

-
int * p = (int *)malloc(2 * sizeof(int));
#include <stdio.h>
#include <stdlib.h>
int main(int argc,char **argv)
{
int * p = (int *)malloc(2 * sizeof(int));
if(p != nullptr){
free(p);
p = nullptr;
}
free(p);
return 0;
}查看全部 -
计算机硬件有两种储存数据的方式:大端字节序(big endian)和小端字节序(little endian)。
如果一个使用小端字节序的电脑上,这个整数的高字节就会存放在高地址上:
现在大部分的机器,都采用了小端字节序。但是在 IO 方面,则大部分使用大端字节序。例如,你要使用网络发送一个 int 类型的变量,要先把 int 转换成大端字节序,然后通过网络发送。
大端字节序又被称之为网络细节序。
查看全部 -
^ 异或
若参加运算的两个二进制位值相同则为0,否则为1。
<< 左移
各位全部左移若干位,高位丢弃,低位补 0 。
>> 右移
各二进位全部右移若干位,对无符号数,高位补 0 ,有符号数,各编译器处理方法不一样,有的补符号位,有的补 0 。
查看全部 -
你知道大端字节序和小端字节序吗?
字节序,就是 大于一个字节类型的数据在内存中的存放顺序。
计算机硬件有两种储存数据的方式:大端字节序(big endian)和小端字节序(little endian)。
我们现在有一个整数是258。用16进制表示是0x0102,然后我们把这个整数拆分成两个字节,第一个字节为 0000 0001,第二个字节为 0000 0010。
如果在一个使用大端字节序的电脑上,这个整数会被这样存放:
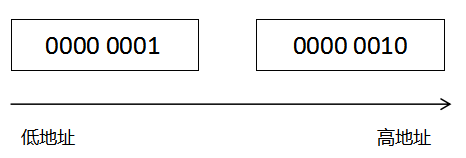
如果一个使用小端字节序的电脑上,这个整数的高字节就会存放在高地址上:
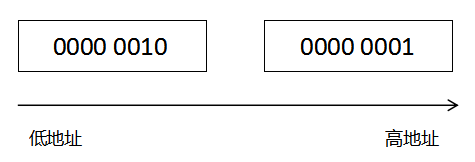
现在大部分的机器,都采用了小端字节序。但是在 IO 方面,则大部分使用大端字节序。例如,你要使用网络发送一个 int 类型的变量,要先把 int 转换成大端字节序,然后通过网络发送。
大端字节序又被称之为网络细节序。
查看全部 -
不一样的const关键字
C++ 中的 const 千变万化,之前我们已经学过使用 const 来做一个常量。const 在 C++ 中整体表示的语意是“不变的”,但是 const 申明在不同位置,却会有不一样的效果。这一小节,我们来集中学习一下 const。
const 修饰普通变量
例如:
const int a = 20;
则表示 a 是一个常量,你不可以在后续对其进行修改。因为 a 不可修改,所以在创建的时候就要对 a 进行赋值,不对其进行赋值则会报错。例如,下面的代码就会报错
const int a;
const 修饰指针
const 修饰指针可以分为多种情况:
只有一个 const,如果 const 位*左侧,表示指针所指数据是常量,不能通过解引用修改该数据;指针本身是变量,可以指向其他的内存单元
int aaa = 20; int bbb = 30; const int * constPoint = &aaa; constPoint = &bbb; *constPoint = 80; // 这行代码会报错
只有一个 const,如果 const 位于*右侧,表示指针本身是常量,不能指向其他内存地址;指针所指的数据可以通过解引用修改
int aaa = 20; int bbb = 30; int * const constPoint = &aaa; constPoint = &bbb; // 这行代码会报错 *constPoint = 80;
两个 const,*左右各一个,表示指针和指针所指数据都不能修改
int aaa = 20; int bbb = 30; const int * const constPoint = &aaa; constPoint = &bbb; // 这行代码会报错 *constPoint = 80; // 这行代码会报错
const 修饰函数参数
const 修饰函数参数和修饰普通函数是一样的。但是要注意的时候 const 修饰函数参数的时候,其作用域仅仅限制在函数内部。也就是说,你可以把一个不用 const 修饰的参数传入到 const 修饰的参数中去。而只要在函数中保持其不变性就可以了。
const 修饰成员函数
const 修饰的成员函数不能修改任何的成员变量
class A { public: int aaa; int funcA() const { aaa = 20; // 这行代码会报错 return 0; } }
const 成员函数不能调用非 const 成员函数
class A { public: int aaa; int funcA() const { funcB(); // 这行代码会报错 return 0; } int funcB() { return 0; } }
const 修饰函数返回值修饰返回值要分成两种情况
址传递,返回指针,引用。
在 C++ 中有时我们会写这样的代码:
A aaa; A & getA(){ return aaa; } int main(int argc,char **argv) { A bbb; getA() = bbb; return 0; }
上面的代码运行之后,aaa 变量就会被 bbb 所赋值,但是有些时候这样做会造成一些混乱
例如:
getA() == a
有时候会有笔误:
getA() = a
这种情况下,就会有问题,而且不容易被找到这个错误。
所以在大多数情况下,我们可以给返回值加一个 const ,这样可以防止返回值被调用。
A aaa; const A & getA(){ return aaa; } int main(int argc,char **argv) { A bbb; getA() = bbb; // 这行代码会报错 return 0; }
值传递。
值传递就简单多了,因为值传递的时候,返回值会被复制一份,所以加不加 const 都可以。
查看全部 -
C++ 中的空指针
我们之前的课程中曾经讲过空指针的问题,知道在 C++ 中,有使用 NULL 和 nullptr 两种方式表示空指针的方法。
int * p = NULL; int * p = nullptr;
这一小节来看看两者的区别。
NULL
首先看 NULL,在 C++ 中,NULL 其实就是 0。
例如:
int * p = NULL;
等价于:
int * p = 0;
因为在 C++ 中,0 地址通常是被保护起来的,不可访问的。因此用 0 地址来指代这个指针哪里都不指,是可以的。但是这里面却存在一些问题。因为 NULL 就是 0,所以我们可以把 NULL 用在其他地方。
例如:
int a = NULL;
我们可以将一个 int 变量赋值成 NULL,你永远无法阻止有人这么干。而在某些情况下,甚至会在不经意间酿成惨剧。
例如:
class A { public: void func(void * t) { } void func(int i) { } }
这个类中,func 函数有两个重载。这个时候,我们尝试用 NULL 调用一下:
int main(int argc,char **argv) { A a; a.func(NULL); return 0; }
猜猜这个函数到底调用的哪个重载?
nullptr
正是由于 NULL 会导致这样的混乱,所以在 C++11 标准之后,C++ 标准委员会为 C++ 添加了 nullptr 关键字。我们可以将 NULL 赋值给一个普通变量,而 nullptr 却不能。
int a = nullptr;
这样是会直接报错的。
nullptr 只能赋值给指针,所以不会有 NULL 那样的问题。
所以,只要你的编译器兼容 C++11 标准,那么你应该使用 nullptr。
查看全部 -
霸道总裁眼中的命令员工:父类和子类的相互转换
我们在之前的课程中学习过数据类型之间的转换,某些可以隐式转换,某些需要显式转换。
例如,我们可以把 int 转成 long long。
int a = 100; long long b = a;
由于是小类型转大类型,所以这里使用隐式转换就可以了。
再比如,我们可以把 long long 转成 int。
long long a = 100; int b = (int)a;
这里是大类型转小类型,所以要显式转换。这种转换可能会损失精度,是需要我们程序员掌控的。
类的转换
同样,类之间也可以相互转换。类的转换主要是在父类和子类之间的转换。
首先,我们先来看看父类和子类之间的逻辑关系
class Staff { public: std::string name; int age; } class Coder : public Staff { public: std::string language; };
这里有两个类,一个类是 Staff 员工类,里面包括两个属性,name 和 age。Coder 程序员类继承自员工类,所以其包含了 Staff 的属性,除此之外,还有一个 language 属性,表示其使用的编程语言。
我们其实可以把一个员工强行转化成程序员,但是这就有可能出问题,就如同我们把 long long 转成 int 就有可能出现问题。
int main(int argc,char **argv) { Coder * coder = new Coder(); Staff * staff = coder; // 隐式转换就可以 Coder * coder = (Coder *)staff; // 必须显式转换 return 0; }
查看全部 -
动态编联和静态编联
上一小节,我们介绍了父类和子类的转换,也简单介绍了多态,从这节开始,我们详细介绍多态。
class Base { public: void func(){ printf("this is Base\n"); } } class Child : public Base { public: void func(){ printf("this is Child\n"); } } int main(int argc,char **argv) { Child * obj = new Child(); Base * baseobj = (Base *)obj; baseobj->func(); delete obj; return 0; }
我们之前讲述了什么是多态,还用了一个例子,将一个指针的类型做成强转,然后调用 func 函数,就会发现, func 函数会随着被强转的类型的变换而变换,这种函数的关联过程称为编联。按照联编所进行的阶段不同,可分为两种不同的联编方法:静态联编和动态联编。
静态编联
Child * obj = new Child(); Base * baseobj = (Base *)obj; baseobj->func(); delete obj; return 0;
再来看看这个例子,我们通过强制转换来指定 func 执行的是哪个。这个过程是在编译阶段就将函数实现和函数调用关联起来,因此静态联编也叫早绑定,在编译阶段就必须了解所有的函数或模块执行所需要检测的信息。
动态编联
除了静态编联之外,C++ 还支持动态编联。动态联编是指联编在程序运行时动态地进行,根据当时的情况来确定调用哪个同名函数,实际上是在运行时虚函数的实现。当然,我们现在所学的知识还没办法完成动态编联,接下来,我们将要学习虚函数,来实现动态编联。
查看全部 -

引用和指针用法的区别。
查看全部 -
引用和指针功能一样,引用必须要初始化,赋值nullptr。
int &ra = a;
引用只能指向一个地址,而指针可以变化自己的指向地址。
查看全部 -
纯虚函数只可以被继承。
将父类的析构函数声明为虚函数,作用是用父类的指针删除一个派生类对象时,派生类对象的析构函数会被调用。例如:
class Staff
{
public:
std::string name;
int age;
virtual ~Staff()
{
}
}
class Coder : public Staff
{
public:
std::string language;
virtual ~Coder()
{
}
};
int main(int argc,char **argv)
{
Staff * s = new Coder();
delete s;
return 0;
}此时如果析构函数不加 virtual,那么 delete 父类指针的时候,子类的析构就不会被调用,某些情况下会导致内存泄漏。
查看全部 -
纯虚函数只可以被继承。
将父类的析构函数声明为虚函数,作用是用父类的指针删除一个派生类对象时,派生类对象的析构函数会被调用。例如:
class Staff
{
public:
std::string name;
int age;
virtual ~Staff()
{
}
}
class Coder : public Staff
{
public:
std::string language;
virtual ~Coder()
{
}
};
int main(int argc,char **argv)
{
Staff * s = new Coder();
delete s;
return 0;
}此时如果析构函数不加 virtual,那么 delete 父类指针的时候,子类的析构就不会被调用,某些情况下会导致内存泄漏。
查看全部 -
给员工分部门:类的继承
类,就像是对某一类事物的抽象模版,我们可以根据这个模版生产出具有相同属性的对象。例如,我们之前将员工抽象成了 Staff 类。
而在某些场景下,我们希望对抽象的内容进行扩增,或者说更加具体化。例如,我们之前定义了员工,但是员工只是很抽象的一个概念,员工和员工是不一样的,例如,程序员和会计都是员工,他们都具有员工应有的属性,但是除此之外,他们还有额外属于自己的东西。
为了完成这种关系,我们来学习一下继承。
例如,我们可以来写一个程序员类,名字叫做 Coder
class Coder { };
这个 Coder 是员工的一种,他具有员工的所有属性,所以,我们可以让 Coder 继承自 Staff
class Coder : public Staff { };
当然,除了具有 Staff 的所有内容之外,Coder 还有属于自己的动作,那就是写代码,我们就可以这样写:
class Coder : public Staff { public: void code() { printf("Coding!!!\n"); } };
这样,Coder 这个类,除了具有 Staff 的所有成员变量和成员函数之外,还有了一个属于自己的函数。
查看全部 -
类
类,是 C++ 实现面向对象最基础的部分。类其实和之前学过的结构体十分相似,你可以认为类是结构体的升级版。
类的申明
在 C++ 中,可以用下面的代码申明一个员工类:
class Staff { };
可以像使用结构体一样使用这个类:
#include <stdio.h> class Staff { }; int main(int argc,char **argv) { Staff st; return 0; }
分文件编程
我们在此之前都是把代码放到一个文件里,但是这样在实际工程中肯定是不行的,我们不可能把所有的代码都写到一个文件夹里面。而在 C++ 中我们就常常把类定义到不同的文件里面,把每个类都独立起来,这样代码的耦合性就会降低,方便维护。
在 C++ 中,我们可以把一个类写到两个文件里面,一个是后缀为 .h 或者 .hpp 的头文件,一个是后缀为 .cpp 的实现文件。我们先在开发环境里新建一个类。输入类名是 Staff。
可以看到 VS 为我们创建类两个文件,Staff.h 和 Staff.cpp。Staff.h 文件为定义,Staff.cpp 为实现。
在分了文件之后,我们想要在 main 函数中引用这个类,就需要使用 #include “Staff.h” 将头文件引入进来。
实例化
在新建了一个类之后,我们就可以根据这个类产生对象了。根据类产生对象的过程叫做实例化。
#include "Staff.h"
int main(int argc,char **argv)
{ // 我们就这样实例化了三个员工
Staff st1;
Staff st2;
Staff st3;
return 0;
}
这样分配,我们将这三个“员工”分配到了栈上,同样的,可以把他们分配到堆内存上面去。
new delete
要将对象分配到堆上,需要用到另外两个关键字,new 和 delete。new 用来分配对象,delete 用来删除对象。new 会返回一个指针,在使用完毕后,要通过 delete 把这个指针指向的地址释放掉。
#include "Staff.h"
int main(int argc,char **argv) {
Staff * st1 = new Staff();
Staff * st2 = new Staff();
Staff * st3 = new Staff();
// 记得释放
delete st1;
delete st2;
delete st3;
return 0;
}
查看全部 -
霸道总裁的员工:类
我们上一小节中介绍了面向对象的思想,这一小节开始,我们来具体看看在 C++ 中应该如何实现面向对象。
类
类,是 C++ 实现面向对象最基础的部分。类其实和之前学过的结构体十分相似,你可以认为类是结构体的升级版。
类的申明
在 C++ 中,可以用下面的代码申明一个员工类:
class Staff { };
可以像使用结构体一样使用这个类:
#include <stdio.h> class Staff { }; int main(int argc,char **argv) { Staff st; return 0; }
分文件编程
我们在此之前都是把代码放到一个文件里,但是这样在实际工程中肯定是不行的,我们不可能把所有的代码都写到一个文件夹里面。而在 C++ 中我们就常常把类定义到不同的文件里面,把每个类都独立起来,这样代码的耦合性就会降低,方便维护。
在 C++ 中,我们可以把一个类写到两个文件里面,一个是后缀为 .h 或者 .hpp 的头文件,一个是后缀为 .cpp 的实现文件。我们先在开发环境里新建一个类。输入类名是 Staff。
可以看到 VS 为我们创建类两个文件,Staff.h 和 Staff.cpp。Staff.h 文件为定义,Staff.cpp 为实现。
在分了文件之后,我们想要在 main 函数中引用这个类,就需要使用 #include “Staff.h” 将头文件引入进来。
实例化
在新建了一个类之后,我们就可以根据这个类产生对象了。根据类产生对象的过程叫做实例化。
#include "Staff.h"
int main(int argc,char **argv)
{ // 我们就这样实例化了三个员工
Staff st1;
Staff st2;
Staff st3;
return 0;
}
这样分配,我们将这三个“员工”分配到了栈上,同样的,可以把他们分配到堆内存上面去。
new delete
要将对象分配到堆上,需要用到另外两个关键字,new 和 delete。new 用来分配对象,delete 用来删除对象。new 会返回一个指针,在使用完毕后,要通过 delete 把这个指针指向的地址释放掉。
#include "Staff.h"
int main(int argc,char **argv) {
Staff * st1 = new Staff();
Staff * st2 = new Staff();
Staff * st3 = new Staff();
// 记得释放
delete st1;
delete st2;
delete st3;
return 0;
}
查看全部




举报