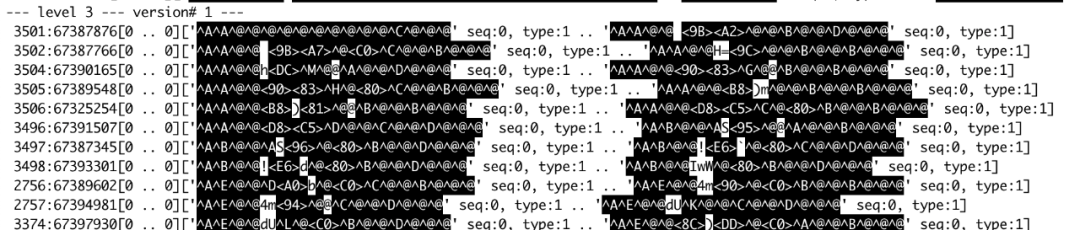

图 4. KV 不分离 RocksDB 有三层 LSM-Tree
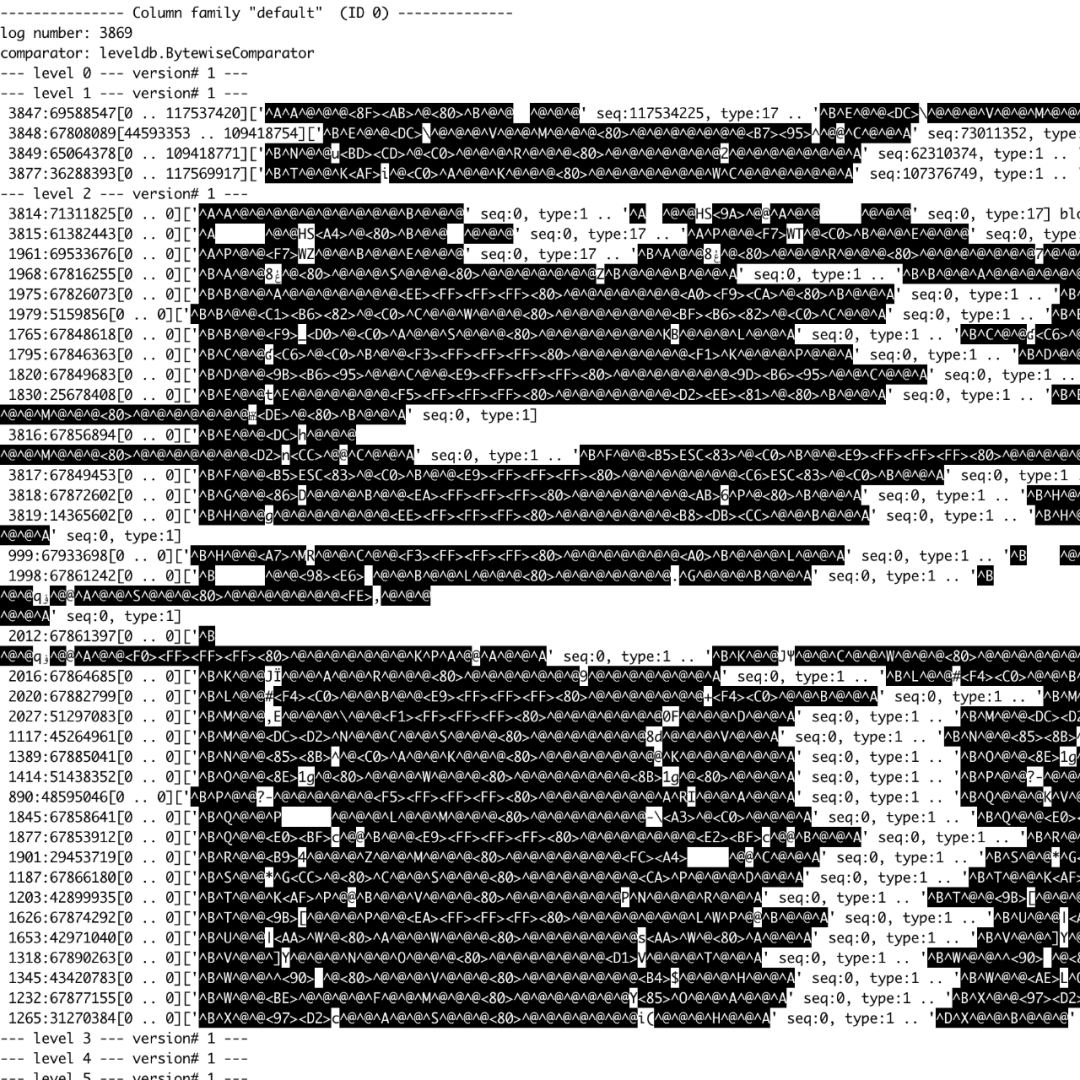
图 5. KV 分离后 RocksDB 有两层 LSM-Tree
可以看到 NoSep 使用了 3 层 LSM-Tree,而 Sep 只有两层。考虑到我们配置 RocksDB L1 为 256MB, L2 为 2.5GB,L3 为 25GB。单单层数从 3 层减少到 2 层可能就是能否将所有数据存入 Cache 的区别。
3.3 拓扑查询的性能
对于图的查询既有属性查询也有拓扑查询。首先,我们测试 KV 分离对于非值(拓扑)查询的影响。拓扑查询对 RocksDB 不会调用 GET 操作,而只有 SEEK 和 NEXT 操作。而对于拓扑查询,又分为对于 KNOW 关系和 REPLY_OF 关系进行 walk。值得注意的是,虽然这两种关系(边)所连接的点的属性大小存在很大差别,但拓扑查询只涉及边。我们将同一份 Data2 数据集分别导入到 KV 分离和不分离的 Nebula 中,并且从同一个原始数据中获取查询语句进行查询。
查询性能跟 Cache 机制有关。RocksDB 主要使用了自身的 LRU Cache,也叫 Block Cache,和 OS 的 Page Cache。其中 Block Cache 储存的是解压缩后的 Block,而 Page Cache 储存的是压缩后的 Block。Block Cache 虽然效率更高,但是空间使用率低。在生产环境中,我们推荐将 Block Cache 大小设置为 1/3 内存。本次测试将分别比较不使用 Block Cache(只有 OS Page Cache),1/3内存(80GB)大小的 Block Cache + OS Page Cache,和 direct I/O (既没有 Block Cache,也没有 OS Page Cache)各自的性能。
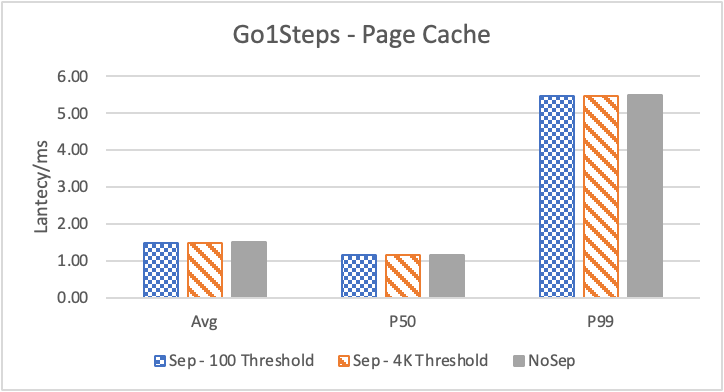
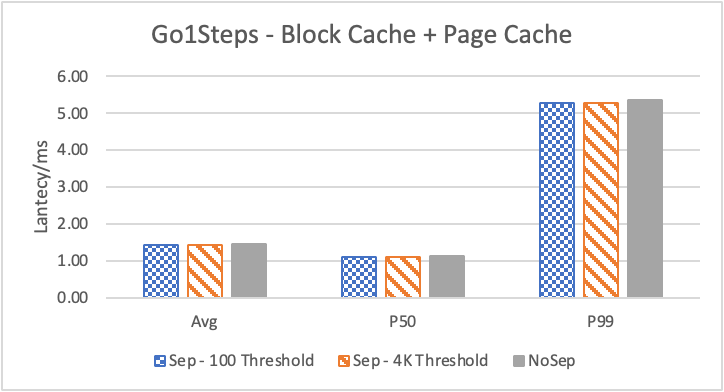
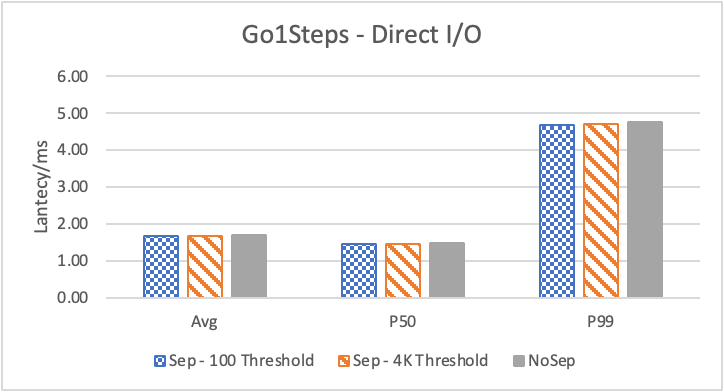
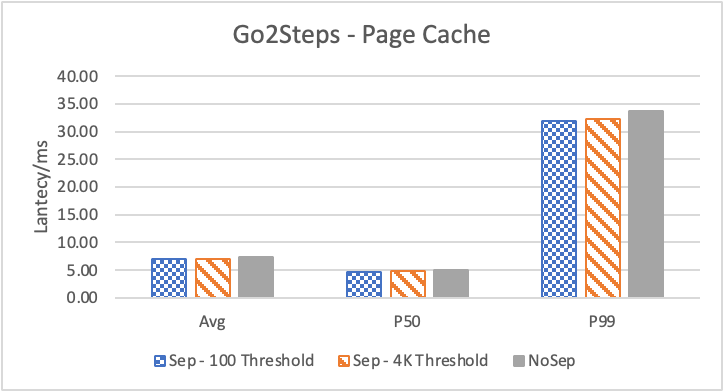
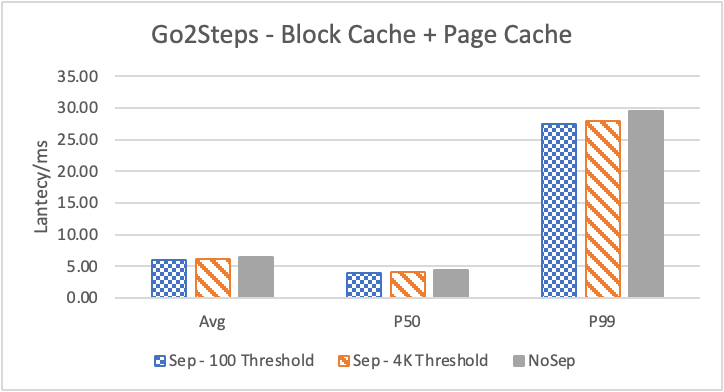
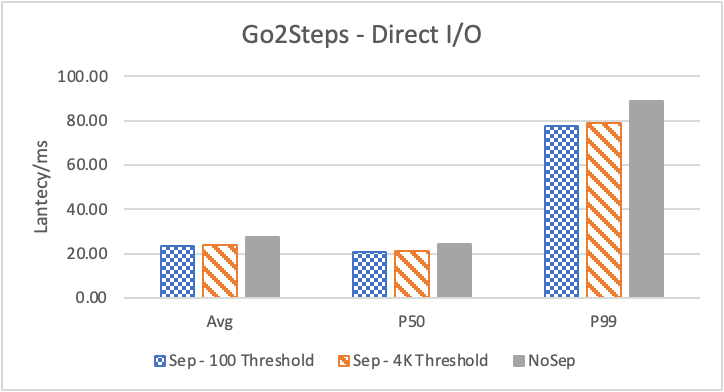
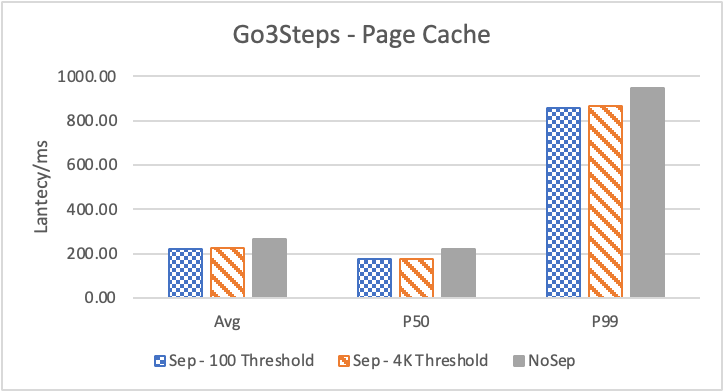
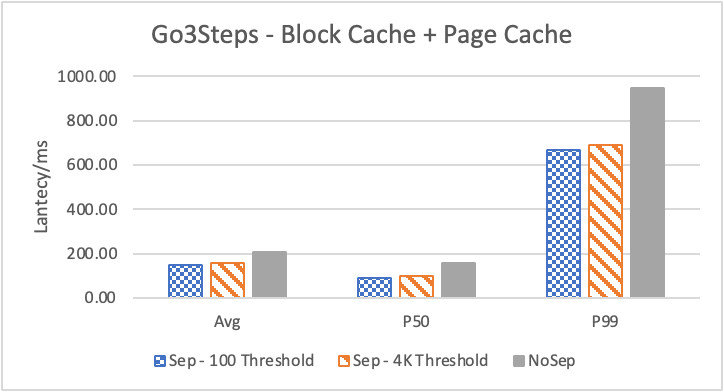
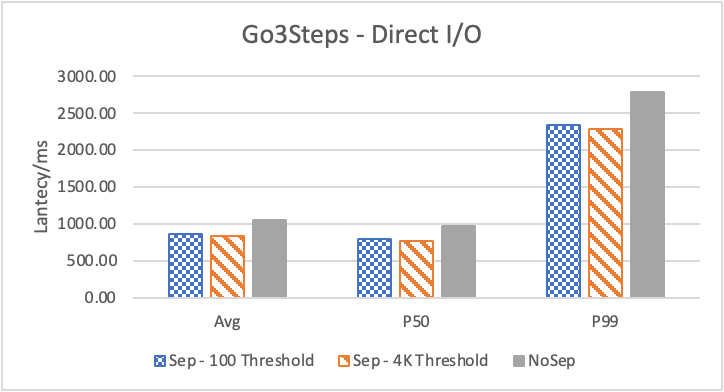
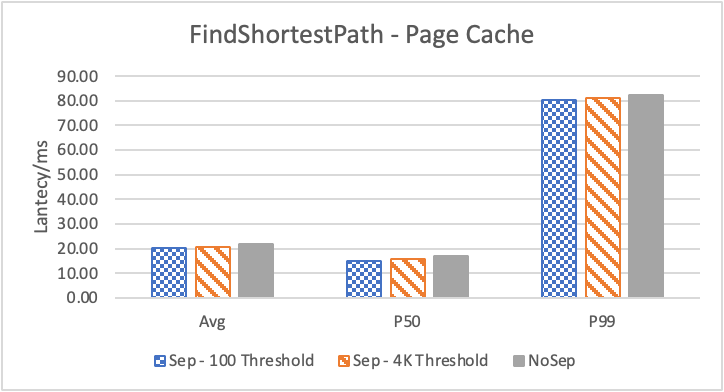
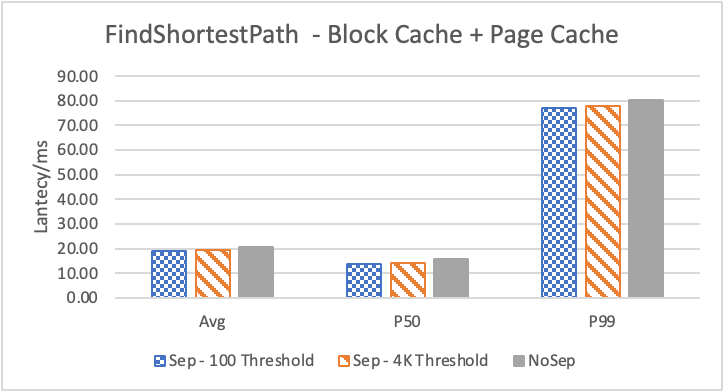
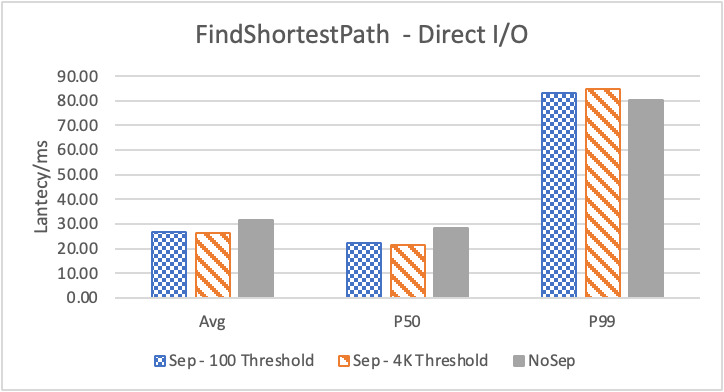
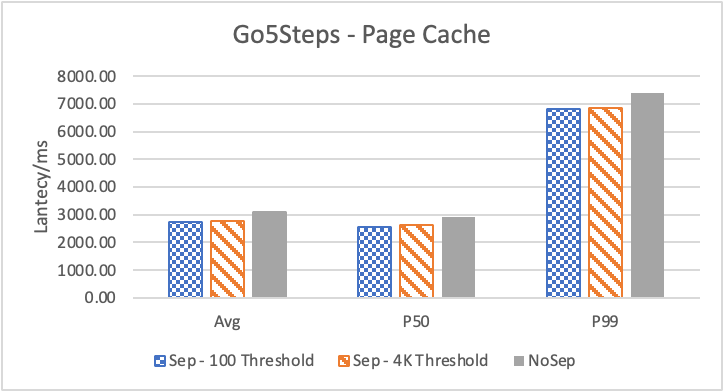
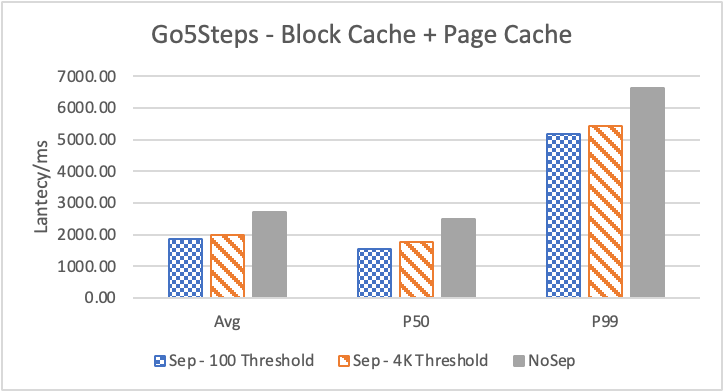
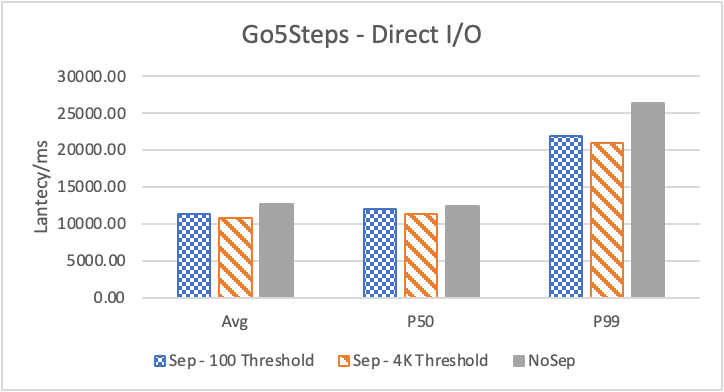
图 6. KV 分离对于 KNOW 关系拓扑查询的性能影响
| Test | Avg reduction | P50 reduction | P99 reduction |
|---|---|---|---|
| Go 1 Step | 0.9% | 1.0% | 0.7% |
| Go 2 Step | 4.7% | 5.3% | 5.1% |
| Go 3 Step | 15.9% | 21.4% | 9.4% |
| Go 5 Step | 11.2% | 12.2% | 7.9% |
| FSP | 6.8% | 10.1%2.7% |
表 3a. KV 分离对于 KNOW 关系拓扑查询的延迟减少(Page Cache)
| Test | Avg reduction | P50 reduction | P99 reduction |
|---|---|---|---|
| Go 1 Step | 1.2% | 1.1% | 1.5% |
| Go 2 Step | 8.3% | 10.0% | 7.1% |
| Go 3 Step | 26.8% | 43.2% | 29.6% |
| Go 5 Step | 31.7% | 38.3% | 21.6% |
| FSP | 8.6% | 12.4% | 3.9% |
表 3b. KV 分离对于 KNOW 关系拓扑查询的延迟减少(Block Cache + Page Cache)
| Test | Avg reduction | P50 reduction | P99 reduction |
|---|---|---|---|
| Go 1 Step | 1.1% | 1.0% | 1.8% |
| Go 2 Step | 14.3% | 15.0% | 12.4% |
| Go 3 Step | 17.4% | 17.8% | 16.0% |
| Go 5 Step | 10.5% | 3.0% | 17.2% |
| FSP | 15.8% | 21.7% | -3.6% |
表 3c. KV 分离对于 KNOW 关系拓扑查询的延迟减少(direct I/O)
图6 和表 3显示了 Nebula 对于 KNOW 关系查询的测试结果。针对数据集 Data2 的数据分布特性,我们测试了分别以 100B 和 4KB 作为 KV 分离的阈值。可以很明显地看到 KV 分离极大地提升了 Data2 的查询性能。对于图遍历深度较浅的查询( Go 1 Step),KV 分离的延迟降低比较少,在 100B 阈值下的 P50 延迟降低大约在 1%。但对于更深的查询,其提升就非常明显了,比如:对于 Go 3 Step,在使用大 Block Cache 下(表 3.b),在 100B 阈值下 P50 延迟降低可以达到 43.2%。而寻找最短路径对于图的遍历的深度往往在 1 跳和多跳查询之间,因此其性能提升是多跳查询的平均。
注意这里 KV 分离在 Go 5 Step 并没有进一步的性能提升,可能因为对于更深的遍历,其主要瓶颈不在存储。相比于 KV 分离之于不分离的性能提升,100B 和 4KB 的阈值区别并不大。因此在表 3 中,我们以 100B 阈值为例展示了具体的延迟减少百分比。
另外,对于有 Cache 的情况下(Block 或 Page Cache),所有数据都可以缓存,此时 KV 分离性能比不分离性能更好,也说明 KV 分离后内存中的数据访问效率更高。具体的原因可能是 SST 本来就不是内存访问的最佳数据结构。因此小 LSM-Tree 相比大 LSM-Tree 带来的性能提升会比较明显。
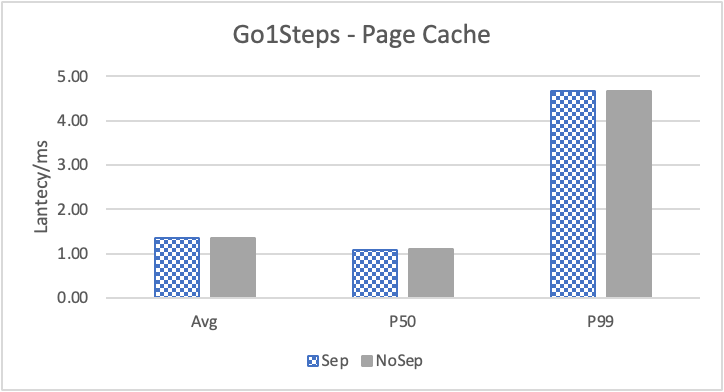
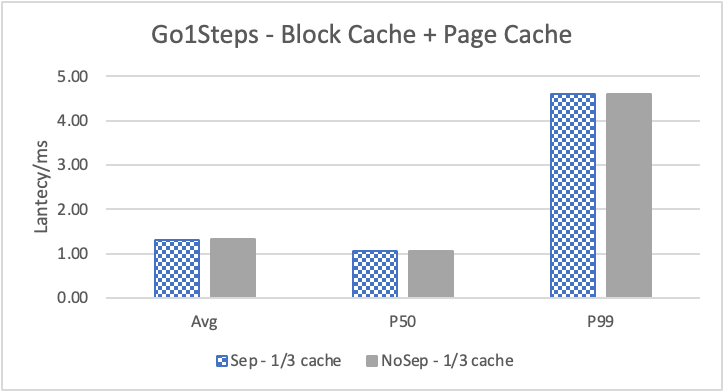
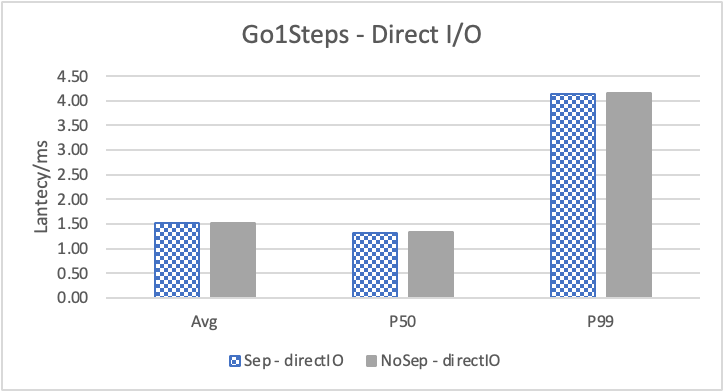
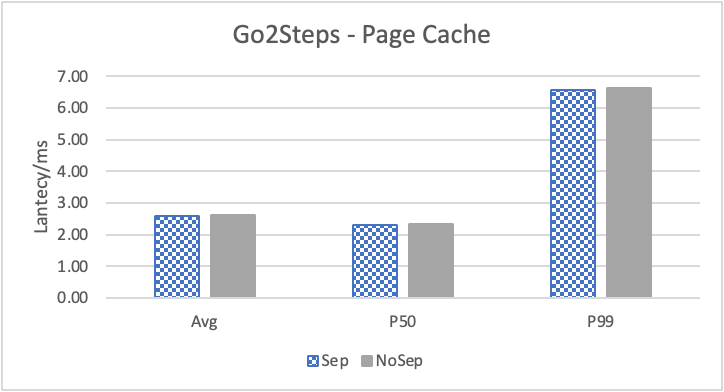
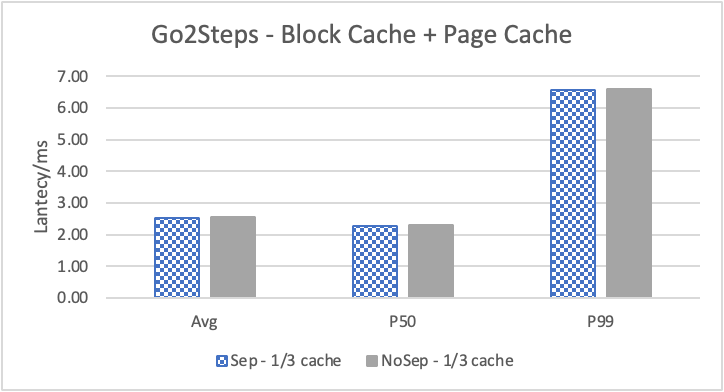
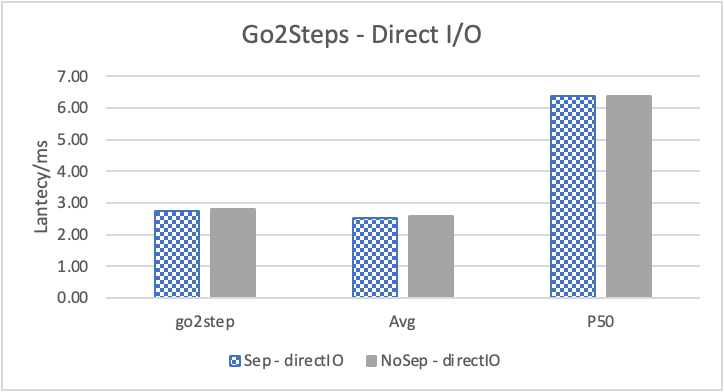
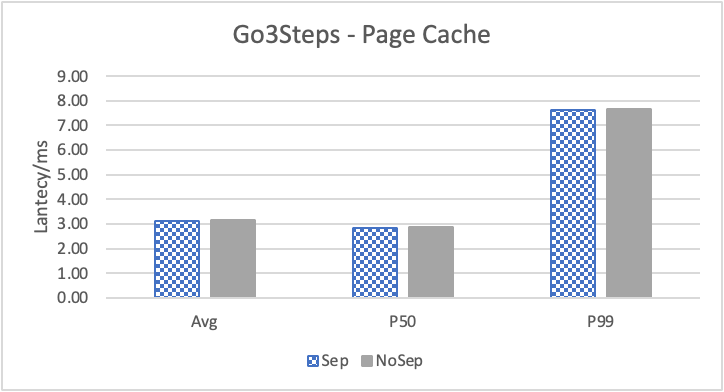
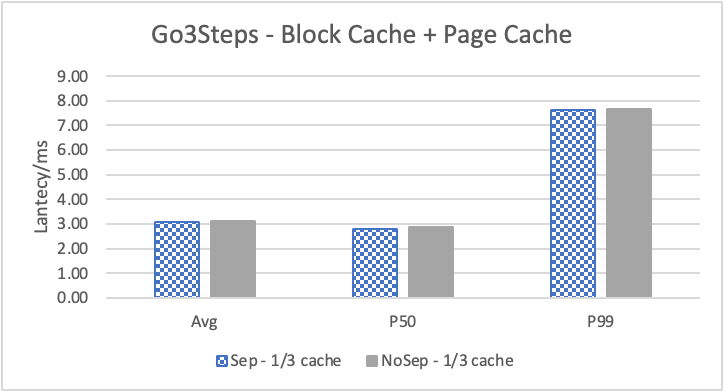
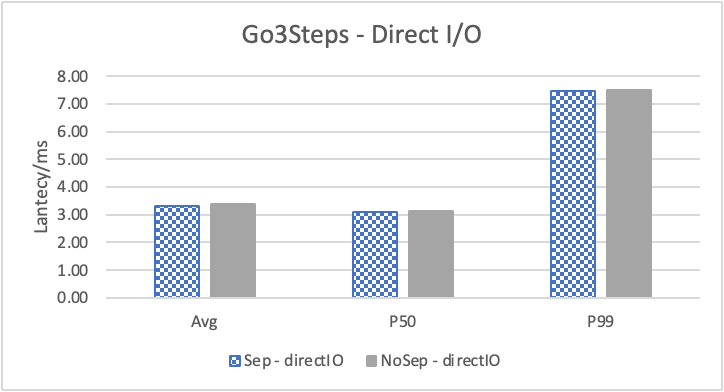
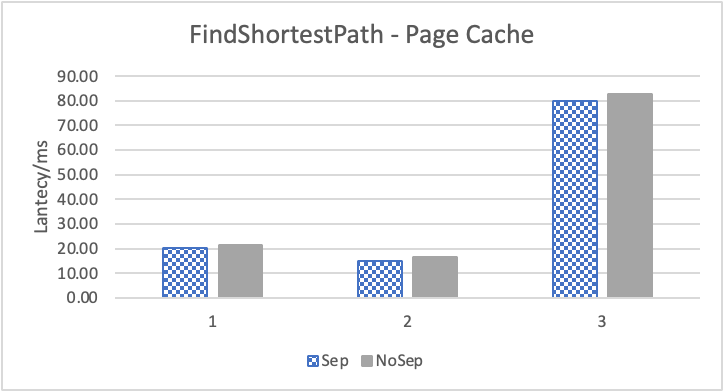
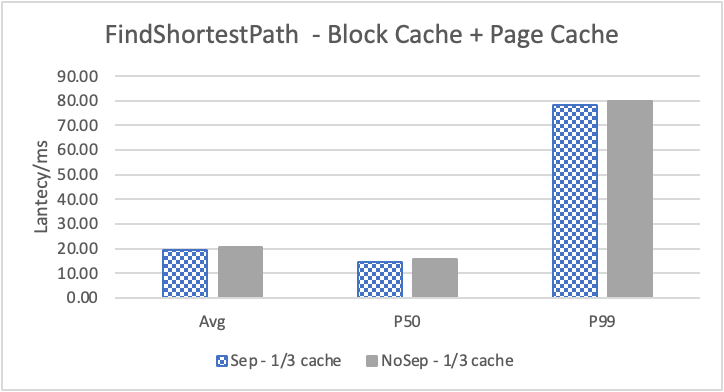
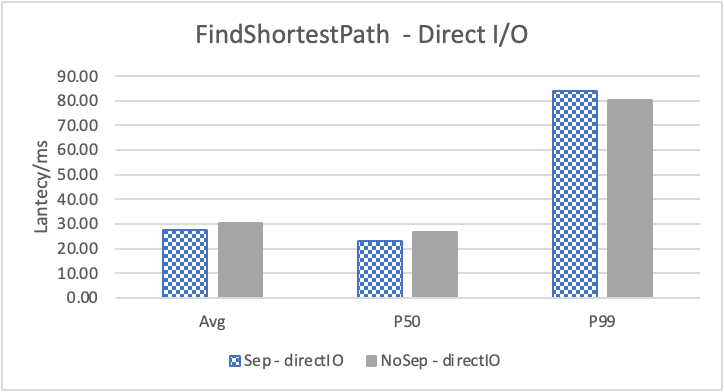
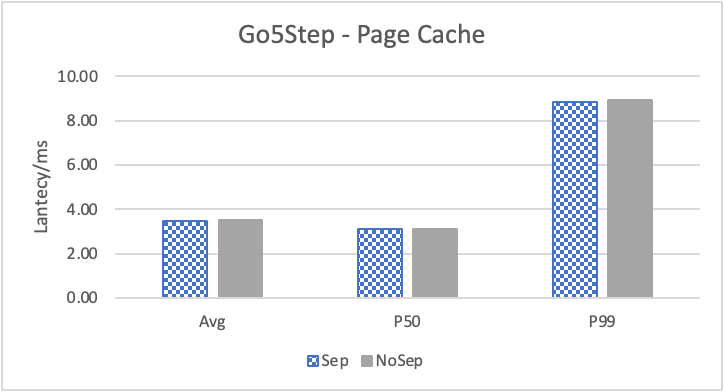
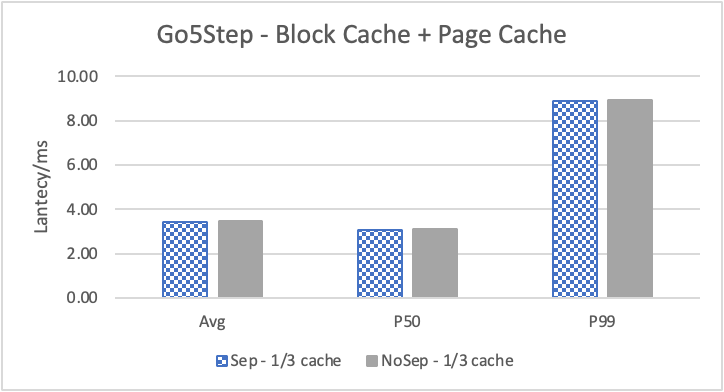
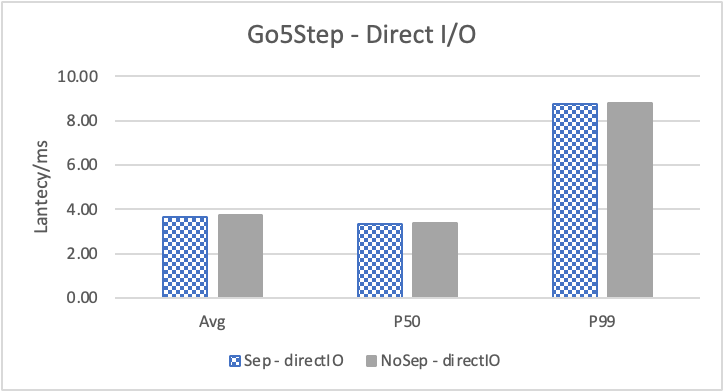
图 7. KV 分离对于 REPLY_OF 拓扑查询的性能 (注意这里 Go 3 Step 和 Go 5 Step 之间性能并没有多大差别。这是因为 Go 5 step 只有 0.6% 的查询返回了非 0 结果。因此 Go 5 Step 本质上不会比 Go 3 Step 多 walk 多少边。)
| Test | Avg reduction | P50 reduction | P99 reduction |
|---|---|---|---|
| Go 1 Step | 1.1% | 1.8% | 0.1% |
| Go 2 Step | 1.2% | 1.3% | 1.1% |
| Go 3 Step | 1.2% | 1.4% | 0.8% |
| Go 5 Step | 1.1% | 1.2% | 1.0% |
| FSP | 6.4% | 9.1% | 3.3% |
表 4a. KV 分离对于 REPLY_OF 关系拓扑查询的延迟减少(Page Cache)
| Test | Avg reduction | P50 reduction | P99 reduction |
|---|---|---|---|
| Go 1 Step | 0.8% | 0.9% | 0.2% |
| Go 2 Step | 1.2% | 1.4% | 0.2% |
| Go 3 Step | 1.3% | 1.6% | 0.4% |
| Go 5 Step | 1.3% | 1.6% | 0.7% |
| FSP | 5.4% | 8.0% | 2.4% |
表 4b. KV 分离对于 REPLY_OF 关系拓扑查询的延迟减少(Block Cache + Page Cache)
| Test | Avg reduction | P50 reduction | P99 reduction |
|---|---|---|---|
| Go 1 Step | 1.2% | 1.4% | 0.2% |
| Go 2 Step | 1.3% | 1.7% | 0.0% |
| Go 3 Step | 1.3% | 1.5% | 0.6% |
| Go 5 Step | 1.8% | 2.0% | 0.7% |
| FSP | 5.4% | 13.3% | -4.3% |
表 4c. KV 分离对于 REPLY_OF 关系拓扑查询的延迟减少(direct I/O)
图 7. 和表 4. 展示了对于 REPLY_OF 关系的查询结果。此时,可以看到 KV 分离虽然性能提升效果不明显,但也是有确定的提升的。注意这里 Go 3 Step 和 Go 5 Step 之间性能并没有多大差别。这是因为 Go 5 Step 只有 0.6% 的查询返回了非 0 结果。因此 Go 5 Step 本质上不会比 Go 3 Step 多 walk 多少边。注意这里由于性能差别不大,我们只展示了 4K 阈值下 KV 分离和不分离的对比情况。
3.4 点的属性查询性能
在这部分,我们来测试 KV 分离对于属性(值)查询的性能影响。按照 KV 分离的理论,传统的 LSM-Tree 对于读性能的影响主要来源于读放大。而读放大要通过 GET 操作才能体现得明显。而属性查询恰好能体现读放大的影响。
首先,我们测试对于点的属性查询。同上,测试分为对于小 value 和大 value 进行 walk。
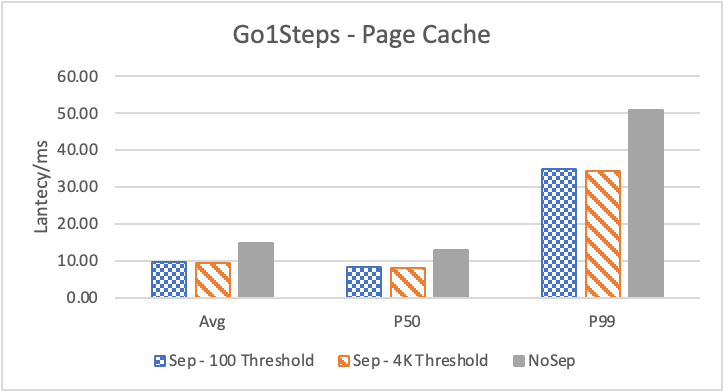
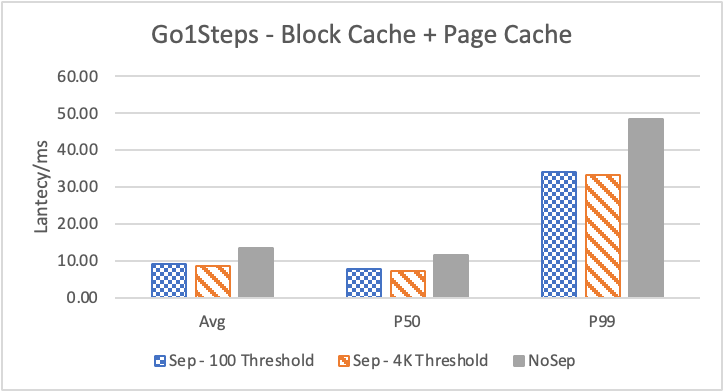
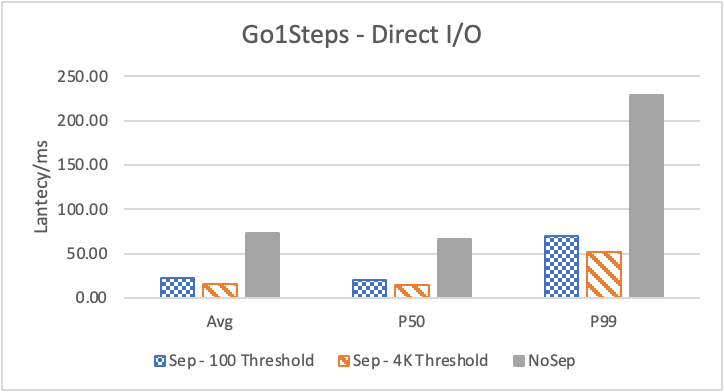
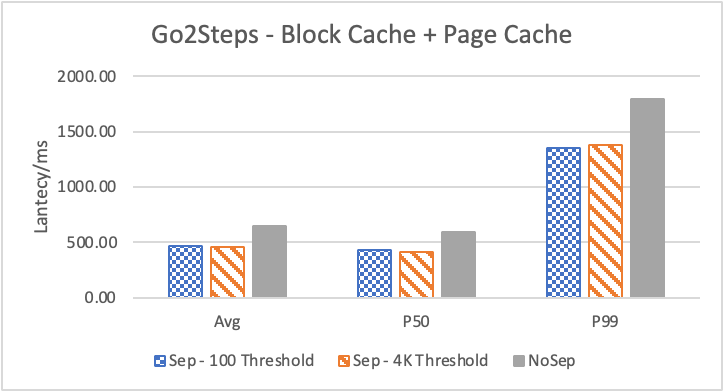
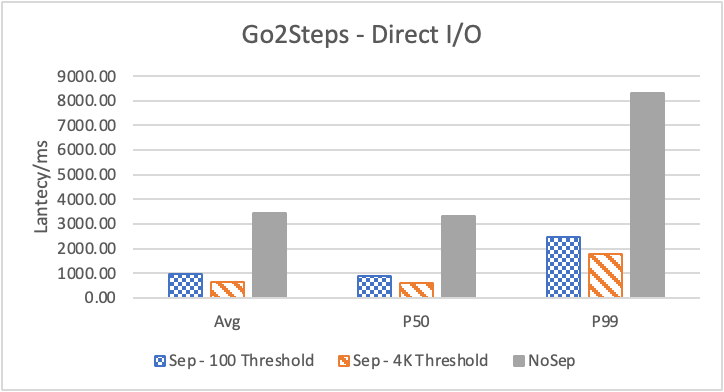
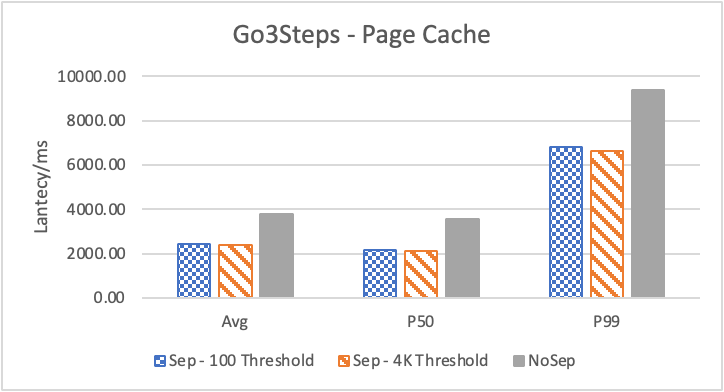
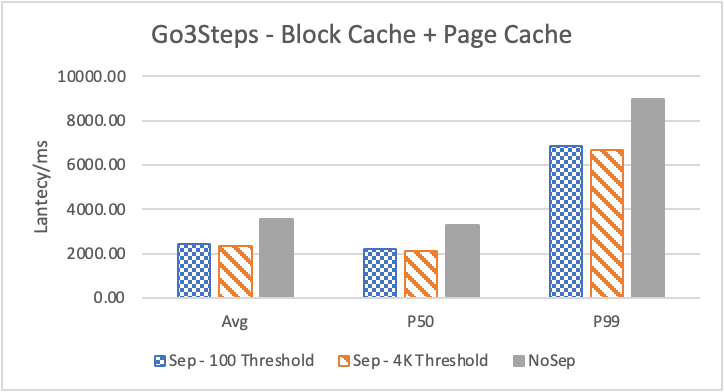
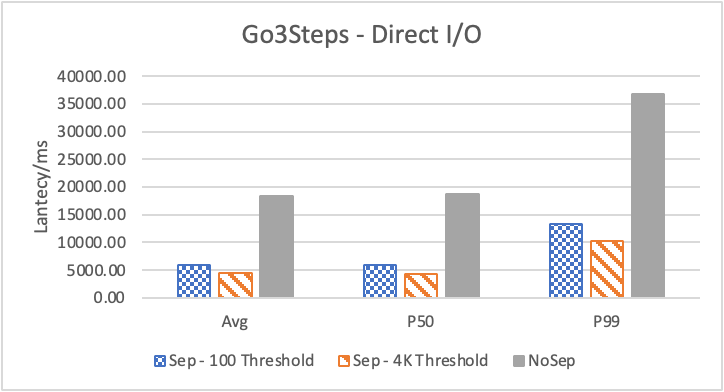
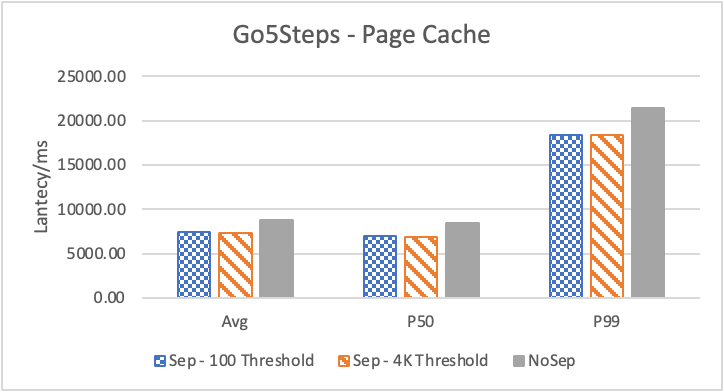

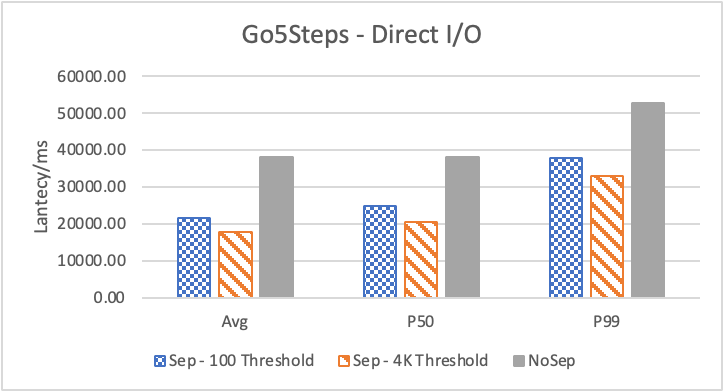
图 8. KV 分离对于小 value 属性查询的性能
| Test | Avg reduction | P50 reduction | P99 reduction |
|---|---|---|---|
| Go 1 Step | 36.2% | 37.6% | 32.4% |
| Go 2 Step | 34.0% | 35.5% | 28.6% |
| Go 3 Step | 37.4% | 40.3% | 29.3% |
| Go 5 Step | 1.8% | 2.0% | 0.7% |
| FSP | 16.3% | 19.0% | 14.3% |
表 5a. KV 分离对于小 value 属性查询的延迟减少(Page Cache)
| Test | Avg reduction | P50 reduction | P99 reduction |
|---|---|---|---|
| Go 1 Step | 35.6% | 37.8% | 31.6% |
| Go 2 Step | 29.6% | 31.1% | 23.4% |
| Go 3 Step | 33.8% | 36.0% | 25.4% |
| Go 5 Step | 19.1% | 33.5% | 9.9% |
表 5b. KV 分离对于小 value 属性查询的延迟减少(Block Cache + Page Cache)
| Test | Avg reduction | P50 reduction | P99 reduction |
|---|---|---|---|
| Go 1 Step | 78.6% | 78.9% | 77.9% |
| Go 2 Step | 80.8% | 81.3% | 78.7% |
| Go 3 Step | 75.8% | 77.3% | 72.1% |
| Go 5 Step | 53.2% | 46.3% | 37.5% |
表 5c. KV 分离对于小 value 属性查询的延迟减少(direct I/O)
图 8 和表 5 显示了 KV 分离对于小 value 进行 walk 并返回值(属性)查询的性能影响。这是通过对 KNOW 关系进行查询并返回节点属性实现的。我们可以看到以 4K 为阈值情况下,KV 分离 P50 延迟降低可以达到 81.3%,而 P99 延迟降低可以达到 78.7%。这主要得益于对于 KV 分离对于点查询的性能提升巨大,这也和 RocksDB 对于 KV 分离的测试结果一致。另外,可以看到 KV 分离对于 direct I/O 的性能提升最大。这是因为 KV 分离对读性能的提升主要来源于读放大的减少和 Cache 命中率的提升。但由于磁盘 I/O 性能远小于内存访问,所以读放大的减小对于性能提升更加明显。而读放大只在产生 I/O 的情况下才会产生。所以这里 direct I/O 主要是体现读放大的减小对于性能的提升。
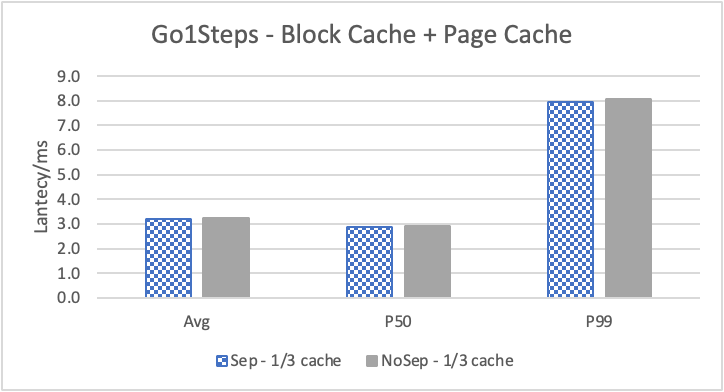
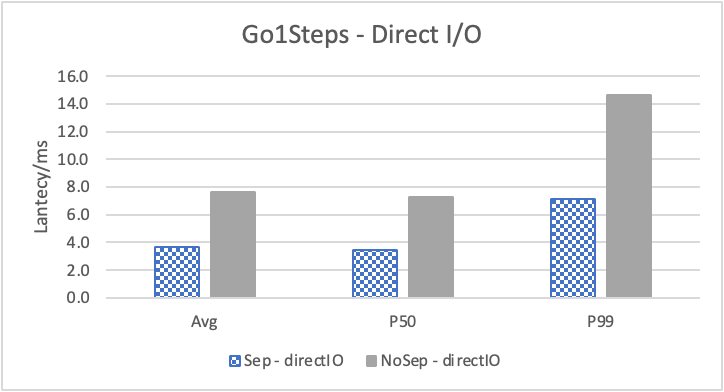
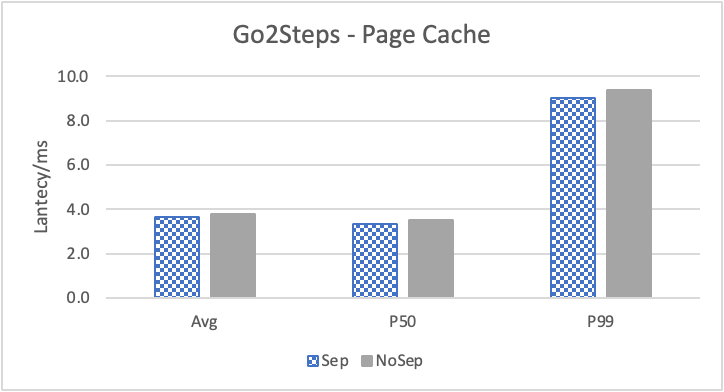
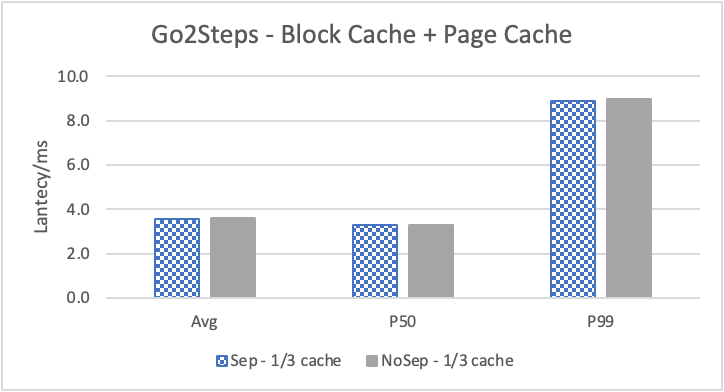
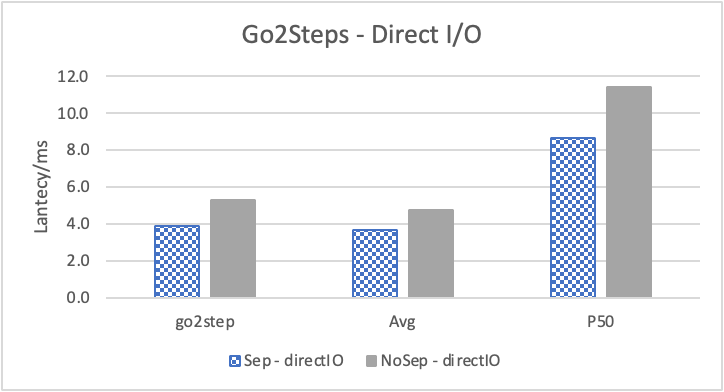
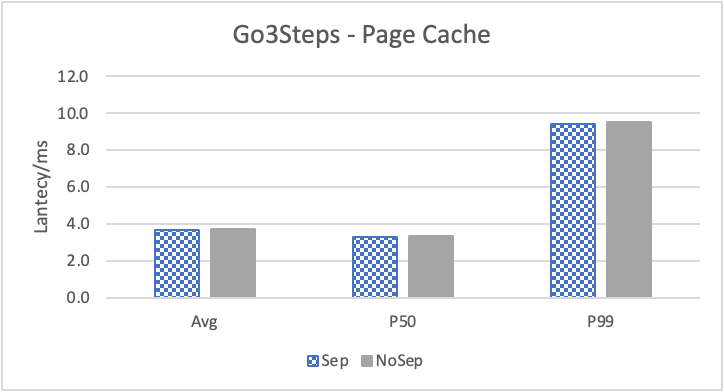
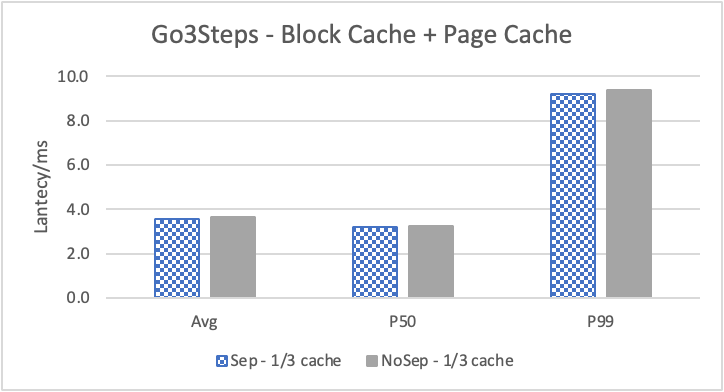
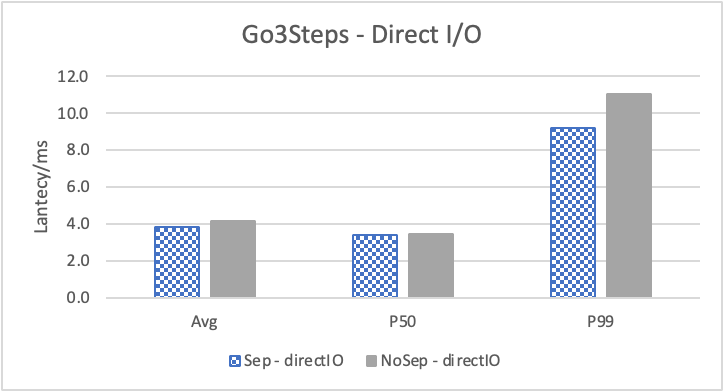
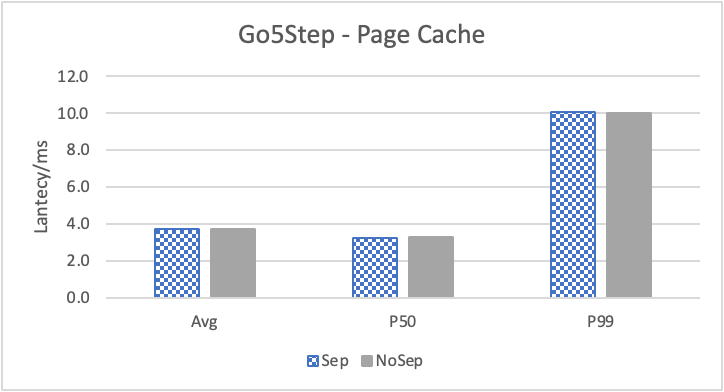
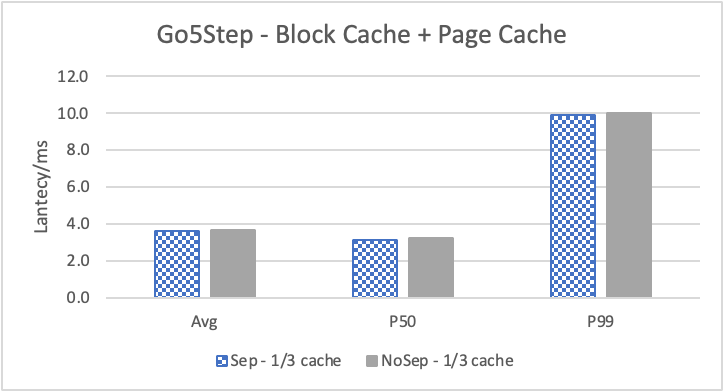
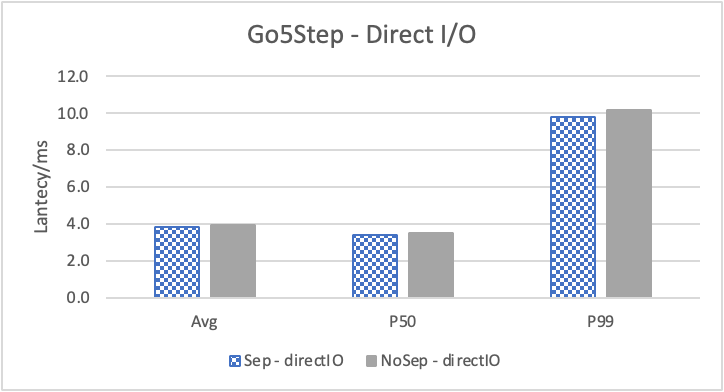
图 9. KV 分离对于大 value 属性查询的性能
| Test | Avg reduction | P50 reduction | P99 reduction |
|---|---|---|---|
| Go 1 Step | 7.1% | 6.7% | 8.8% |
| Go 2 Step | 3.8% | 4.2% | 3.8% |
| Go 3 Step | 1.9% | 1.8% | 1.6% |
| Go 5 Step | 0.5% | 1.0% | -0.6% |
表 6a. KV 分离对于大 value 属性查询的延迟减少(Page Cache)
| Test | Avg reduction | P50 reduction | P99 reduction |
|---|---|---|---|
| Go 1 Step | 0.7% | 0.5% | 1.3% |
| Go 2 Step | 0.9% | 0.9% | 1.0% |
| Go 3 Step | 1.5% | 1.6% | 1.6% |
| Go 5 Step | 1.4% | 1.7% | 1.0% |
表 6b. KV 分离对于大 value 属性查询的延迟减少(Block Cache + Page Cache)
| Test | Avg reduction | P50 reduction | P99 reduction |
|---|---|---|---|
| Go 1 Step | 52.3% | 52.5% | 51.1% |
| Go 2 Step | 26.4% | 22.9% | 24.3% |
| Go 3 Step | 7.6% | 1.0% | 16.8% |
| Go 5 Step | 2.4% | 2.4% | 3.8% |
表 6c. KV 分离对于大 value 属性查询的延迟减少(direct I/O)
图 9 和表 6 通过对 REPLY_OF 关系进行 walk 并返回终点 value,体现了 KV 分离对于读取大 value 性能的影响。此时 KV 分离在比较浅的遍历的时候,性能提高反而较大,而对于较深的遍历没有太多影响。这主要是因为对于 REPLY_OF 关系,99.99% 的查询存在 1 跳及以上关系、只有 50.7 %的数据之间存在 2 跳及以上关系、只有 16.8% 的数据之间存在 3 跳及以上关系。因此随着查询跳数上升,需要实际去 GET 属性的查询比例反而减少。因此对于实际 GET property 比例最高的查询 Go 1 Step,KV 分离对于其性能提升反而最多。而对于其他查询,KV 分离对于性能的影响会更接近于 3.3 节中对于 REPLY_OF 关系的拓扑查询。
3.5 边的属性查询性能
再来测试对于边属性的查询性能。根据之前的测试结果,我们知道 REPLY_OF 边连接的深度比较浅,较深的查询也会退化成浅查询。因此,这里我们仅关注对于 KNOW 关系的边属性查询。
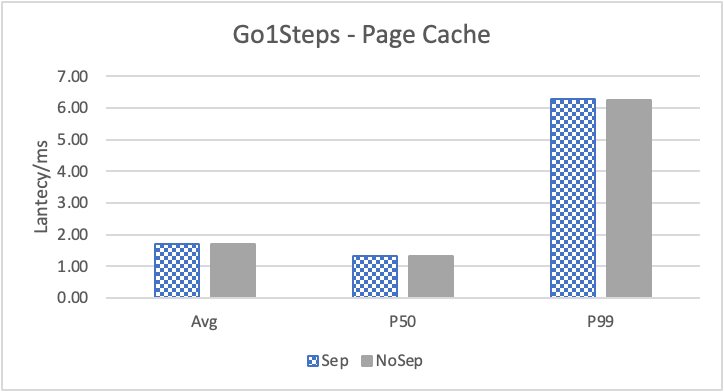
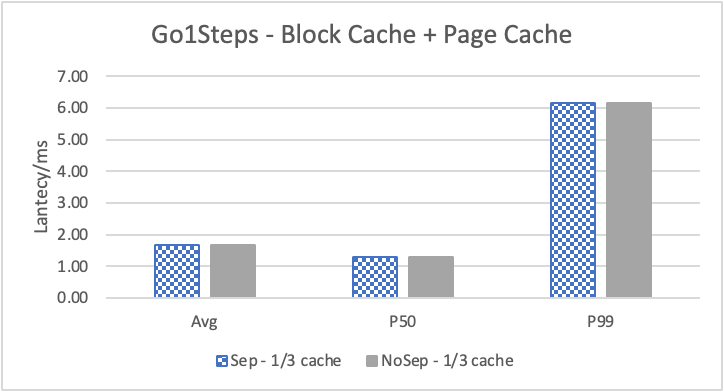
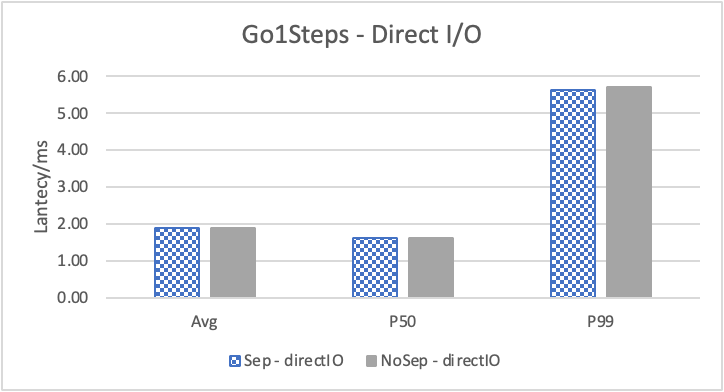
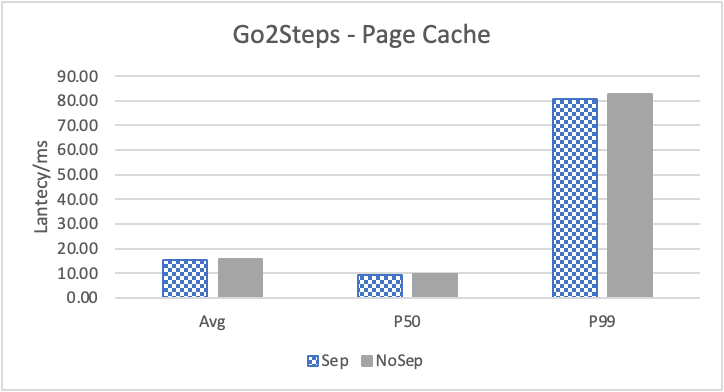
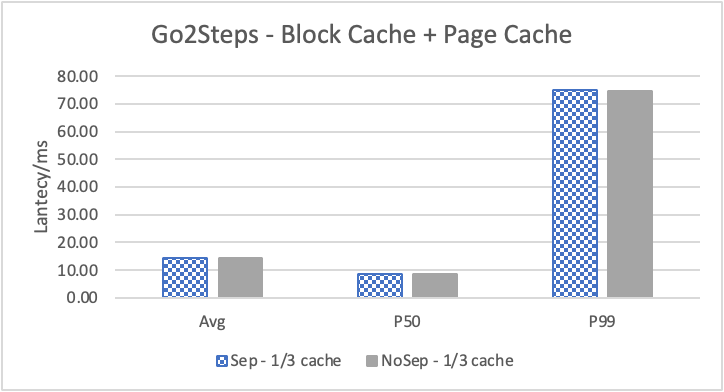
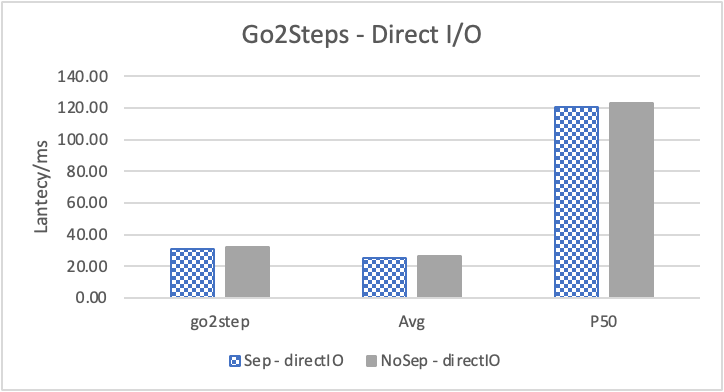
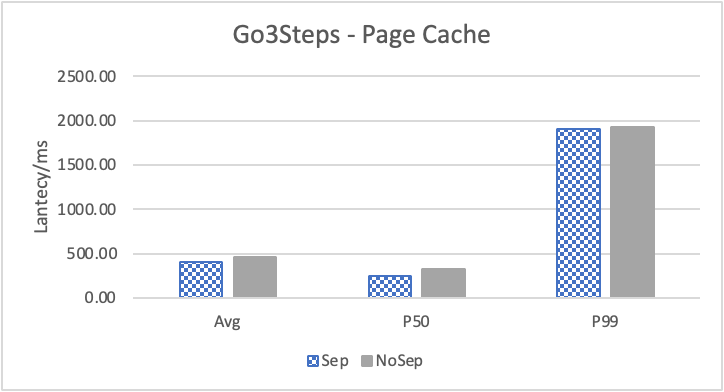
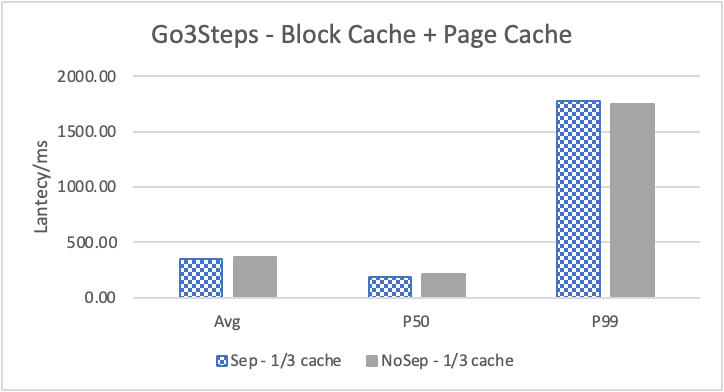
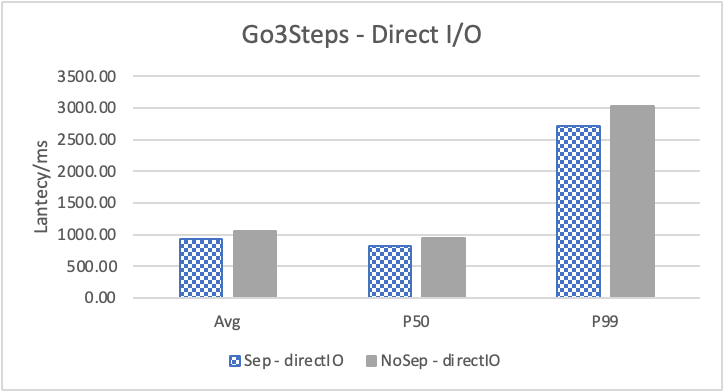
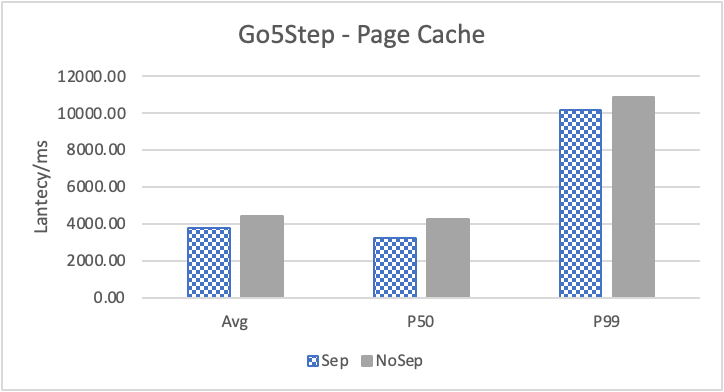
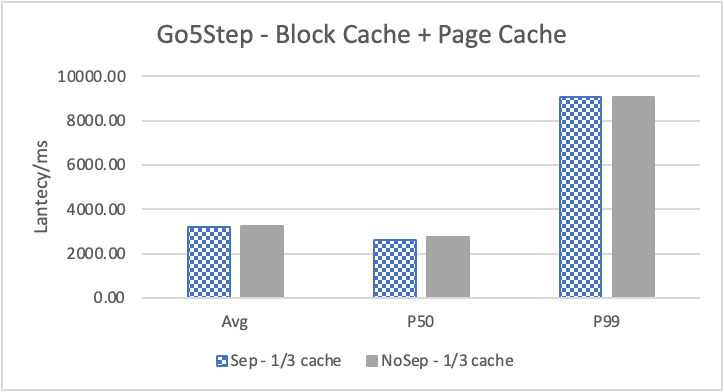
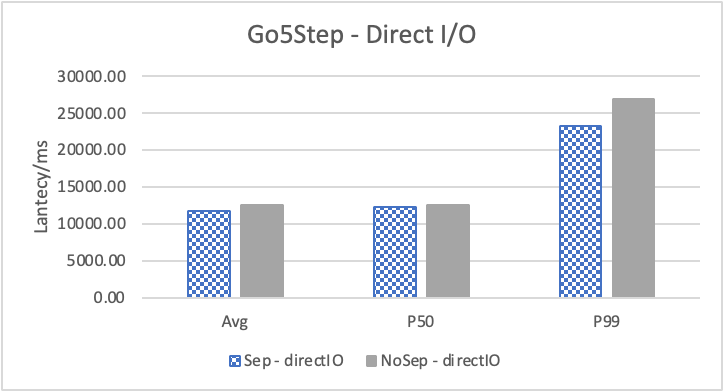
图 10. KV 分离对于边属性查询的性能影响
| Test | Avg reduction | P50 reduction | P99 reduction |
|---|---|---|---|
| Go 1 Step | 0.5% | 0.6% | -0.5% |
| Go 2 Step | 3.3% | 4.2% | 2.8% |
| Go 3 Step | 11.4% | 25.8% | 1.2% |
| Go 5 Step | 15.0% | 24.3% | 6.6% |
表 7a. KV 分离对于边属性查询的延迟减少(Page Cache)
| Test | Avg reduction | P50 reduction | P99 reduction |
|---|---|---|---|
| Go 1 Step | 0.0% | 0.2% | 0.1% |
| Go 2 Step | -0.3% | -0.1% | -0.6% |
| Go 3 Step | 4.2% | 13.0% | -1.7% |
| Go 5 Step | 0.7% | 4.7% | -0.1% |
表 7b. KV 分离对于边属性查询的延迟减少(Block Cache + Page Cache)
| Test | Avg reduction | P50 reduction | P99 reduction |
|---|---|---|---|
| Go 1 Step | 0.5% | 0.2% | 1.4% |
| Go 2 Step | 4.0% | 4.9% | 2.1% |
| Go 3 Step | 12.5% | 12.9% | 10.2% |
| Go 5 Step | 6.9% | 1.2% | 13.4% |
表 7c. KV 分离对于边属性查询的延迟减少(direct I/O)
图 10 和表 7 显示了测试结果。可以看出此种情况下 KV 分离的性能提升大大降低。因为在 LDBC 数据集中,边上的属性只有 creationDate,小于测试中 KV 分离的阈值 100B。因此无论是否使用 KV 分离,边上的属性都存储在 LSM-Tree 上。只是 KV 分离后,LSM-Tree 的大小变小,Cache 效率更高。因此,KV 分离对于 LDBC 数据集中的边上属性查询性能提升较小。
3.6 数据插入的性能
这里,我们也测试下 KV 分离对于数据插入的性能影响。由于 Cache 对于 RocksDB 的 PUT 的性能影响不大,这里只测试了只有 OS Page Cache 的场景。我们继续使用数据集 Data2,并且每次插入查询都运行 10 分钟,以确保 Compaction 会被触发。
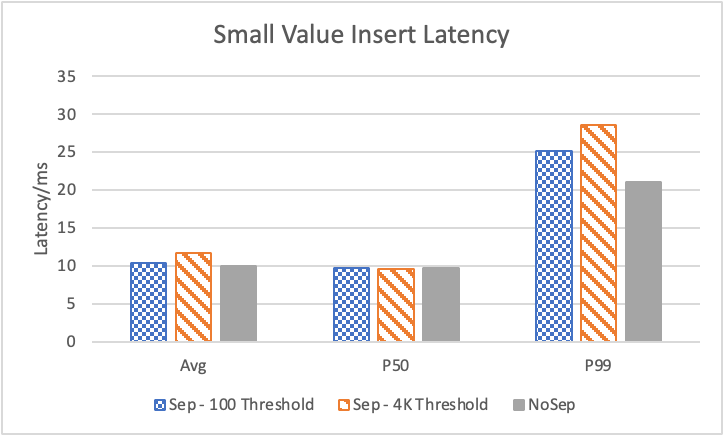
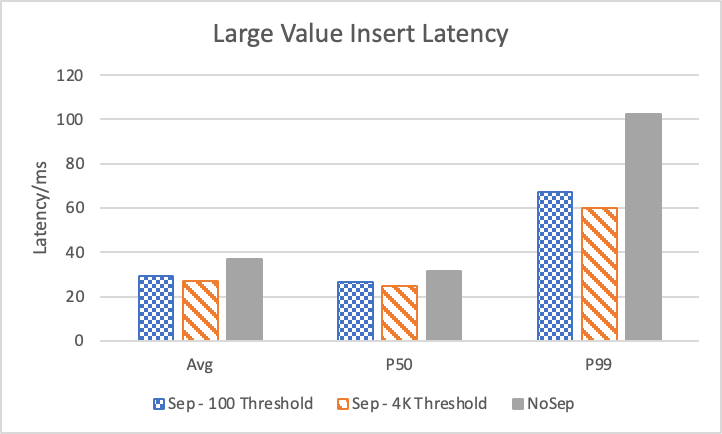
图 11. KV 分离对数据插入的性能影响
图 11 显示了数据插入性能。一个是插入 Person 数据,属于小 value。另一个是插入 Comment 数据 (至少4KB),属于大 value。我们可以看到 KV 分离对于插入大 value 具有比较明显的性能提升。其收益主要来自于更少的 Compaction。而对于小 value 的插入,由 PUT 导致的写放大在 RocksDB 中并不明显。但另一方面,在每一个 KV Flush 到 L0 的时候,KV 分离带来的额外一次写的开销(需要同时写 SST 和 Blob)却比较明显。因此,在 value 比较小的时候,KV 分离的写性能会受影响。
3.7 如果我的数据集全是小 Value?
我们已经知道如果数据集中有大 value,那么无论是拓扑查询还是值查询,KV 分离都能带来巨大的性能提升。那如果没有大 value 呢?是否存在副作用?
这一节我们测试了 KV 分离对于没有大 value 情况的性能影响。
首先需要注意的是,KV 分离并不是在任何时候都能对 RocksDB 带来性能提升。尤其在小 value 情况下, Range Query 性能是会变差的。我们这里测试也不会覆盖所有小 value 的情况。我们选择使用数据集 Data1,针对默认的 LDBC 数据进行测试。
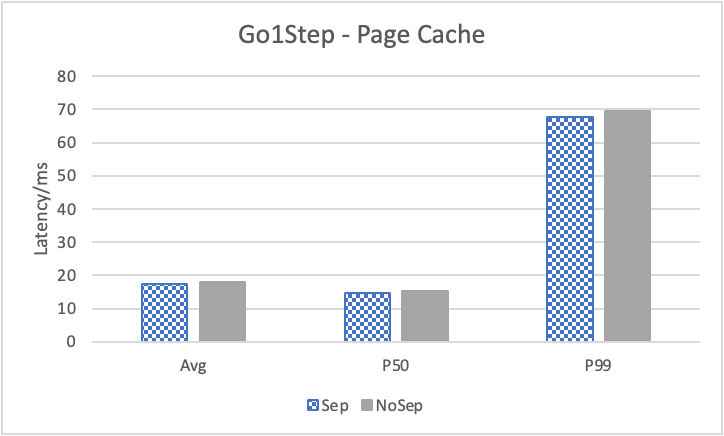
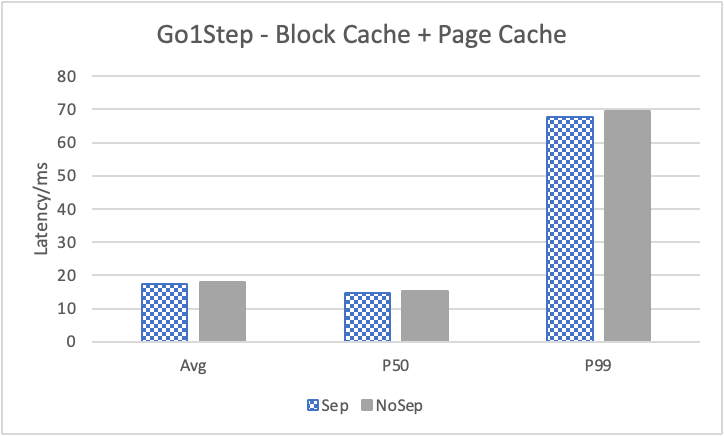
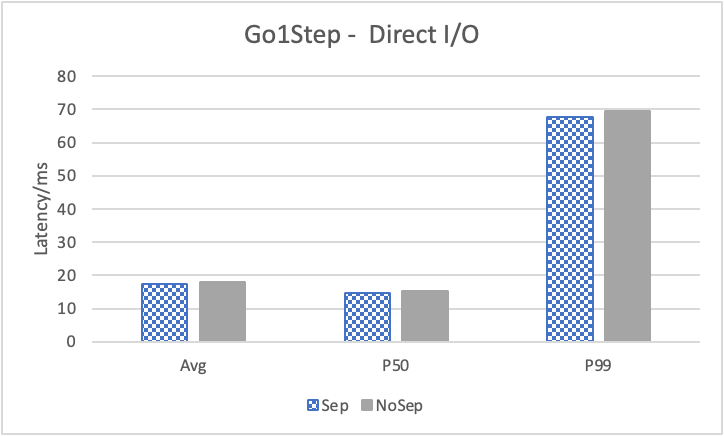
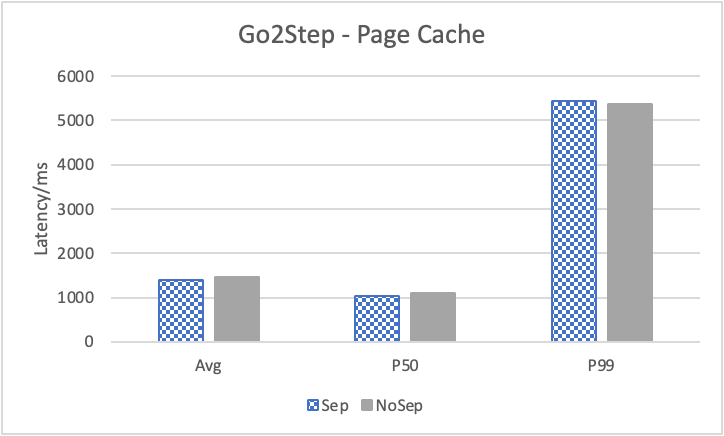
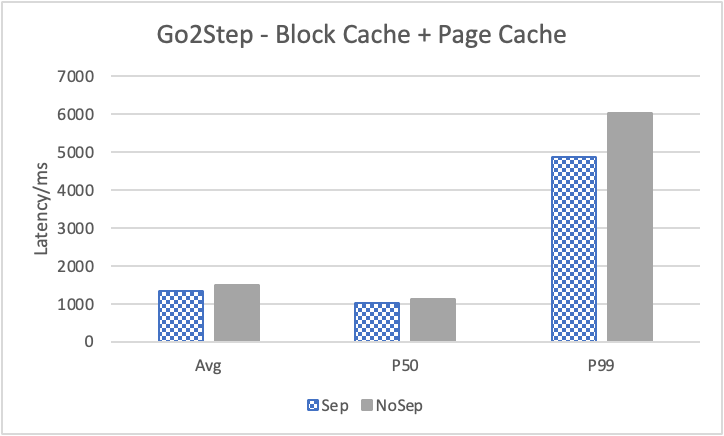
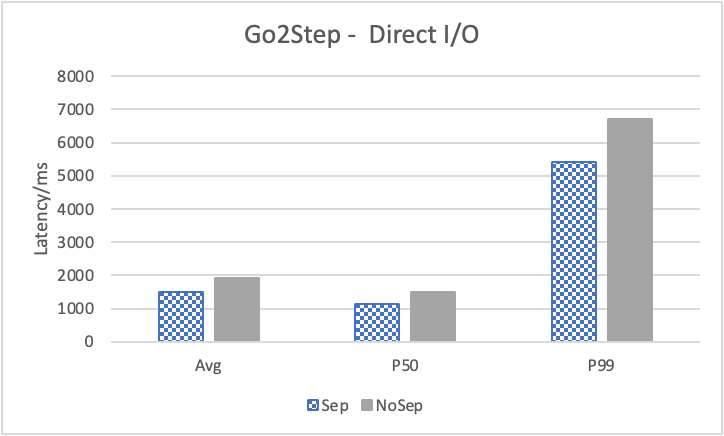
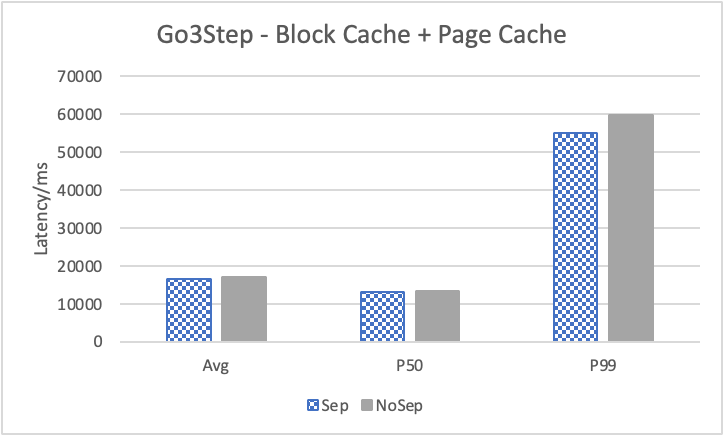
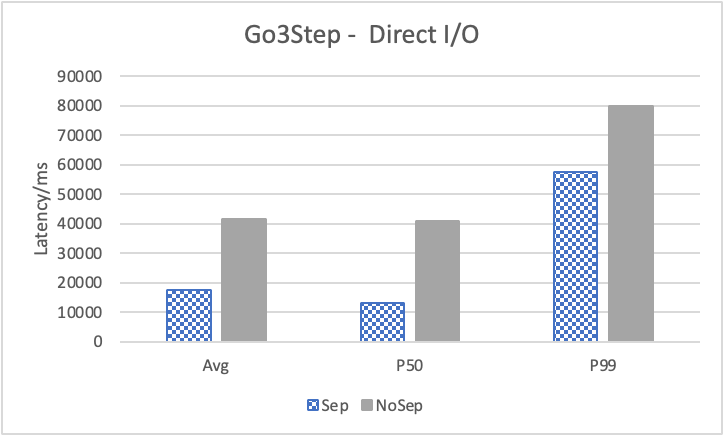
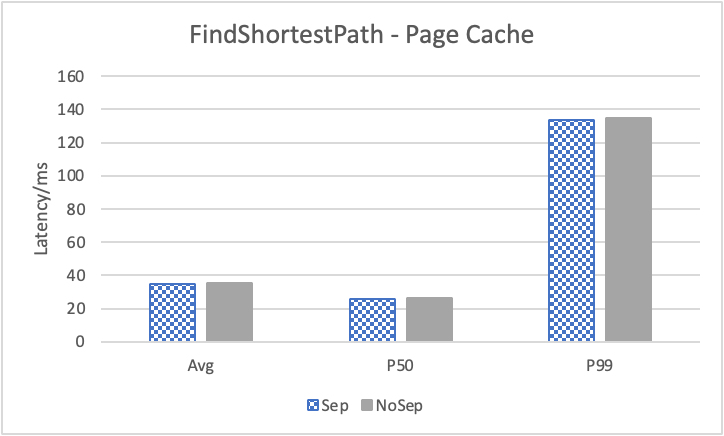
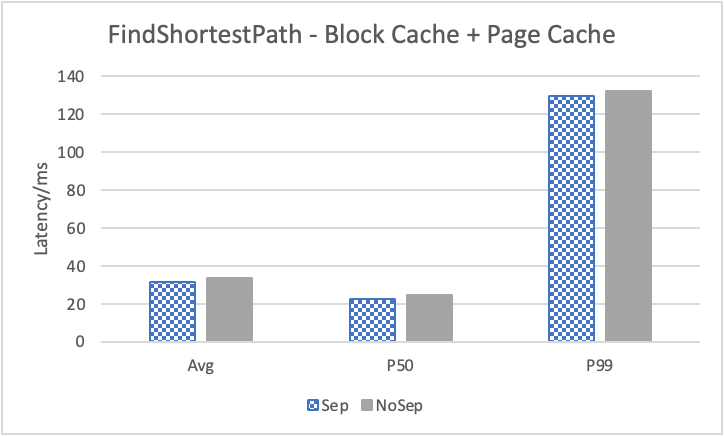
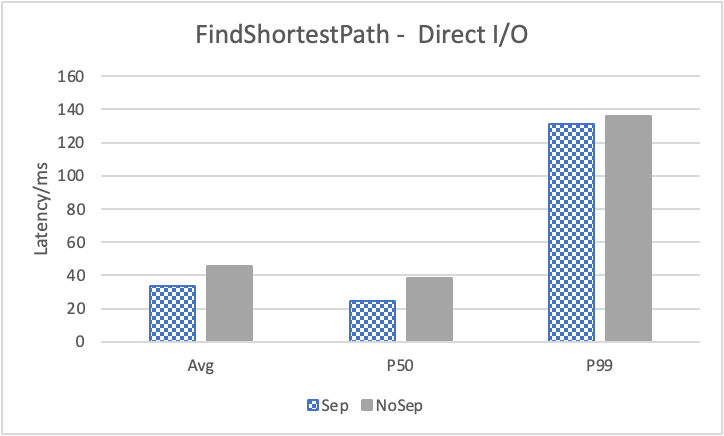
图 12. KV 分离对小 value 拓扑结构和属性查询的性能影响
| Test | Avg reduction | P50 reduction | P99 reduction |
|---|---|---|---|
| Go 1 Step | 3.2% | 3.5% | 2.5% |
| Go 2 Step | 5.1% | 7.0% | -1.4% |
| Go 3 Step | 2.1% | 3.5% | 0.4% |
| Go 5 Step | 2.6% | 3.7% | 1.1% |
表 9a. 所有小 value 查询的延迟降低
| Test | Avg reduction | P50 reduction | P99 reduction |
|---|---|---|---|
| Go 1 Step | 0.2% | -1.5% | 7.7% |
| Go 2 Step | 11.2% | 9.3% | 19.2% |
| Go 3 Step | 3.4% | 1.6% | 8.2% |
| FSP | 5.9% | 8.3% | 1.9% |
表 9b. 所有小 value 查询的延迟降低
| Test | Avg reduction | P50 reduction | P99 reduction |
|---|---|---|---|
| Go 1 Step | 17.8% | 19.1% | 15.1% |
| Go 2 Step | 22.2% | 24.9% | 19.1% |
| Go 3 Step | 58.1% | 68.1% | 28.1% |
| FSP | 26.2% | 35.6% | 3.2% |
表 9c. 所有小 value 查询的延迟降低
图 12 展示了在全是小 value 情况下,将 KV 分离的阈值置成 100B 的性能。其中,在 Go 1 Step、Go 2 Step、Go 3 Step 中,我们提取了目标节点的属性,是属性查询,FindShortestPath 是不返回值的拓扑查询。可以看到,虽然性能提升不如数据集 Data2,但是延迟也是有降低的,在 direct I/O 情况下尤为明显。注意,我们这里没有展示 Go 5 Step,因为 Go 5 Step 的压力测试中出现了超时情况,因此测试结果不准确。
总之,我们证明了无论是大 value 还是小 value,拓扑查询还是值查询,KV 分离都是能带来性能提升的。
4. 结论
我们提出使用 KV 分离来存储图数据库:将值较小的数据存在 LSM-Tree 中,而将值较大的数据存在 log 中。这样由于大 value 并不存在 LSM-Tree中,LSM-Tree 的高度可能因此降低,增加 Cache 的可能性,从而提高读性能。哪怕不考虑 Cache,KV 分离带来的读写放大的减少也能加快读写速度。在我们的测试实验中,我们发现 KV 分离对于图查询的性能具有巨大提升。对于小 value 的查询延迟降低可以高达 80.7%。而对于大 value 的查询,延迟降低相对较少,但也可以达到 52.5%。考虑到大部分大 value 的数据是冷而且占绝大多数的,因此总体性能的提升将更接近于对于小 value 的查询。从 Nebula Graph 3.0.0版本开始,可以通过 nebula-storaged 的配置文件来配置 KV 分离的功能。
共同学习,写下你的评论
评论加载中...
作者其他优质文章


