

-
NameNode介绍:
 查看全部
查看全部 -
HDFS包含:
 查看全部
查看全部 -
防火墙状态查看
centos 6
service iptables status
临时关闭
service iptables stop
开机启动移除
chkconfig iptables off
查看全部 -
Hadoop3中的三大组件的基本理论和实际操作
Hadoop3的使用,掌握企业实际开发流程
实际案例
查看全部 -
快入入门知识点
查看全部 -
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://Hadoop:19888/jobhistory/logs/</value>
</property>
查看全部 -
hadoop三大部分:
分布式存储
分布式计算
集群资源管理
Spark、Flink都会使用资源管理
查看全部 -

使用第三个HDP
查看全部 -
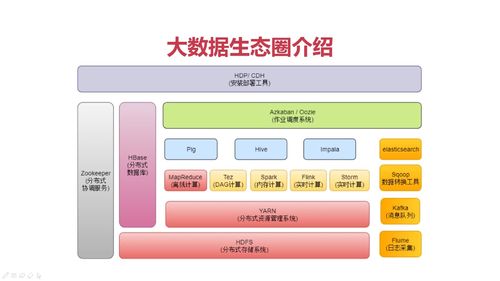
常见框架。
查看全部 -
先把计算和调度管理解耦。
HDFS的主节点可以支持两个以上。
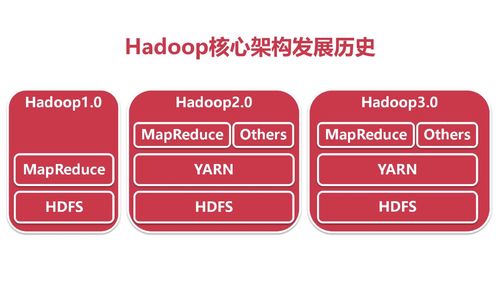 查看全部
查看全部 -

分别是:分布式存储系统,分布式计算框架,集群管理和调度(给程序分配资源)。
Yarm的数据来源和去向都是HDFS.
在Yarm上运行很多的计算框架,例如mapreduce.

HDFS架构分析:
分布式存储:由HDFS决定数据存储在哪个从节点上。
支持主从架构:

Map Reduce架构:
map体现在代码中就是一个类。
reduce就是一个聚合统计程序。

Yarm架构:

总结:数据存储和资源调度都是分布式的主从结构。
查看全部 -
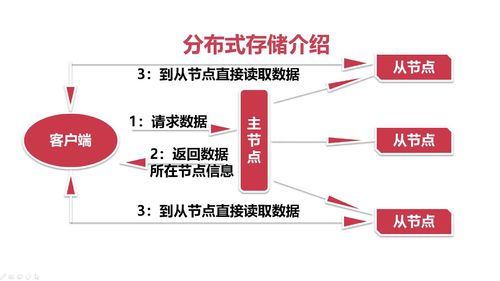
分布式存储,单机的存储能力有限,运用到多台机器的存储能力。
如何设备一个分布式存储系统。
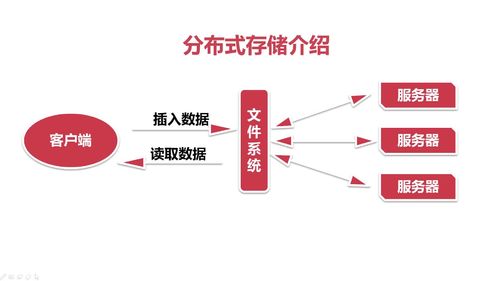
弊端:如何同时有很多请求同时过来,文件系统的请求会阻塞。
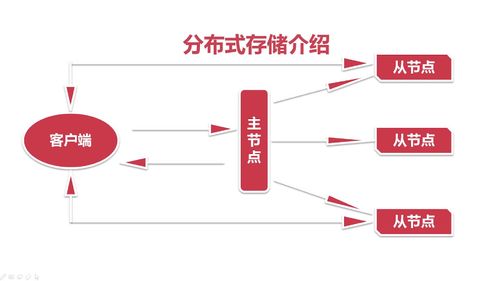
主从架构,你想要操作的数据到底在哪个从节点上,然后客户端直接操作从节点。
主要流程:
 查看全部
查看全部 -
大数据在linux上运行和操作,安装部署、排查、基本的命令。
linux里面的一门shell脚本,如何开发 调试 执行脚本就行了。
javaSE内容,大多数都是java开发,不需要javaweb内容,使用IDEA工具。
数据存储在mysql数据库中。
查看全部 -
核心是数据清洗和计算的逻辑。前端用bi实现
查看全部 -
11

 查看全部
查看全部








举报