
一提到日志收集方案,大家第一个想到的肯定是ELK(Elasticsearch、Logstash、Kibana ),但Logstash依赖于JVM不管是性能还是简介性,都不是日志收集agent的首选。
个人感觉一个好的agent应该是资源占用少,性能好,不依赖别的组件,可以独立部署。而Logstash明显不符合这几点要求,也许正是基于这些考虑elastic推出了一个新的组件Filebeat。
我们这边收集日志应对的场景主要是:文本日志、docker日志、k8s日志,恰恰这些EFK全家桶都支持。
我们希望日志收集产品可以满足以下几个需求:
按照项目、应用维度检索日志(因为大家检索日志的时候,肯定是检索某个应用的日志)
支持检索出某条想要的日志后,可以查看上下文(查看该日志所在日志文件的前后多少条)
支持日志下载(目前支持两种场景:搜过结果的下载、某条日志所在日志文件的下载)
支持自动化部署Filebeat,部署过程可视化
基于需求及ELK套件,梳理我们场景中特有的东西:
docker日志的场景比较单一,都是通过之前一个产品A发布部署的,其docker命名规则比较统一,可以通过docker.container.name截取来获取应用名字
k8s场景也比较统一,都是通过之前一个产品B发布部署的,其pod命名规则比较统一,可以通过kubernetes.pod.name截取来获取应用名字
文本日志,我们强制要求log文件的上层目录必须是应用名,因此,也可以截取到应用名称。
其实,我们不太推荐写日志,写到文本文件中,使用标准输出就好。
到这里可以发现我们可以选择Filebeat来作为日志的收集端,Elasticsearch来存储日志并提供检索能力。
那么,日志的清洗在哪里做呢?
日志的清洗一般有两种方式:
先把日志收集到kafka,再通过Logstash消费kafka的数据,来清洗数据
直接通过Elasticsearch的[Ingest Node]来清洗数据,因为Ingest Node也支持Grok表达式
对于,我们的场景而言,我们需要清洗数据的要求比较简单,主要是应用名称的截取还有文本日志中日志时间的处理(@timestamp重置,时区处理),所以我们选择了方案2。
其实,选择方案二还有个原因就是:系统在满足需求的同时,尽量保持简单,减少依赖的组件。
到这里可以,可以看出我们的架构基本如下: 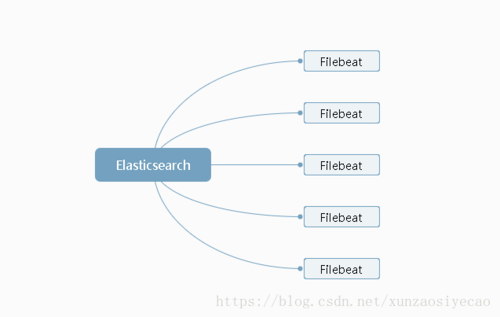
在我们的方案中,并没有提供Kibana 的界面直接给用户用,而是我们自己根据需要独立开发的。
代码架构: 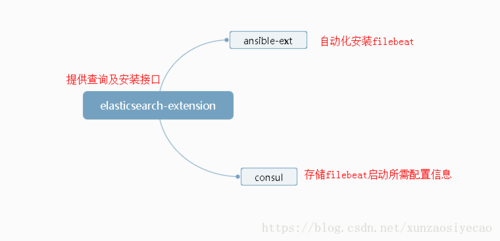
elasticsearch-extension提供的功能可以参见github:elasticsearch-extension
如果日志需要清洗的比较多,可以采用方案1,或者先不清洗,先把数据落到Elasticsearch,然后在查询的时候,进行处理。比如在我们的场景中,可以先把日志落到Elasticsearch中,然后在需要检索应用名称的时候,通过代码来处理并获取app名字。
原文出处:https://blog.csdn.net/jiankunking/article/details/81806573
共同学习,写下你的评论
评论加载中...
作者其他优质文章



