
































































 朱广蔚 ·
朱广蔚 ·threading 模块的 Thread 类的使用
1. 多线程的基本概念
程序要完成两个任务:
- 任务 1 进行一项复杂的计算,需要 1 秒才能完成。
- 任务 2 读取磁盘,需要 1 秒才能完成。
我们可以串行的执行这两项任务,先执行任务 1,再执行任务 2,完成这两项任务总共需要 2 秒,如下图所示:
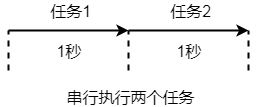
我们可以并行的执行这两项任务,同时执行这两项任务,完成这两项任务只需要 1 秒,如下图所示:
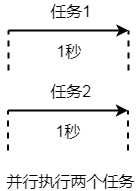
显然,并行执行的时间小于串行执行的时间。很多场景下,我们希望程序能够同时执行多个任务,操作系统提供了多线程的机制用于实现并行执行多个任务。在操作系统中,线程是一个可以独立执行的任务。程序执行时至少包含一个线程,可以使用线程相关的 API 创建新的线程。
Python 的 threading 模块提供了类 Thread,用户通过新建一个类 Thread 创建新的线程,本文描述了类 Thread 的基本使用。
2. 多线程的基本使用
Python 的 threading 模块中提供了类 Thread 用于实现多线程,用户有两种使用多线程的方式:
- 在线程构造函数中指定线程的入口函数。
- 自定义一个类,该类继承类 Thread,在自定义的类中实现 run 方法。
2.1 线程的构造函数和重要的成员方法
本节介绍 Thread 相关的三个函数的功能:
- 类 Thread 的构造函数
- 类 Thread 的 start 方法
- 类 Thread 的 join 方法
2.1.1 类Thread的构造函数
Thread(group = None, target = None, name = None, args = (), kwargs = {})
参数的含义如下:
- group: 线程组,目前还没有实现,在此处必须是 None。
- target: 线程的入口函数,线程从该函数开始执行。
- name: 线程名。
- args: 线程的入口函数的参数,以元组的形式传入。
- kwargs: 线程的入口函数的参数,以字典的形式传入。
使用 Thread 构造一个新线程时,必须指定 target 和 args 两个参数,target 为线程的入口,args 为线程入口函数的参数。
2.1.2 类 Thread 的 start 方法
start()
在线程对象的构造函数中 target 指定了线程入口函数,args 指定了线程入口函数的参数。线程对象的 start 方法使新线程开始执行,执行函数 target(args)。
2.1.3 类 Thread 的 join 方法
join()
调用线程对象的 start 方法后,新线程开始执行函数 target(args)。调用线程对象的 join 方法,主线程阻塞,等待新线程执行完毕。
2.2 指定线程的入口函数
下面通过一个具体的例子,说明通过指定线程的入口函数的方式使用多线程。
import time
import threading
def thread_entry(begin, end):
for i in range(begin, end):
time.sleep(1)
print(i)
t0 = threading.Thread(target = thread_entry, args = (1, 4))
t1 = threading.Thread(target = thread_entry, args = (101, 104))
t0.start()
t1.start()
t0.join()
t1.join()
-
在第 9 行和第 10 行,通过调用 Thread 的构造函数创建了两个线程。
-
在第 9 行,设定线程的入口函数为 thread_entry,传递给入口函数两个参数:1 和 4,新的线程将执行 thread_entry(1, 4),变量 t0 指向新创建的线程对象。
-
在第 10 行,设定线程的入口函数为 thread_entry,传递给入口函数两个参数:101 和 104,新的线程将执行 thread_entry(101, 104),变量 t1 指向新创建的线程对象。
-
在第 4 行到第 7 行,定义了线程入口函数,该函数的功能是打印在 [begin, end) 区间的整数,每打印一个整数,调用 time.sleep(1) 睡眠 1 秒钟。
-
在第 11 行,调用 start 方法启动线程 t0,t0 开始执行 thread_entry(1, 4)。
-
在第 12 行,调用 start 方法启动线程 t1,t1 开始执行 thread_entry(101, 104)。
-
在第 13 行和第 14 行,调用 join 方法,等待线程 t0 和 t1 执行完毕。
程序的运行结果如下:
1
101
2
102
3
103
线程 t0 的输出结果为 1、2、3,线程 t1 的输出结果为 101、102、103。由于两者是并发执行的,所以结果交织在一起。
2.3 继承 Thread
下面通过一个具体的例子,说明通过继承 Thread 的方式使用多线程。
import time
import threading
class MyThread(threading.Thread):
def __init__(self, begin, end):
threading.Thread.__init__(self)
self.begin = begin
self.end = end
def run(self):
for i in range(self.begin, self.end):
time.sleep(1)
print(i)
t0 = MyThread(1, 4)
t1 = MyThread(101, 104)
t0.start()
t1.start()
t0.join()
t1.join()
-
在第 4 行,定义类 MyThread,继承 threading.Thread。
-
在第 5 行,定义了构造函数 __init__,首先调用父类 thread.Thread.__init__ 初始化 Thread 对象,然后将参数 begin 和 end 保存在 MyThread 的成员变量中。
-
在第 10 行,定义了方法 run,当线程开始运行时,run 方法会被调用。在 run 方法中,打印在 [begin, end) 区间的整数,每打印一个整数,调用 time.sleep(1) 睡眠 1 秒钟。
-
在第 15 行和第 16 行,通过调用 MyThread 的构造函数创建了两个线程。
-
在第 17 行,调用 start 方法启动线程 t0,t0 开始执行 MyThread 的方法 run()。
-
在第 18 行,调用 start 方法启动线程 t1,t1 开始执行 MyThread 的方法 run()。
-
在第 19 行和第 20 行,调用 join 方法,等待线程 t0 和 t1 执行完毕。
程序的运行结果如下:
1
101
2
102
3
103
线程 t0 执行 thread_entry(1, 4),输出结果为 1、2、3,线程 t1 执行 thread_entry(101, 104),输出结果为 101、102、103。由于两者是并发执行的,所以结果交织在一起。
2.4 常见的错误
2.4.1 自定义的类的 __init__ 方法忘记调用父类 Thread 的 __init__ 方法
通过自定义类继承 Thread 的方式实现线程时,要求自定义的类的 __init__ 方法调用父类 Thread 的 __init__ 方法,如果忘记调用 Thread 的 __init__ 方法,则会报错。编写 forget_init.py,其内容如下:
import time
import threading;
class MyThread(threading.Thread):
def __init__(self, id):
# 在此处没有调用父类 threading.Thread.__init__ 方法
self.id = id
def run(self):
for i in range(3):
print('This is thread %s' % self.id)
time.sleep(3)
t1 = MyThread(0)
t1 = MyThread(1)
t0.start()
t1.start()
t0.join()
t1.join()
运行 forget_init.py,程序输出如下:
Traceback (most recent call last):
File "forget_init.py", line 14, in <module>
t0 = MyThread(0)
File "forget_init.py", line 7, in __init__
self.id = id
File "/usr/lib/python3.6/threading.py", line 1089, in name
assert self._initialized, "Thread.__init__() not called"
AssertionError: Thread.__init__() not called
以上错误信息显示,Thread.__init__ 没有被调用。
2.4.2 只有一个线程参数时,使用 (arg) 表示线程参数
元组只包含一个元素时,必须加一个逗号,在下面的定义中,变量 tuple 表示的是一个元组,该元组包含了一个元素 123。
>>> tuple = (123,)
>>> tuple
(123,)
在下面的定义中,忘记加逗号,则变量 expression 表示的是一个整数类型的表达式,变量 expression 是一个整数 123,而不是元组 (123,)。
>>> expression = (123)
>>> expression
123
通过指定线程入口函数的方式实现线程时,使用元组传递线程参数,如果只有一个线程参数 arg,使用 (arg) 表示线程参数时,则会报错。编写程序 not_tuple.py,内容如下:
import time
import threading;
def run(id):
for i in range(3):
print('This is thread %d' % id)
time.sleep(3)
t0 = threading.Thread(target = run, args = (0)) # 此处错误,应为(0,)
t1 = threading.Thread(target = run, args = (1)) # 此处错误,应为(1,)
t0.start()
t1.start()
t0.join()
t1.join()
运行 not_tuple.py,程序输出如下:
Exception in thread Thread-1:
Traceback (most recent call last):
File "/usr/lib/python3.6/threading.py", line 916, in _bootstrap_inner
self.run()
File "/usr/lib/python3.6/threading.py", line 864, in run
self._target(*self._args, **self._kwargs)
TypeError: run() argument after * must be an iterable, not int
以上显示错误信息 “TypeError: run() argument after * must be an iterable, not int”,初学者很难看明白这段错误信息,这段错误信息表示 run() 的 arguments 必须是可以遍历的(iterable)。线程入口参数是一个元组,而参数 (0) 表示的是一个整数而不是元组 (0,)。
3. 使用多线程进行并行 IO 操作
本节通过实例说明 Python 多线程的使用场景。现在需要编写程序获取 baidu.com、taobao.com、qq.com 首页,程序包括 3 个任务:
- 获取 baidu.com 的首页
- 获取 taobao.com 的首页
- 获取 qq.com 的首页
本节需要使用到 python 的 requests 模块,requests 模块的用于 http 请求,requests 模块提供了 get 方法用于获取网页。
在 3.1 小节演示串行执行这 3 个任务,并记录串行完成 3 个任务总共所需要的时间;在 3.2 小节演示并行执行这 3 个任务,并记录并行完成 3 个任务总共所需要的时间。
3.1 串行获取 baidu.com、taobao.com、qq.com 首页
编写程序 serial.py,该程序以串行的方式获取 baidu、taobao、qq 的首页,内容如下:
from datetime import datetime
import requests
import threading
def fetch(url):
response = requests.get(url)
print('Get %s: %s' % (url, response))
time0 = datetime.now()
fetch("https://www.baidu.com/")
fetch("https://www.taobao.com/")
fetch("https://www.qq.com/")
time1 = datetime.now()
time = time1 - time0
print(time.microseconds)
-
在第 5 行,定义了函数 fetch,函数 fetch 获取指定 url 的网页。
-
在第 6 行,调用 requests 模块的 get 方法获取获取指定 url 的网页。
-
在第 9 行,记录执行的开始时间。
-
在第 11 行到第 13 行,串行执行获取 baidu、taobao、qq 的首页。
-
在第 15 行到第 17 行,记录执行的结束时间,并计算总共花费的时间,time.micoseconds 表示完成需要的时间(微秒)。
执行 serial.py,输出如下:
Get https://www.baidu.com/: <Response [200]>
Get https://www.taobao.com/: <Response [200]>
Get https://www.qq.com/: <Response [200]>
683173
在输出中,<Response [200]> 是服务器返回的状态码,表示获取成功。成功获取了 baidu、taobao、qq 的首页,总共用时为 683173 微秒。
3.2 并行获取 baidu.com、taobao.com、qq.com 首页
编写程序 parallel.py,该程序以并行的方式获取 baidu、taobao、qq 的首页,内容如下:
from datetime import datetime
import requests
import threading
def fetch(url):
response = requests.get(url)
print('Get %s: %s' % (url, response))
time0 = datetime.now()
t0 = threading.Thread(target = fetch, args = ("https://www.baidu.com/",))
t1 = threading.Thread(target = fetch, args = ("https://www.taobao.com/",))
t2 = threading.Thread(target = fetch, args = ("https://www.qq.com/",))
t0.start()
t1.start()
t2.start()
t0.join()
t1.join()
t2.join()
time1 = datetime.now()
time = time1 - time0
print(time.microseconds)
-
在第 5 行,定义了函数 fetch,函数 fetch 获取指定 url 的网页。
-
在第 6 行,调用 requests 模块的 get 方法获取获取指定 url 的网页。
-
在第 9 行,记录执行的开始时间。
-
在第 11 行到第 13 行,创建了 3 个线程,分别执行获取 baidu、taobao、qq 的首页。
-
在第 14 行到第 16 行,启动这 3 个线程,这 3 个线程并行执行。
-
在第 17 行到第 19 行,等待这 3 个线程执行完毕。
-
在第 21 行到第 23 行,记录执行的结束时间,并计算总共花费的时间,time.micoseconds 表示完成需要的时间(微秒)。
执行 parallel.py,输出如下:
Get https://www.baidu.com/: <Response [200]>
Get https://www.qq.com/: <Response [200]>
Get https://www.taobao.com/: <Response [200]>
383800
在输出中,<Response [200]> 是服务器返回的状态码,表示获取成功。成功获取了 baidu、taobao、qq的首页,总共用时为 383800 微秒。相比执行,串行执行总共用时为 683173 微秒,因此使用多线程加快了程序的执行速度。
4. 获取线程的返回值
在继承 Thread 实现多线程的方式中,将线程的返回值保存在线程对象中,使用一个成员变量保存线程的返回值。下面通过一个具体的例子,说明如何获取线程的返回值。使用多线程技术计算 1+2+3 … + 100 的累加和,算法思路如下:
-
主程序创建 2 个线程:
-
线程 1,计算前 50 项的累加和,即 1+2+3 … + 50,保存计算结果。
-
线程 2,计算后 50 项的累加和,即 51+52+53 … + 100,保存计算结果。
-
主程序等待线程 1 和线程 2 执行完毕,获取它们各自的计算结果,并相加得到最终的计算结果。
编写程序 get_return_value.py,其内容如下:
import threading
class MyThread(threading.Thread):
def __init__(self, begin, end):
threading.Thread.__init__(self)
self.begin = begin
self.end = end
def run(self):
self.result = 0
for i in range(self.begin, self.end):
self.result += i
t0 = MyThread(1,51)
t1 = MyThread(51,101)
t0.start()
t1.start()
t0.join()
t1.join()
print(t0.result)
print(t1.result)
print(t0.result + t1.result)
-
在第 14 行,创建第一个线程,计算区间 [1, 51) 内的累加和。
-
在第 15 行,创建第二个线程,计算区间 [51, 101) 内的累加和。
-
在第 4 行,函数 __init__ 将线程参数 begin 和 end 保存到线程对象中。
-
在第 9 行,线程启动后执行函数 run。
-
在第 10 行到第 12 行,使用 self.result 保存线程的计算结果。
-
在第 16 行到第 19 行,启动线程进行计算,主程序等待子线程计算结束。
-
在第 20 行到第 22 行,从 t0.result 中获取线程 t0 的计算结果,从 t1.result 中获取线程 t1 的计算结果,将两者相加,打印最终的结果。
运行程序 get_return_value.py,输出如下:
1275
3775
5050
线程 t0 计算前 50 项,计算结果为 1275;线程 t1 计算后 50 项,计算结果为 3775;主程序将两者相加,得到最终的计算结果为 5050。

 2026 imooc.com All Rights Reserved |
2026 imooc.com All Rights Reserved |