

-
下载软件地址: wget https://archive.apache.org/dist/hadoop/common/hadoop-1.2.1/hadoop-1.2.1.tar.gz
配置hadoop文件:
1、hadoop-env.sh
配置java 环境变量的地址
2、 core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/hadoop</value>
</property>
</configuration>
<property>
<name>dfs.name.dir</name>
<value>/hadoop/name</value>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://imooc:9000</value>
</property>
查看全部 -
https://archive.apache.org/dist/hadoop/common/hadoop-1.2.1/hadoop-1.2.1.tar.gz
查看全部 -
HDFS特点: 1、数据冗余,硬件容错(一式三份来保证) 2、流式数据访问:写一次,读多次,一旦写入无法修改,只能通过写入到新的块删除旧文件 3、存储大文件(特适合,因为小文件多,势必加重NameNode的负担) HDFS适用性及局限性: 1、适合数据批量读写,吞吐量高 2、不适合交互式应用、低延迟很难满足 3、适合一次写入多次读取、顺序读写 4、不支持多用户并发写相同文件查看全部
-
常用Hadoop的shell命令: #hadoop fs -format #格式化操作 #hadoop fs -ls / #展示文件 #hadoop fs -cat input/hsdf-site.xml #查看Hadoop里面的指定文件 #hadoop fs -mkdir input #未指明目录,表示在Hadoop的文件系统下的默认目录/user/root下新建 #hadoop fs -put hdsf-site.xml input/ #上传文件到Hadoop #hadoop fs -get hdfs-site.xml hdfs-site2.xml #从Hadoop下载文件 #hadoop dfsadmin -report #查看HADF使用情况(所有信息)查看全部
-
下载hadoop: wget http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-1.2.1/hadoop-1.2.1.tar.gz查看全部
-
datanode中一份数据会有3个副本,分别存在于不同的两个机架中;secondarynamenode是二级namenode;datanode和namenode会有不定期的心跳检测。查看全部
-
Hadoop是解决大数据的分布式集成架构。当数据达到一定规模时,单机的存储和分析就变得非常困难,存储量和效率都无法达到用户的需求。所以,为了解决大数据的存储和处理,Google提出了三大技术MapReduce,BigTable,GFS,相比于Google之前的解决方案,它有如下优势(1)降低成本,能用PC机就不用大型机和高端存储;(2)因为用的是PC机,所以经常发生硬件错误,所以通过软件来保证高可靠性;(3)简化了并行分布式计算。Hadoop是模仿Google三大技术的开源实现。查看全部
-
课程学习建议: 1.结合书本,知识点更加系统全面 对应的书本:hadoop技术详解、hadoop权威指南 2.实践经验很重要,边听课边实践。 课程预备知识: linux常用命令 java编程基础查看全部
-
imN查看全部
-
安装hadoop: 1、准备liunx环境; 2、安装JDK; 3、配置hadoop; 新搭建方式:使用云主机进行配置查看全部
-
大数据存储和处理技术原理查看全部
-
mkdir examples //生成一个examples目录
cd examples //进入examples文件路径
mkdir word_count //生成word_count目录
cd word_count //进入word_count目录
mkdir input //用于存放提交的作业
mkdir word_count_class //用于存放编译好的类
vim WordCount.java // 编写好java程序后保存,资料下载里面有
javac -classpath /opt/hadoop-1.2.1/hadoop-core-1.2.1.jar:/opt/hadoop-1.2.1/lib/commons-cli-1.2.jar -d word_count_class/ WordCount.java //因为编译WordCount.java过程需要引用hadoop封装类,所以需要引用
jar -cvf wordcount.jar *.class //将当前目录下的所有class都打包进wordcount.jar文件中
cd .. //返回上级word_count目录
cd input
vim file1 //编辑好file1 之后保存 ,file1里面为需要提交的作业
vim file2 // 类似
cd .. //返回到word_count目录
hadoop fs -mkdir input_wordcount //创建一个hadoop 目录,用于存放提交的作业
hadoop fs -put input/* input_wordcount //将本地的作业提交到input_wordcount目录中
hadoop fs -ls input_wordcount //查看文件是否在该目录下
hadoop jar word_count_class/wordcount.jar WordCount input_wordcount output_wordcount //提交jvm运行的jar,同时提交运行的主类,input..和out..分别用于保存提交的作业和运行结束的作业
....
....
....
等待程序运行, ok
查看全部 -
安装后配置hadoop文件
一、设置java目录和hadoop目录:
vi /etc/profile
JAVA_HOME=/etc/usr/java/jdk-1.8.1
JAR_HOME=$JAVA_HOME/jre
HADOOP_HOME=/etc/usr/hadoop-1.2.1
PATH=$JAVA_HOME/bin:$JAR_HOME/bin:$HADOOP_HOME/bin:$PAHT
二、修改四个配置文件
1、core-site.xml(haddop.temp.dir、dfs.name.dir、fs.default.name)
<configuration> <property> <name>hadoop.tmp.dir</name> <value>/hadoop</value> </property> <property> <name>dfs.name.dir</name> <value>/hadoop/name</value> </property> <property> <name>fs.default.name</name> <value>hdfs://imooc:9000</value> </property> </configuration>
2、修改mapred-site.xml(mapred.job.tracker)
<configuration> <property> <name>mapred.job.tracker</name> <value>imooc:9001</value> </property> </configuration>
3、修改hsfs-site.xml,设置dfs.data.dir
<property> <name>dfs.data.dir</name> <value>/hadoop/data</value> </property>
4、修改hadoop的环境变量文件hadoop-env.sh
JAVA_HOME=/etc/usr/java/jkd-1.8.1
三、对hadoop进行格式化已经启动:
hadoop namenode -format
start-all.sh
jps=》查看hadoop是否安装成功
查看全部 -
HDFS 分布式文件系统
MapReduce 并行处理矿建
HIVE 将SQL语句转化为Hadoop任务 ,降低使用门槛
HBASE 存储结构化数据的分布式数据库
(放弃了事务特性 最求更高的扩展)
zookeeper 监控Hadoop集群的状态、管理配置、维护节点一次性
查看全部 -
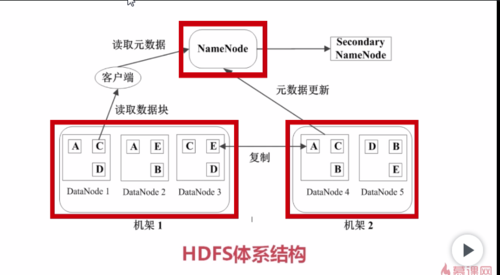
HDFS的文件被分成块进行存储,HDFS块默认大小是64MB,快是整个文件存储处理的逻辑单元
HDFS中有两类节点NameNode和DataNode
namenode是管理节点,存放文件元数据,元数据包含两个部分
文件与数据快的映射表
数据块与数据节点的映射表
namenode是唯一的管理节点,里面存放大量元数据,客户进行访问请求,首先会到namenode查看元数据,这个文件放在哪些节点上面然后从这些节点拿数据块,然后组装成想要的文件
DateNode是HDFS的工作节点,存放数据块
查看全部













举报