

-
Keys通用操作
获取所有的key keys *
获取key已n开头的 keys n?
删除key del name1 name2 name3
查看key是否存在 exists name1
重命名 rename name1 newname
设置过期时间 expire name1 1000(单位秒)
查看剩余过期时间 ttl name1
获取jey类型 type name1
查看全部 -
Sorted-set
添加 zadd 例 zadd key v1 name1 v2 name2 v3 name3
取 zscore 例 zscore key name1
获取成员数量 zcard 例 zcard key
删 zrem 例 zrem key name1 name2
范围查寻(从小到大) zrange 例 zrange key 0 -1 withscores 注:withscores如果没有添加不会显示值
范围查寻(从大到小) zrevrange 例 zrevrange key 0 -1 withscores 注:withscores如果没有添加不会显示值
按照范围删除 例 zremrangebyrank key 0 4
按照value删除 例 zremrangebyscore 80 90
查看全部 -
添加 sadd 例 sadd key v1 v2 v3
删除指定元素 srem 例 srem key v1 v2
查看所有元素 smembers 例 smemberes key
判断元素是否存在 sismember 例 sismember key v1
2个key的差集 sdiff 例 sdiff key1 key2
2个key的交集 sinter 例 sinter key1 key2
2个key的并集 sunion 例 sunion key1 key2
获取元素数量 scard 例 scard key
随机返回成员 srandmember 例 srandmember key
将key1 和 key2 相差的存到key3中 例 sdiffstore key3 key1 key2
将key1 和 key2 的交集存到key3中 例 sinterstore key3 key1 key2
将key1 和 key2 的并集存到key3中 例 sunionstore key3 key1 key2
查看全部 -
redis的数据结构
五种数据类型
1. 字符串(String)
二进制,存入和获取的数据相同
2. 哈希(hash)
3. 字符串列表(list)
4. 字符串集合(set)
5. 有序字符串集合(sorted set)
key的定义
1 不要过长
2. 不要过短
3. 统一的命名规范
赋值 set key string
获取 get key
获取再赋值 getset key string2
删除 del key
数值增减
incr key //针对数值加1,不存在时先初始为0再加1
decr key //数值减1
数值扩展
incrby key int //数值+int
decrby key int //数值-int
追加字符串 append key string
查看全部 -
redis数据类型及其常用场景:
string: 存储字符串
hash: 实际上是一个map,可以存储键值对
list: 链表,包括双向链表,插入删除数据非常快。可以用于消息中间件的补救措施,比如消息队列中的消息发送成功存入一个链表,发送失败存入一个链表,一段时间后将发送成功的链表清空,发送失败的链表中的消息继续发送,直到成功后存入成功的链表,目的是为了保证数据的一致性。
set: 无重复数据的无序集合,可用于统计用户数据,比如购物网站用一个set记录一类商品的购买用户,用另一个set记录另一个商品的购买用户,可以做交集,差集等,分析用户喜好。
sorted-set: 无重复数据的有序集合,可存入数据和与之对应的分值,根据分值排序,可用于排名统计等
查看全部 -
为什么需要NoSQL
高并发读写
海量数据的高效率存储和访问
高可扩展性和高可用性
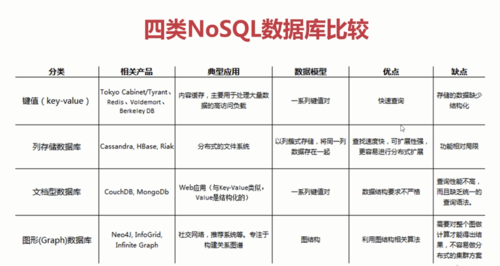
NoSQL数据库的四大分类:
键值存储
列存储
文档数据库
图形数据库
 NoSQL特点:
NoSQL特点:易扩展
大数据量,高性能
灵活的数据模型
高可用
查看全部 -
为什么需要NoSQL?
高并发读写
海量数据的高效率存储和访问
高可扩展性和高可用性。
NoSQL数据库的四大分类:
键值存储
列存储
文档数据库
图形数据库
NoSQL的特点:
易扩展
大数据量,高性能
灵活的数据模型
高可用
查看全部 -
AOF 优势: 1.同步: a.每秒同步:异步完成,效率高,一旦系统宕机,修改的数据丢失 b.每修改同步:同步持久化,每分钟发生的变化记录到磁盘中,效率低,安全 c.不同步 2.日志写入操作追加模式append a.系统宕机,不影响存在的内容 b.写入一半数据,若系统崩溃,下次启动redis,redis-check-aof工具解决数据一致性 3.如果日志过大,自动重写机制,修改的数据写入到到磁盘文件,创建新文件,记录产生的修改命令,重写切换时,保证数据安全 4.格式清晰的日志文件,完成数据的重建 劣势: 1.对于相同数据文件,相比RDB,AOF文件较大 2.效率低 配置: vim redis.conf 默认: appendonly no #AOF方式默认关闭 appendfilename appendonly.aof #配置文件 #appendfsync always #每修改一次,同步到磁盘上 appendsync everysec 每秒同步到磁盘一次 #appensync no 不同步 实践打开AOF: appendonly yes appendfsync always 终端2:先断开redis ./bin/redis-cli shutdown 启动redis: ./bin/redis-server ./redis.conf 终端1:set name 100 终端2:产生appendonly.aof文件 终端1:flushall 清空数据库 终端2: ./bin/redis-cli shutdown vim appendonly.aof 删除flushall ./bin/redis-server ./redis.conf ./bin/redis-cli keys * 数据还原
查看全部 -
AOF持久化
优势:数据安全, 每秒同步,每修改同步,不同步
劣势:如果宕机 这1s的数据就没了。
每修改同步,安全,但是效率慢。
对于日志的写入方式采用append模式,在写的过程中发生宕机,写了一半,宕机,下次启动前工具会解决数据一致性问题。如果日志过大,redis会启动重写日志。
默认采用rdb方式
查看全部 -
Sorted-set:存储的元素有一个分数,不同的元素分数可能相同
添加元素
zadd sortname score1 value1 score2 value2...:向sortname中添加元素value及元素的分数score,如果value存在,但是value对应的score不一样则进行替换
获得元素
zscore sortname value:返回sortname中value对应的score
zcard sortname:返回sortname中的value个数
删除元素
zrem sortname value1 value2:删除sortname中对应value的元素及分数
zremrangebyrank sortname start end:删除下标在start至end范围内的元素value及value对应的score
zremrangebyscore sortname start end:删除score在start至end范围内的元素value及value对应的score
范围查询
zrange sortname start end:返回sortname中下标在start至end范围内的value,返回value的顺序以value的score进行升序排序
zrange sortname start end withscore:返回sortname中下标在start至end范围内的value及value对应的分数,以value对应的score进行升序排序
zrevrange sortname start end withscores:返回sortname中下标在start至end范围内的value及value对应的score,以value的score进行降序排序
扩展命令
zrangebyscore setname start end withscores:返回成绩在start至end之间的value及value对应的成绩
zrangebyscore setname start end withscores limit num1 num2:返回setname中score在start至end之间的num2-num1个的value及value的score
zincyby setname value setkey:对setname的setkey的score加上value
zcount setname start end:返回setname中score在start至end之间的个数
查看全部 -
存储Set:
和List类型不同的是:Set集合中不允许出现重复的元素,List中元素可以重复
Set中可包含的最大元素数量与List一样
存储set常用命令:
添加/删除元素
sadd setname value1 value2 value3...:向setname中添加元素
srem setname value1 value2:删除setname中的value1、value2
获取集合中的元素
smembers setname:返回setname中的所有value
sismenber setname value:判断setname中是否包含value,存在返回1不存在返回0
集合中的差集运算
sdiff setname1 setname2:返回setname1与setname2的差集,返回结果与setname的书写顺序有关
集合中的交集运算
sinter setname1 setname2:获取setname1与setname2中的交集
集合中的并集运算
sunion setname1 setname2:获取setname1与setname2的并集,重复的元素保留一个
扩展命令
scard setname:返回setname中的值的个数
srandmember setname:随机返回setname中一个元素
sdiffstore setname setname1 setname2:将setname1与setname2的差集元素存储到setname中
sinterstore setname setname1 setname2:将setname1与setname2的交集存储到setname中
sunionstore setname setname1 setname2:将setname1与setname2的并集去重存储到setname中
查看全部 -
存储list:
ArrayList使用数组方式
LinkedList使用双向链接方式
双向链表中增加数据
双向链表中删除数据
存储list常用命令:
两端添加
lpush listname value1 value2 value3:如果listname不存在则创建listname并从左侧添加,先添加的元素靠后,下标从0开始。如果listname存在则直接从左侧添加
rpush listname value1 value2 value3:从右侧添加,先添加的元素靠前,下标从0开始
查看列表
lrange listname start end:左边查看指定范围内的listname的元素,下标从0开始,如果end为-1代表是最后一个元素
两端弹出
lpop listname:左边弹出listname中的第一个元素。如果listname不存在元素则返回nil,一旦做了弹出操作,被弹出的元素将在listname中消失
rpop listname:尾部(右部)弹出,与lpop同理
获取列表元素个数
llen listname:获取listname中元素的个数,如果listname不存在则返回0
扩展命令
lpushx listname value1 value2...:如果listname存在则进行添加操作,如果listname不存在则添加失败返回0
rpushx listname value1 value2...:与lpushx同理
lrem listname count value:如果count大于0,则从左往右删除count个value;如果count小于0,则从右向左删除count个value;如果count等于0则表示删除所有的value
lset listname index value:将listname中下标为index的值修改为value
linsert listname before listvalue value:在listname中的listvalue前插入一个value
linsert listname after listvalue value:在listname中的listvalue之后插入一个value
rpoplpush listname1 listname2:将listname1中右边的第一个元素进行弹出然后向listname2的左侧进行添加弹出的元素
查看全部 -
list左侧添加 lpush mylist a b c
list右侧添加 rpush mylist a b c
查询元素 lrange 0 5 角标0到5 lrange 0 -1 0到倒数第一位
左侧弹出 lpop mylist 右侧弹出 rpop mylist
查询长度 llen mylist
没有则不添加 lpushx/rpushx mylist x
删除list元素 lrem mylist m x 从左删除m个x元素
从右删除m个x元素 lrem mylist -m x 删除所有x元素 lrem mylist 0 x
设置(修改)角标元素 lset mylist [index] [value]
之前/之后插入 linsert mylist before/after [value] [insertvalue]
将list1 最右边的值pop到list2 最左边 rpoplpush mylist1 mylist2
查看全部 -
RDB 优势: 1.数据库只包含一个文件,通过文件备份策略,定期配置,恢复系统灾难 2.压缩文件转移到其他介质上 3.性能最大化,redis开始持久化时,分叉出进程,由子进程完成持久化的工作 ,避免服务器进程执行I/O操作,启动效率高 劣势: 1.无法高可用:系统一定在定时持久化之前宕机,数据还没写入,数据已经丢失 2.通过fock分叉子进程完成工作,数据集大的时候,服务器需要停止几百毫秒甚至1秒 配置: cd /usr/local/redis vim redis.conf 默认: save 900 1 #每900秒至少1个key变化,持久化一次,到内存一个快照 save 300 10 #每300秒至少10个key变化,往硬盘写一次 save 60 10000 #每60秒至少10000个key变化,写一次 dbfilename dump.rdb #数据的文件名 dir ./ #保存的路径,redis路径下查看全部
-
最重要的是使用程序去控制redis查看全部











举报