

-
词频-你文件频率(TF-IDF)
缺点:
词频(TF)和逆文件频率(IDF)的统计和计算都直接从语料统计得出,当增加语料的时候,TF和IDF往往需要重新计算,无法增量更新,每次添加语料,需要重新计算词频。
没有考虑特征词的位置因素对文本的区分度,词条出现在文档的不同位置时,对区分度贡献大小是不一样的。
按照传统TF-IDF,往往一些生僻词的IDF(反文档频率)会比较高、因此这些生僻词往往会被误认为是文档关键词。
查看全部 -
One-Hot缺点:
1.词通常很多,几十万个词,那就需要句子长度x几十万的矩阵才能表示这个句子
2.这种方法效率低下,矩阵包含很多零
3.无法表达相似性
4.新加一个词我们需要重新计算
查看全部 -
One-Hot理解:
先给句子分词,分词组从词表,词表有索引,然后编码形成矩阵
查看全部 -
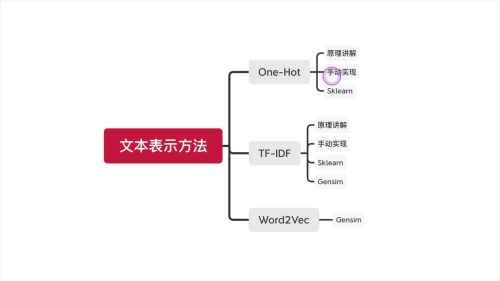
文本表示方法:One-Hot、TF-IDF、Word2Vec
查看全部 -
缺点:
浪费空间,不利于计算
体现不出单词间的关系
优点:
长度远小于字典长度
向量加爵代表相似度
可以增量添加新词
查看全部 -
一个朴素的想法就是,我们把One-Hot中0的位置也利用起来,并且用浮点数来表示词特性,这样我们就可以用固定的,较小的维度来表达海量的信息
查看全部 -
IDF 是逆文件频率,表示关键词的普遍程度。
如果包含词条i的文档越少,IDF越大,则说明该词条具有很好的类别区分能力。
某一特定词语的IDF,可以由总文件数目除以包含该词语的文件数目,再将得到的商取对数得到。
查看全部 -
不懂的名词儿:
卷积
过拟合
loss
激活函数
embedding层
查看全部 -
试试笔记功能,调阈值
查看全部 -
老师,代码在哪里呀?4章 和5 章
查看全部 -
建模区别:
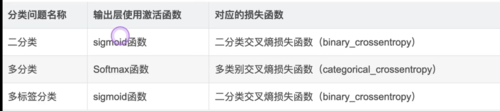 查看全部
查看全部 -
1111
 查看全部
查看全部 -
1
 111111查看全部
111111查看全部 -
22222
查看全部 -
github
 查看全部
查看全部 -
独热编码的缺点
 查看全部
查看全部 -
独热编码(one-hot)
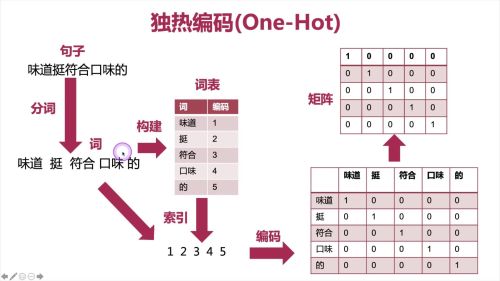 查看全部
查看全部 -
文本表示方法
 查看全部
查看全部 -
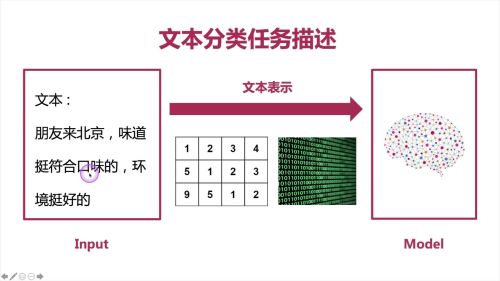
文本分类任务描述
 查看全部
查看全部 -
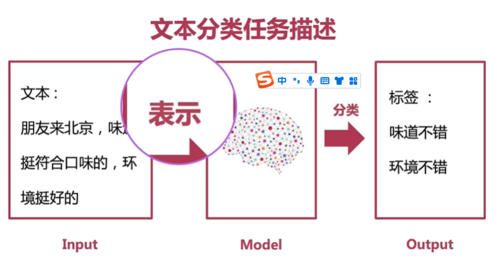
文本分类任务描述
 查看全部
查看全部 -
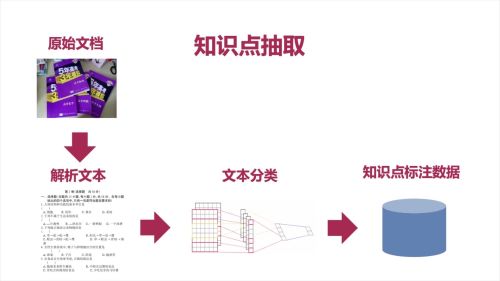
应用——知识点抽取
 查看全部
查看全部 -
应用-----非结构化信息提取
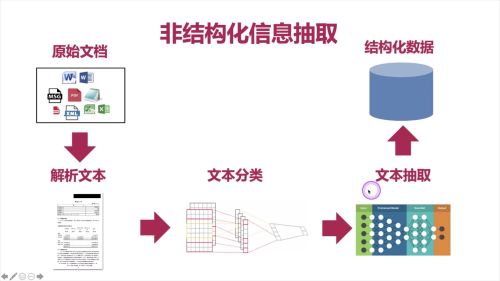 查看全部
查看全部 -
应用--意图识别
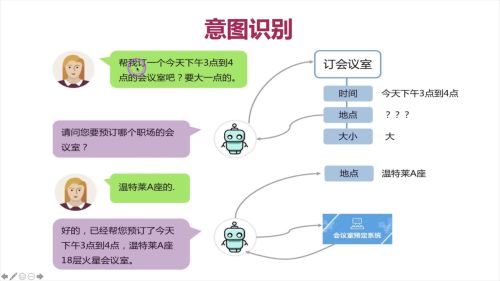 查看全部
查看全部 -
应用,情感分析
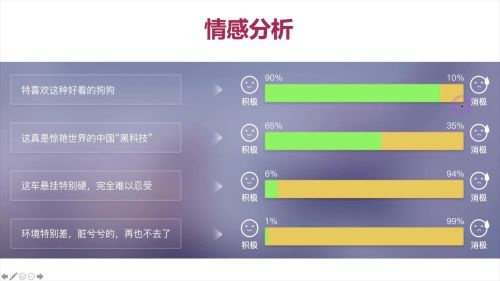 查看全部
查看全部 -
文本分类任务描述
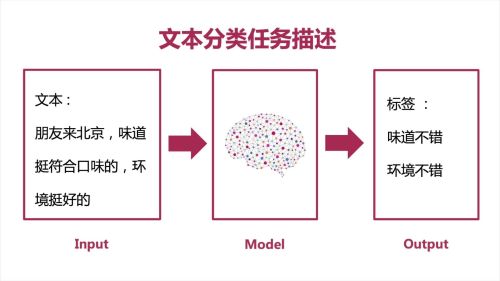 查看全部
查看全部 -
我的笔记笔记笔记,自然期刊
查看全部 -
我的笔记笔记笔记,自然自然
查看全部 -
我的笔记笔记笔记,自然
查看全部 -
我的笔记笔记笔记,自然
查看全部 -
我的笔记啊啊啊 我的笔记啊啊啊 我的笔记啊啊啊 我的笔记啊啊啊 我的笔记啊啊啊
查看全部 -
我的笔记啊啊啊
查看全部 -
 查看全部
查看全部 -
查看全部
-

你是
查看全部 -
噻 。噻. ..xx t … x ,哦查看全部
-
哈哈哈哈哈哈哈哈哈1111
查看全部 -

呢几天不知道🤷♀️、不过

那种习惯真的不好吃的
 查看全部
查看全部 -

里来来去去
查看全部 -

笔记为啥看不了呢
查看全部 -
特别好
查看全部 -
场景应用查看全部
-
夸克星8805
在自然语言处理中,若有个字典或字库里有N个单字,则每个单字可以被一个N维的one-hot向量代表。譬如若字库里仅有apple(苹果),banana(香蕉),以及pineapple(凤梨)这三个单字,则他们各自的one-hot向量可以为:
由于电脑无法理解非数字类的数据,One-hot编码可以将类别性数据转换成统一的数字格式,方便机器学习的算法进行处理及计算。而转换成固定维度的向量则方便机器学习算法进行线性代数上的计算。另外由于一个one-hot向量中,绝大部分的数字都是0,所以若使用稀疏矩阵的数据结构,则可以节省电脑内存的使用量0
查看全部 -
keras中交叉熵使用
 查看全部
查看全部
















举报