

-
大数据:大数据是一个概念也是一门技术,是在以Hadoop为代表的大数据平台框架上进行各种数据分析的技术。
大数据包括了以Hadoop和Spark为代表的基础大数据框架,还包括了实时数据处理,离线数据处理;数据分析,数据挖掘和用机器算法进行预测分析等技术。
查看全部 -
常用HDFS Shell命令:
1、类Linux系统:ls、cat、mkdir、rm、chmod、chown等
2、HDFS文件交互:copyFromLocal(从本地系统->HDFS系统)、copyToLocal(从HDFS系统->本地系统)、get(下载文件)、put(上传文件)
查看全部 -
两个思考问题 :
1.数据块的大小设置为多少合适为什么?
hadoop数据块的大小一般设置为128M,如果数据块设置的太小,一般的文件也会被分割为多个数据块,在访问的时候需要查找多个数据块的地址,这样的效率很低,而且如果数据块设置太小的话,会消耗更多的NameNode的内存;而如果数据块设置过大的话,对于并行的支持不是太好,而且会涉及系统的其他问题,比如系统重启时,需要从新加载数据,数据块越大,耗费的时间越长。
2.NameNode有哪些容错机制,如果NameNode挂掉了怎么办?
NameNode容错机制,目前的hadoop2可以为之为HA(高可用)集群,集群里面有两个NameNode的节点,一台为主节点,一台为从节点,两者的数据时刻保持一致,当主节点出现问题时,从节点可以自动切换,用户基本感知不到,这样就避免了NameNode的单点问题。
HDFS写流程:
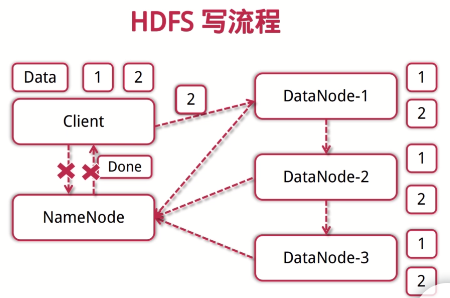
1.客户端向NameNode发起写数据
2.分块写入DataNode节点,DataNode自动完成副本备份
3.DataNode向NameNode汇报存储完成,NameNode通知客户端
HDFS读流程:
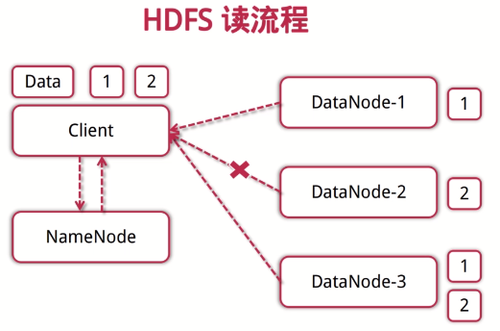
1.客户端向NameNode发起读数据的请求
2.NameNode找出最近的DataNode节点信息返回给客户端
3.客户端从DataNode分块下载文件
查看全部 -
Hadoop核心
HDFS分布式文件系统:存储是大数据技术的基础
MAPReduce编程模型:分布式计算是大数据应用的解决方案
HDFS 概念
数据块:是抽象快而非整个文件作为存储单元,默认大小为64MB,一般设置为128MB,备份X3
NameNode:
管理文件系统的 ,存放文件元数据
维护文件系统的所有文件和目录,文件与文件块的映射
记录每个文件中各个块所在数据节点 的信息
DataNode
存储并检索数据块
向NameNode更新所存储块的列表
HDFS优点
适合大数据存储,支持TB/PB级的数据存储,并有副本策略
可构建在廉价的机器上,并有一定 的容错和恢复机制
支持流式数据访问,一次写入,多次读取最高效
HDFS缺点
不适合大量小文件存储
不适合并发写入 ,不支持文件随机修改
不支持随机读等低延时的访问方式
查看全部 -
Hadoop=HDFS(分布式文件系统)+MapReduce(分布式计算)
HDSF数据块 64M-128M
NameNode:管理文件系统的命名空间,存放文件元数据
维护着文件系统的所有文件和目录,文件与数据块的映射
记录每个文件中各个块所在节点的信息
DataNode :存储并检索数据库块
向NameNode更新所存储块的列表
HDFS优点:适合大文件存储,支持TB,PB级别的数据存储
构建在廉价机器上,有副本,容错和恢复机制
支持流式数据的访问,一次写入,多次读取最高效
HDFS缺点:不适合大量小文件存储
不适合并发写入,不支持文件随机修改
不支持随机读等低延迟的访问
查看全部 -
Hadoop
查看全部 -
HDFS写流程:客户端向NameNode发起写数据请求,分块写入DataNode节点,DataNode自动完成副本备份,然后向NameNode汇报存储完成,由NameNode通知客户端
HDFS读流程:客户端向NameNode发起读数据请求,NameNode找出距离最近的DataNode节点信息,客户端从DataNode分块下载文件
查看全部 -
HDFS概念:
数据块:抽象块而非整个文件作为存储单元。默认大小为64MB,一般设置为128MB,备份x3。易于备份。
NameNode:一个,管理文件系统的命名空间,存放文件元数据。维护着文件系统的所有文件和目录,文件与数据块的映射。记录每个文件中各个块所在数据节点的信息。
DataNode:存储并检索数据块,向 NameNode 更新所存储块的列表。
【问】:如果NameNode出现错误,该怎么办?
【答】:对NameNode进行备份?
查看全部 -
MapReduce编程模型 就是分而治之的方法论
Hadoop1.0 与 Hadoop2.0的区别
查看全部 -
数据分块的依据是什么 如何确定一个文件存储的时候要分成多少个数据块呢?
datanode之间进行数据复制是如何实现的呢?复制的过程会不会出现失败的情况,如果失败了怎么办?有什么机制
查看全部 -
MapReduce简介
MapReduce是一种编程模型,是一种编程方法,是抽象的理论;
YARN(Haoop2之后的资源管理器)概念
1.ResourceManager:分配和调度资源;启动并监控ApplicationMaster; 监控NodeManager
2.ApplicatonMaster:为MR类型的程序申请资源,并分配给内部任务;负责数据的切分;监控任务的执行及容错;
3.NodeManager:管理单个节点的资源;处理来自ResourceManager的命令;处理来自ApplicationMaster的命令
MapReduce编程模型
输入一个大文件,通过Split之后,将其分为多个分片;
每个文件分片由单独的机器去处理,这就是Map方法 ;
将各个机器计算的结果进行汇总并得到最终的结果,这就是Reduce方法;
查看全部 -
通过Shell命令对HDFS进行操作:与Linux操作文件类似
HDFS实战
常用HDFS Shell命令:
类Linux系统:ls , cat , mkdir , rm , chmod , chown等
HDFS文件交互:copyFromLocal, copyToLocal , get , put
mk.txt 上传到 hdfs系统
1.在 /home 目录下 新建mk.txt :
touch(或vi) mk.txt
2.看一下hdfs根目录下有什么:
hdfs dfs -ls /
3.创建test目录 :
hdfs dfs -mkdir /test
看一下
hdfs dfs -ls /
4.mk.txt 上传到 test 下 (copyFromLocal)
hdfs dfs -copyFromLocal /hmoe/mk.txt /test/
看一下
hdfs dfs -ls /test
5.查看mk.txt的内容
hdfs dfs -cat /test/mk.txt
6.mk.txt 上传到本地目录下改名为 mk2.txt(copyToLocal)
hdfs dfs -copyToLocal /test/mk.txt /home/mk2.txt
看一下本地
ls
7.更改test的权限: 读4 写2 执行1
hdfs dfs -chmod 777 /test/mk.txt
hdfs dfs -ls /test
8.帮助文档
hdfs dfs -help
查看全部 -
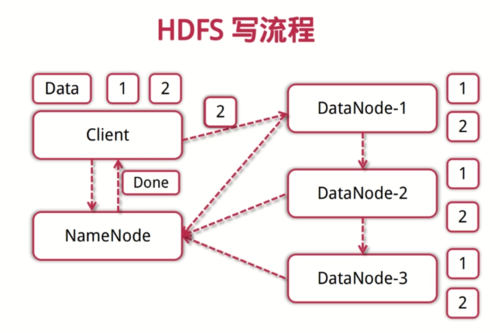
HDFS写流程
客户端向NameNode发起写数据请求
分块写入DataNode节点,DataNode自动完成副本备份
DataNode向NameNode汇报储存完成NameNode通知客户端
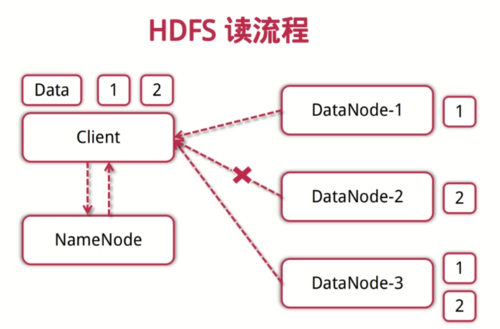
HDFS读流程
1. 客户端向NameNode发起读数据请求;
2. NameNode找出距离最近的DataNode节点信息;
3. 客户端从DataNode分块下载文件;
查看全部 -
Hadoop(分布式计算)
Hadoop是一个开源的大数据框架;
Hadoop是分布式计算的解决方案;
Hadoop = HDFS(分布式文件系统) (存储)+ MapReduce(分布式计算)
Hadoop核心:
HDFS分布式文件系统:储存是大数据技术的基础
MapReduce 编程模型:分布式计算是大数据应用的解决方案
HDFS总结:
普通的成百上千台机器;
TB甚至PB为单位的大量的数据;
简单便捷的文件获取;
Hadoop基础架构
HDFS概念:
1.数据块
数据块是抽象块,而非整个文件作为存储单元;
默认大小为64M,一般设置128M,备份3个;
2.NameNode(HDFS一个NameNode多个DataNode组成)
管理文件系统的命名空间,存放文件元数据;
维护着文件系统的所有文件和目录,文件与数据块的映射;
记录每个文件中各个块所在数据节点的信息;
3.DataNode
存储并检索数据块;向NameNode更新所存储块的列表;
HDFS优点:
适合大文件存储,支持TB、PB级别的数据存储,并有副本策略;
可以构建在廉价的机器上,并有一定的容错和恢复机制;
支持流式数据访问,一次写入,多次读取最高效;
HDFS缺点:
不支持大量小文件的存储;
不适合并发写入,不支持文件随机修改;
不支持随机读等低延时的访问方式;
查看全部 -
YARN(Haoop2之后的资源管理器)概念
1.ResourceManager:分配和调度资源;启动并监控ApplicationMaster; 监控NodeManager
2.ApplicatonMaster:为MR类型的程序申请资源,并分配给内部任务;负责数据的切分;监控任务的执行及容错;
3.NodeManager:管理单个节点的资源;处理来自ResourceManager的命令;处理来自ApplicationMaster的命令
MapReduce是一种编程模型,是一种编程方法,是抽象的理论;
MapReduce编程模型
输入一个大文件,通过Split之后,将其分为多个分片;每个文件分片由单独的机器去处理,这就是Map方法 ;将各个机器计算的结果进行汇总并得到最终的结果,这就是Reduce方法;
查看全部












举报