

-
request.meta['proxy'] = 'http-cla.abuyun.com:9030'
如果按照视频中的写,其他都一样,运行main.py,那么会提示如下错误。
File "/home/ubuntu16/.local/lib/python3.5/site-packages/twisted/web/client.py", line 1513, in endpointForURI
raise SchemeNotSupported("Unsupported scheme: %r" % (uri.scheme,))
twisted.web.error.SchemeNotSupported: Unsupported scheme: b''
解决方法:request.meta['proxy'] = 'http://http-cla.abuyun.com:9030'
即加上http://就可以了
查看全部 -
在content=i_item.xpath(".//div[@class='info']//div[@class='bd']/p[1]/text").extract()
for i_content in content:
content_s = "".join(i_content.split()),,,后面省略
在视频中没有.extract(),本机ubuntu16+python3环境,运行提示没有split属性。必须加上extract()才可以
查看全部 -
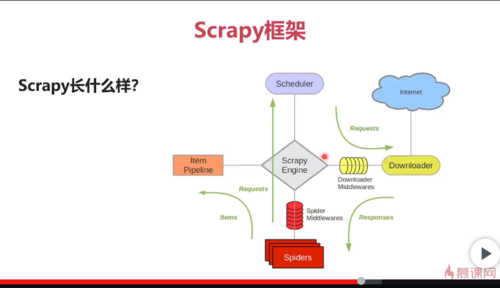
Scrapy框架构成
查看全部 -
77查看全部
-
数据保存为CSV文件:
scrapy crawl douban_spider -o test.csv
查看全部 -
scrapy是python的爬虫框架。
查看全部 -
Scrapy抓取4步走:新建项目、 明确目标、 制作爬虫、 存储内容
(1)新建项目:
命令行输入:
scrapy startproject douban
将工程导入pycharm:
打开PyCharm,然后选择open文件,找到刚刚创建的项目,直接打开,然后进行PyCharm的Preferences中,选择Project Interpreter,这时候会看到显示[invalid] Python 3.6(scrapy)...,选择右边设置按钮,选择show all,然后左下角➕按钮,在页面中,直接点OK即可。
创建douban_spider文件:
进入douban\spiders目录,输入scrapy genspider douban_spider movie.douban.com
查看全部





举报