

-
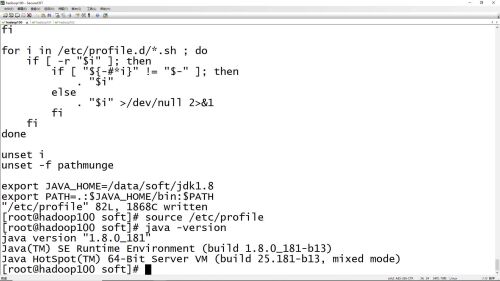
# source /etc/profile 修改环境变量配置文件
 查看全部
查看全部 -
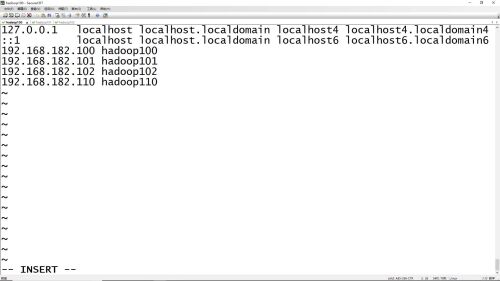
vim /etc/hosts
 查看全部
查看全部 -
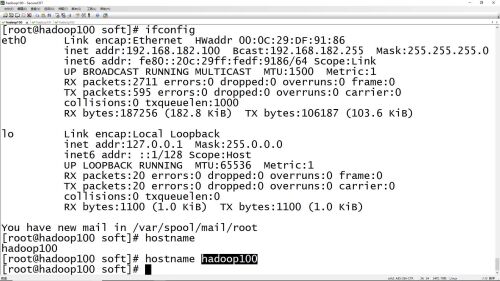
#hostname hadoop100 修改主机名命令(临时有效)
 查看全部
查看全部 -
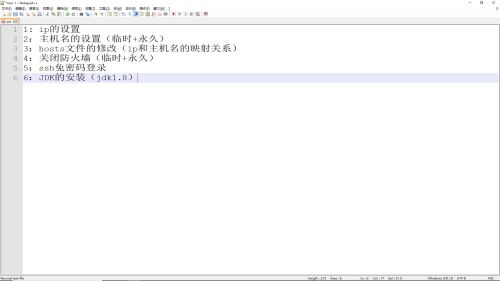
安装hadoop所需步骤
 查看全部
查看全部 -
hadoop集群安装
查看全部 -
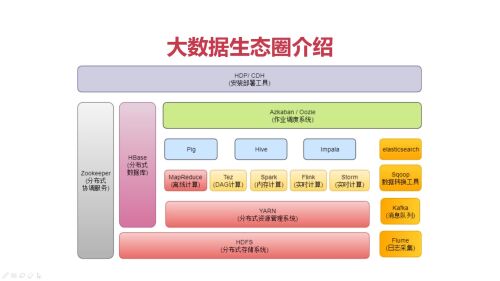
大数据生态圈介绍
 查看全部
查看全部 -
Yarn架构分析
 查看全部
查看全部 -
MapREduce架构分析
 查看全部
查看全部 -
HDFS(分布式存储)架构分析
 查看全部
查看全部 -
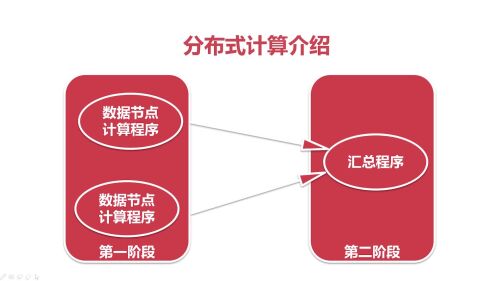
分布式计算介绍
 查看全部
查看全部 -
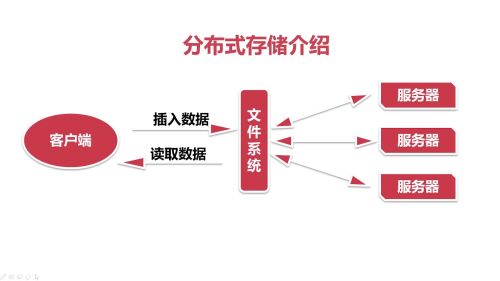
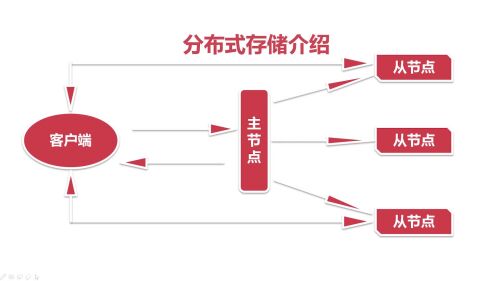
分布式存储介绍
 查看全部
查看全部 -
1、HDFS
负责海量数据的分布式存储。
支持主从结构:主节点支持多个NameNode,从节点支持多个DataNode。
NameNode负责接收用户请求,维护目录系统的目录结构;DataNode主要负责存储数据。
2、YARN
负责管理集群资源的管理和调度,包括CPU和内存,支持主从结构;主节点最多可以有2个,从节点可以有多个。
主节点(ResourceManager)进程主要负责集群资源的分配和管理。
从节点(NodeManager)主要负责单节点资源管理。
3、MapReduce
计算框架之一。
编程模型,主要负责海量数据计算,主要由两个阶段组成:Map和Reduce。
Map阶段是一个独立的程序,会在很多个节点上同时执行,每个节点处理一部分数据。
Reduce阶段也是一个独立的程序,可以理解未一个单独的居合程序。
查看全部 -
NameNode总结:
 查看全部
查看全部 -
DataNode介绍:
 查看全部
查看全部 -
SecondaryNameNode介绍:
 查看全部
查看全部



举报
0/150
提交
取消