
































































 沈无奇 ·
沈无奇 ·Scrapy 抓取起点中文网(上):实现登录和认证
本小节将完成一个有趣的 Scrapy 爬虫项目,主要实现的主要功能如下:
- 实现网站登录,得到相应的个人信息,比如用户信息,我的书架等,并实现一键删除书架上所有书籍的功能;
本节和接下来的一节都是实战环节,用于梳理 Scrapy 爬虫框架的基本使用,也为巩固和加深前面所学知识。
1. 基于 Cookie 的自动登录
如果是想基于基本的 API 方式登录,我们会面临两大难点:
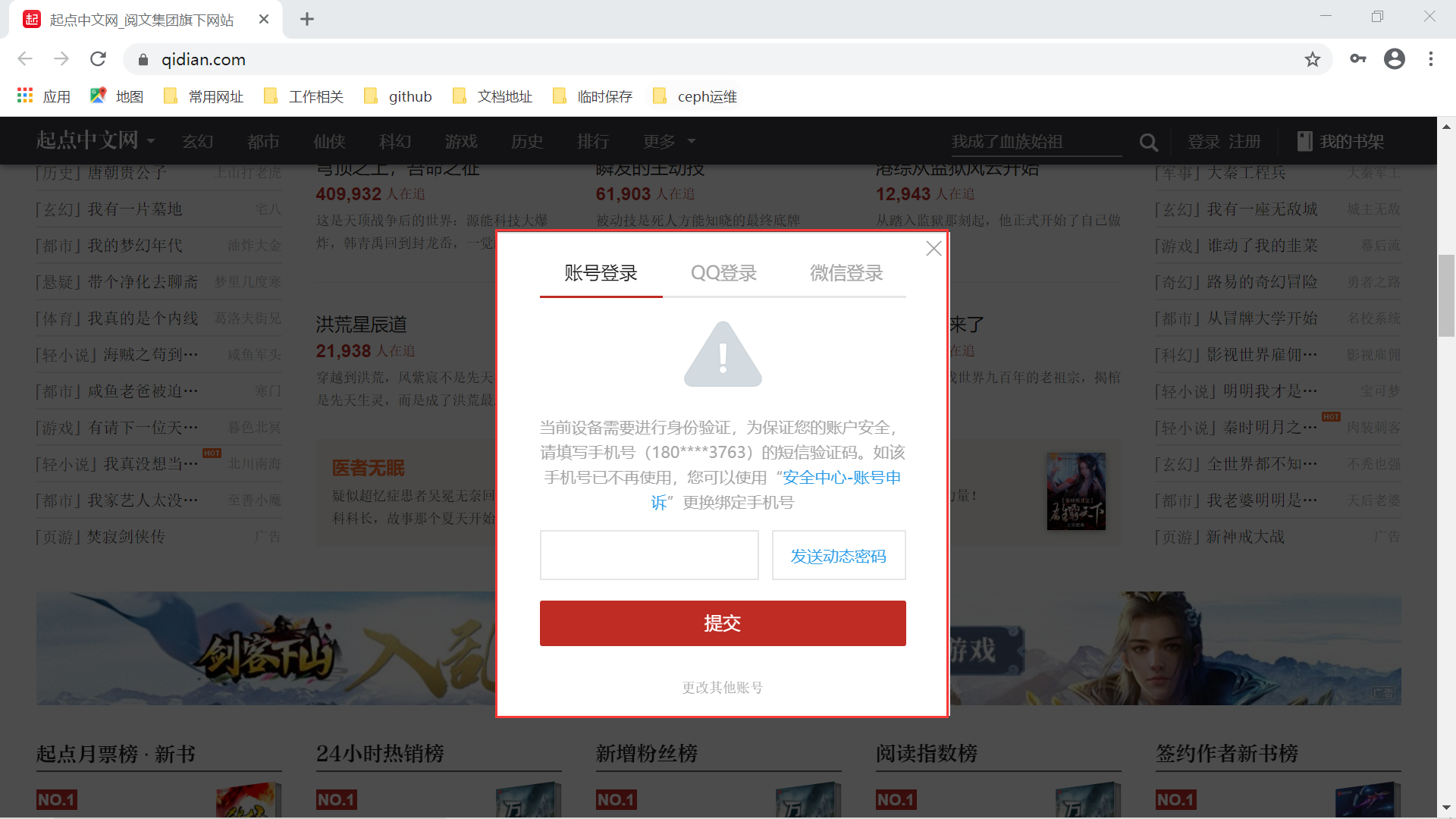
- 手机验证码校验 ,如下图所示:

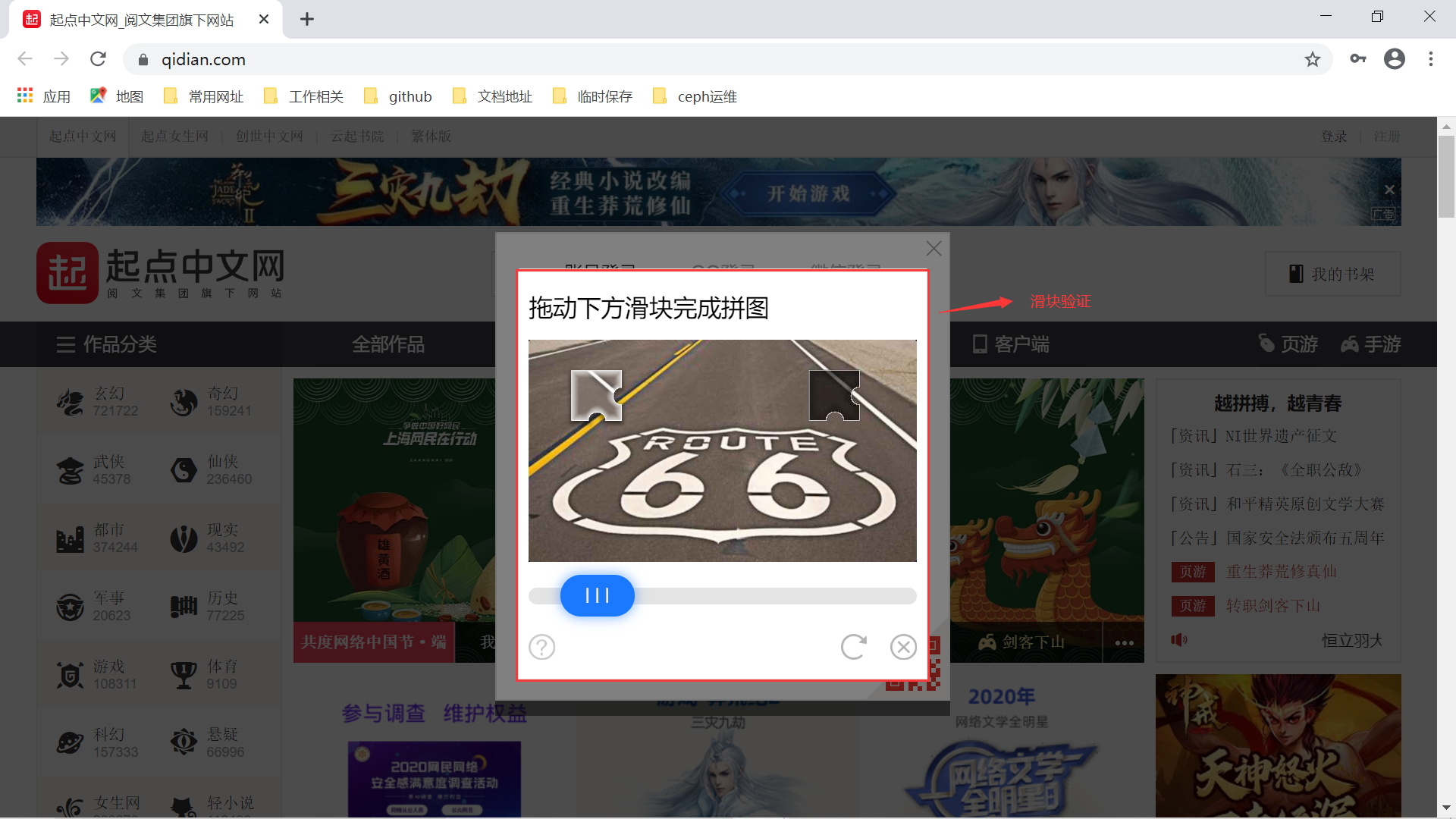
- 滑动验证码校验,如下图所示:
绕过这些校验的方法超过了本教程的知识范围,故我们不再次详细讨论。好在起点网支持自动登录过程,也就是 Cookie 登录:
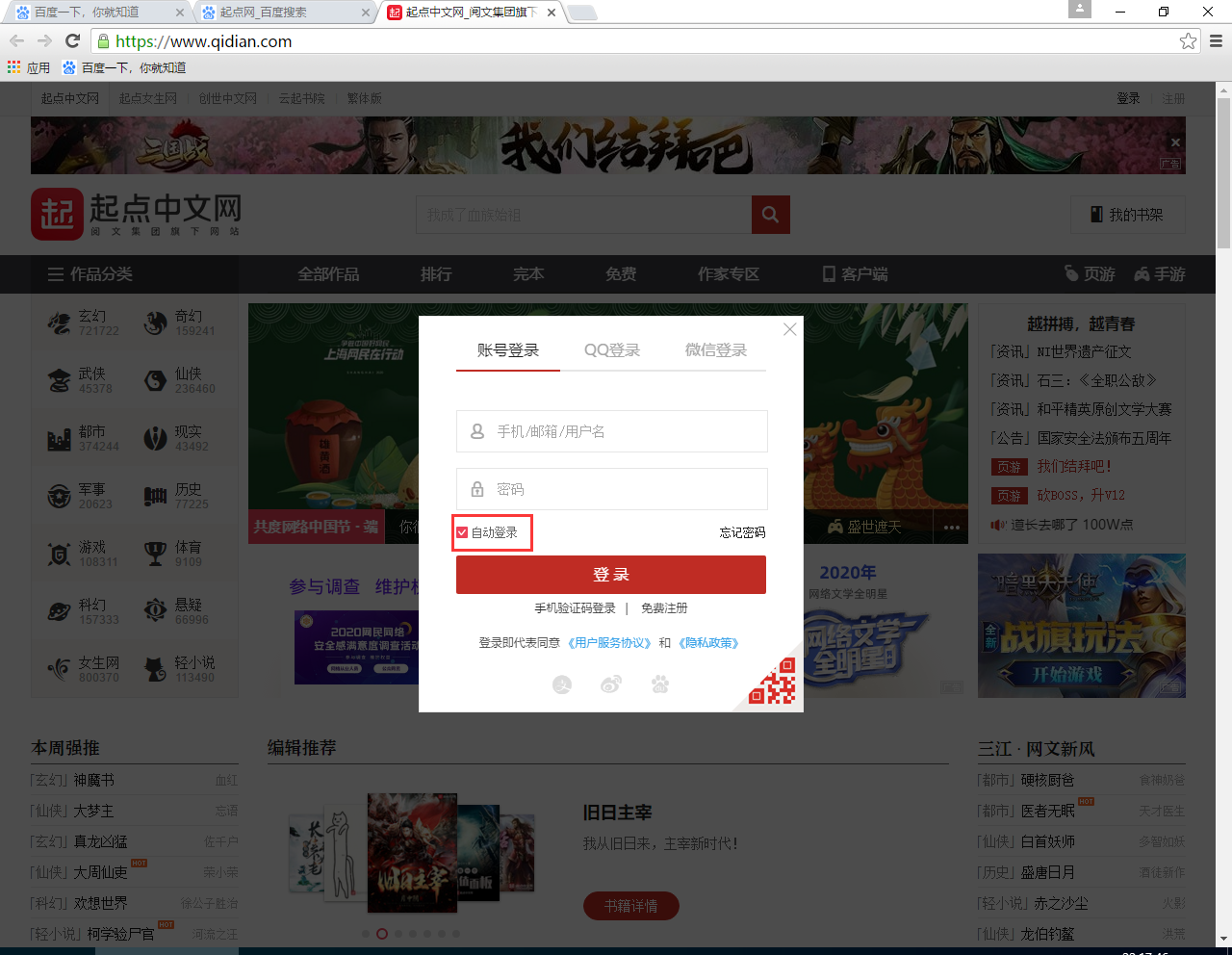
第一次手动登录起点,选择自动登录后,起点网站返回的 Cookie 信息就会保存至本地。下次再访问起点网时,通过请求带上该 Cookie 信息就能正确识别用户,实现自动登录过程。Cookie 存在本地,就存在被代码读取的可能。通常而言,我们来使用 Python 中的 browsercookie 库可以获取浏览器的 cookie,目前它只支持 Chrome 和 FireFox 两种浏览器。不过对于 Chrome 80.X 版本的浏览器,其中的 cookie 信息被加密了,我们无法按照早期的操作进行 cookie 读取。
不过网上这个博客给出了一个解密 Cookie 的代码,我们拿过来简单改造下,做成一个辅助模块:
# 参考文档:https://blog.csdn.net/u012552769/article/details/105001108
import sqlite3
import urllib3
import os
import json
import sys
import base64
from cryptography.hazmat.backends import default_backend
from cryptography.hazmat.primitives.ciphers import Cipher, algorithms, modes
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
def dpapi_decrypt(encrypted):
import ctypes
import ctypes.wintypes
class DATA_BLOB(ctypes.Structure):
_fields_ = [('cbData', ctypes.wintypes.DWORD),
('pbData', ctypes.POINTER(ctypes.c_char))]
p = ctypes.create_string_buffer(encrypted, len(encrypted))
blobin = DATA_BLOB(ctypes.sizeof(p), p)
blobout = DATA_BLOB()
retval = ctypes.windll.crypt32.CryptUnprotectData(
ctypes.byref(blobin), None, None, None, None, 0, ctypes.byref(blobout))
if not retval:
raise ctypes.WinError()
result = ctypes.string_at(blobout.pbData, blobout.cbData)
ctypes.windll.kernel32.LocalFree(blobout.pbData)
return result
def aes_decrypt(encrypted_txt):
with open(os.path.join(os.environ['LOCALAPPDATA'],
r"Google\Chrome\User Data\Local State"), encoding='utf-8', mode="r") as f:
jsn = json.loads(str(f.readline()))
encoded_key = jsn["os_crypt"]["encrypted_key"]
encrypted_key = base64.b64decode(encoded_key.encode())
encrypted_key = encrypted_key[5:]
key = dpapi_decrypt(encrypted_key)
nonce = encrypted_txt[3:15]
cipher = Cipher(algorithms.AES(key), None, backend=default_backend())
cipher.mode = modes.GCM(nonce)
decryptor = cipher.decryptor()
return decryptor.update(encrypted_txt[15:])
def chrome_decrypt(encrypted_txt):
if sys.platform == 'win32':
try:
if encrypted_txt[:4] == b'x01x00x00x00':
decrypted_txt = dpapi_decrypt(encrypted_txt)
return decrypted_txt.decode()
elif encrypted_txt[:3] == b'v10':
decrypted_txt = aes_decrypt(encrypted_txt)
return decrypted_txt[:-16].decode()
except WindowsError:
return None
else:
raise WindowsError
def get_cookies_from_chrome(domain, key_list):
sql = f'SELECT name, encrypted_value as value FROM cookies where host_key like "%{domain}%"'
filename = os.path.join(os.environ['USERPROFILE'], r'AppData\Local\Google\Chrome\User Data\default\Cookies')
con = sqlite3.connect(filename)
con.row_factory = sqlite3.Row
cur = con.cursor()
cur.execute(sql)
cookie_dict = {}
for row in cur:
if row['value'] is not None:
name = row['name']
value = chrome_decrypt(row['value'])
if value is not None and name in key_list:
cookie_dict[name] = value
return cookie_dict
Tips:上述这段代码不用纠结细节,前面函数的主要是替
get_cookies_from_chrome()函数服务的,而该函数的输入要搜索的网站以及提取相应网站 cookie 信息中的某个具体字段,返回相应的结果。
本人 Python 3.8.2 安装的是 win32 版本,该段代码亲测有效。来看看起点中文网给读者生成的 cookie 数据,我们调用上面的获取 cookie 信息的代码来从中提取相应数据:
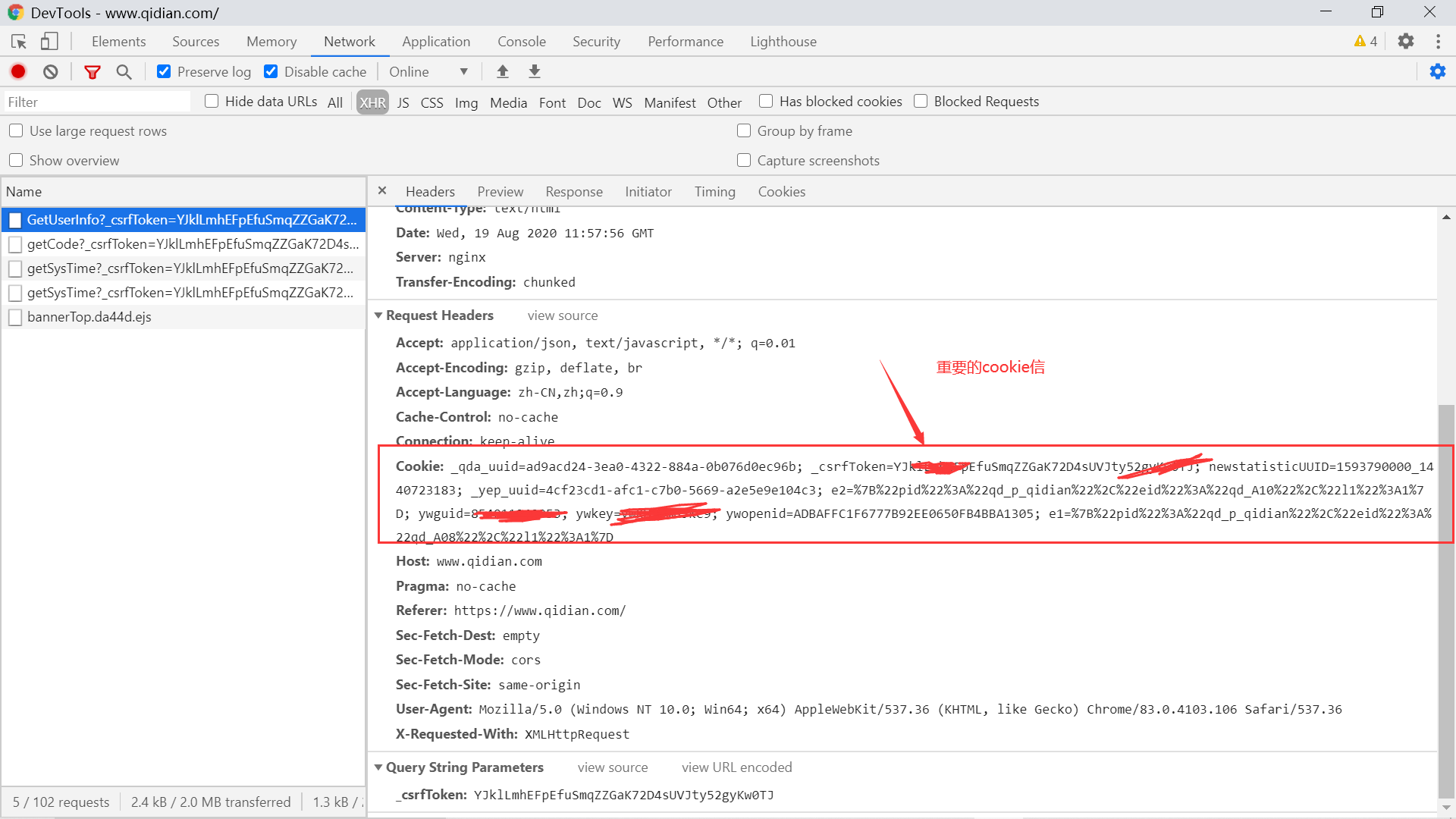
print(get_cookies_from_chrome('qidian.com', '_csrfToken'))
print(get_cookies_from_chrome('qidian.com', 'e1'))
print(get_cookies_from_chrome('qidian.com', 'e2'))
执行上述代码我们可以得到如下结果:
PS C:\Users\spyinx> & "D:/Program Files (x86)/python3/python.exe" c:/Users/spyinx/Desktop/test_cookie.py
{'_csrfToken': 'YJklLmhMNpEfuSmqZZGaK72D4sUVJty52gyKwXXX'}
{'e1': '%7B%22pid%22%3A%22qd_p_qidian%22%2C%22eid%22%3A%22qd_A08%22%2C%22l1%22%3A1%7D'}
{'e2': '%7B%22pid%22%3A%22qd_p_qidian%22%2C%22eid%22%3A%22qd_A10%22%2C%22l1%22%3A1%7D'}
这说明我们通过前面的代码能争取获取到起点网保存在 Chrome 浏览器中的 cookie 信息。因此,前面的代码将作为我们读取起点用户登录 Cookie 的重要辅助模块。
Tips:这个测试只能在装了 Chrome 浏览器的 Windows 系统上进行测试,或者是 Linux 的桌面版
我们首先来创建一个起点爬虫:
PS C:\Users\Administrator\Desktop> scrapy startproject qidian_spider
接下里我们来看看要提取的我的书架的信息:
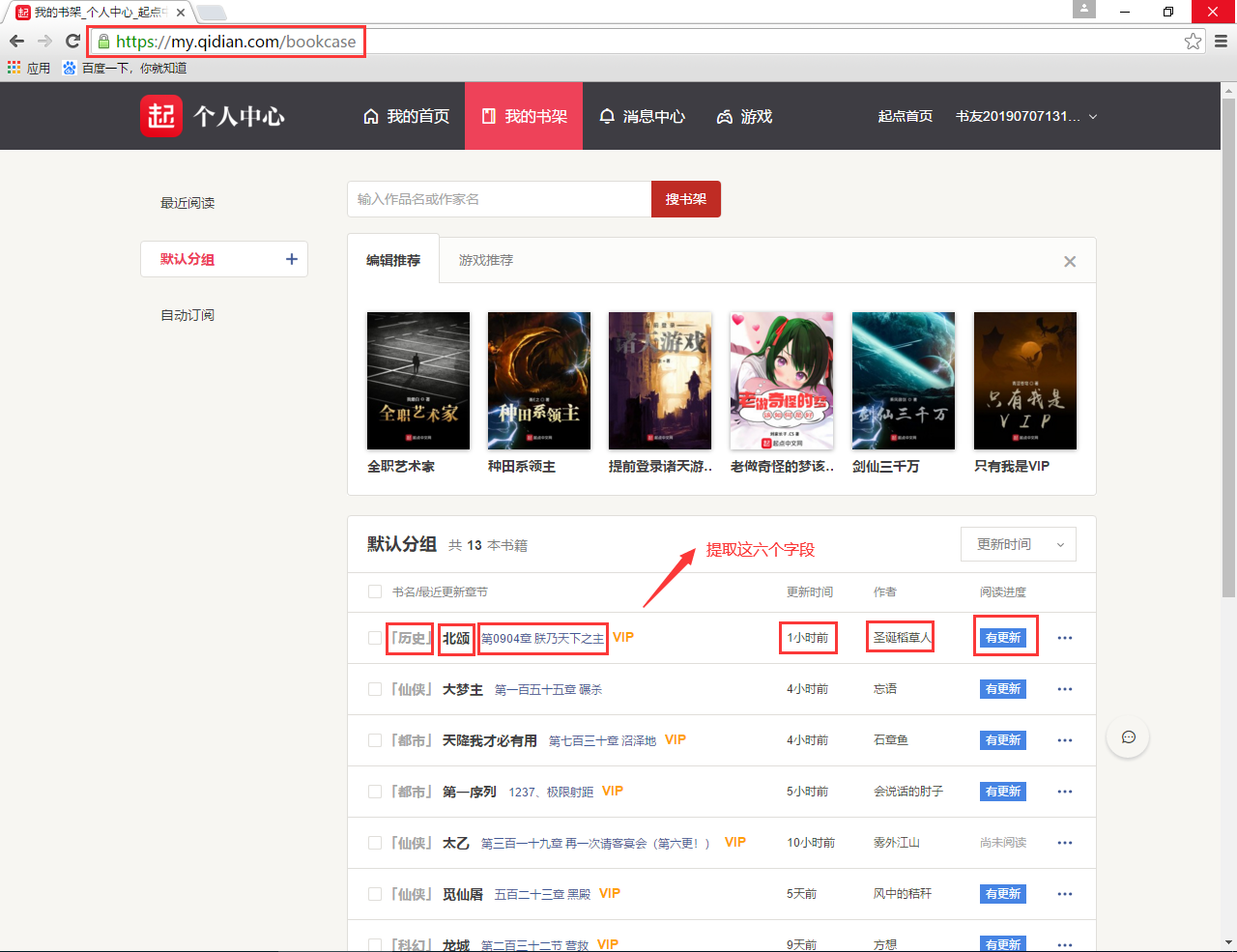
对应的 items.py 的内容如下:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class QidianSpiderItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 分组
category = scrapy.Field()
# 小说名
name = scrapy.Field()
# 最新章节
latest_chapter = scrapy.Field()
# 作者
author = scrapy.Field()
# 更新时间
update_time = scrapy.Field()
# 阅读进度
progress_status = scrapy.Field()
接下来,在爬虫部分需要请求该页面然后提取相应的数据,我们的爬虫代码如下:
"""
获取用户书架数据
"""
import json
from urllib import parse
from scrapy import Request
from scrapy.spiders import Spider
from .get_cookie import get_cookies_from_chrome
from ..items import QidianSpiderItem
class BookCaseSpider(Spider):
name = "bookcase"
# 构造函数
def __init__(self):
# 最重要的就是这个获取起点的cookie数据了,这里保存了之前用户登录的cookie信息
self.cookie_dict = get_cookies_from_chrome(
"qidian.com",
["_csrfToken", "e1", "e2", "newstatisticUUID", "ywguid", "ywkey"]
)
def start_requests(self):
url = "https://my.qidian.com/bookcase"
# http请求时附加上cookie信息
yield Request(url=url, cookies=self.cookie_dict)
def parse(self, response):
item = QidianSpiderItem()
books = response.xpath('//table[@id="shelfTable"]/tbody/tr')
for book in books:
category = book.xpath('td[@class="col2"]/span/b[1]/a[1]/text()').extract_first()
name = book.xpath('td[@class="col2"]/span/b[1]/a[2]/text()').extract_first()
latest_chapter = book.xpath('td[@class="col2"]/span/a/text()').extract_first()
update_time = book.xpath('td[3]/text()').extract_first()
author = book.xpath('td[@class="col4"]/a/text()').extract_first()
progress_status = book.xpath('td[@class="col5"]/a/text()').extract_first()
item['category'] = category
item['name'] = name
item['latest_chapter'] = latest_chapter
item['update_time'] = update_time
item['author'] = author
item['progress_status'] = progress_status
print(f'get item = {item}')
yield item
最重要的方法就是那个获取 cookie 信息的方法了,正是靠着这个 cookie,我们才能获取相应的用户书架的网页并提取相应的书籍信息。接下来,简单实现一个 item pipeline 用于保存书架上的书籍信息,该代码位于 scrapy/pipelines.py 文件中,默认的 pipelines 都写会在这里:
# 源码位置:scrapy/pipelines.py
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
import json
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class QidianSpiderPipeline:
def open_spider(self, spider):
self.file = open("bookcase.json", 'w+', encoding='utf-8')
def close_spider(self, spider):
self.file.close()
def process_item(self, item, spider):
data = json.dumps(dict(item), ensure_ascii=False)
self.file.write(f"{data}\n")
return item
最后别忘了在 settings.py 中添加这个 item pipeline:
ITEM_PIPELINES = {
'qidian_spider.pipelines.QidianSpiderPipeline': 300,
}
我们运行下这个爬虫,看看是否能抓到我们想要的数据:
PS C:\Users\Administrator\Desktop> scrapy crawl bookcase
最后的结果如下:
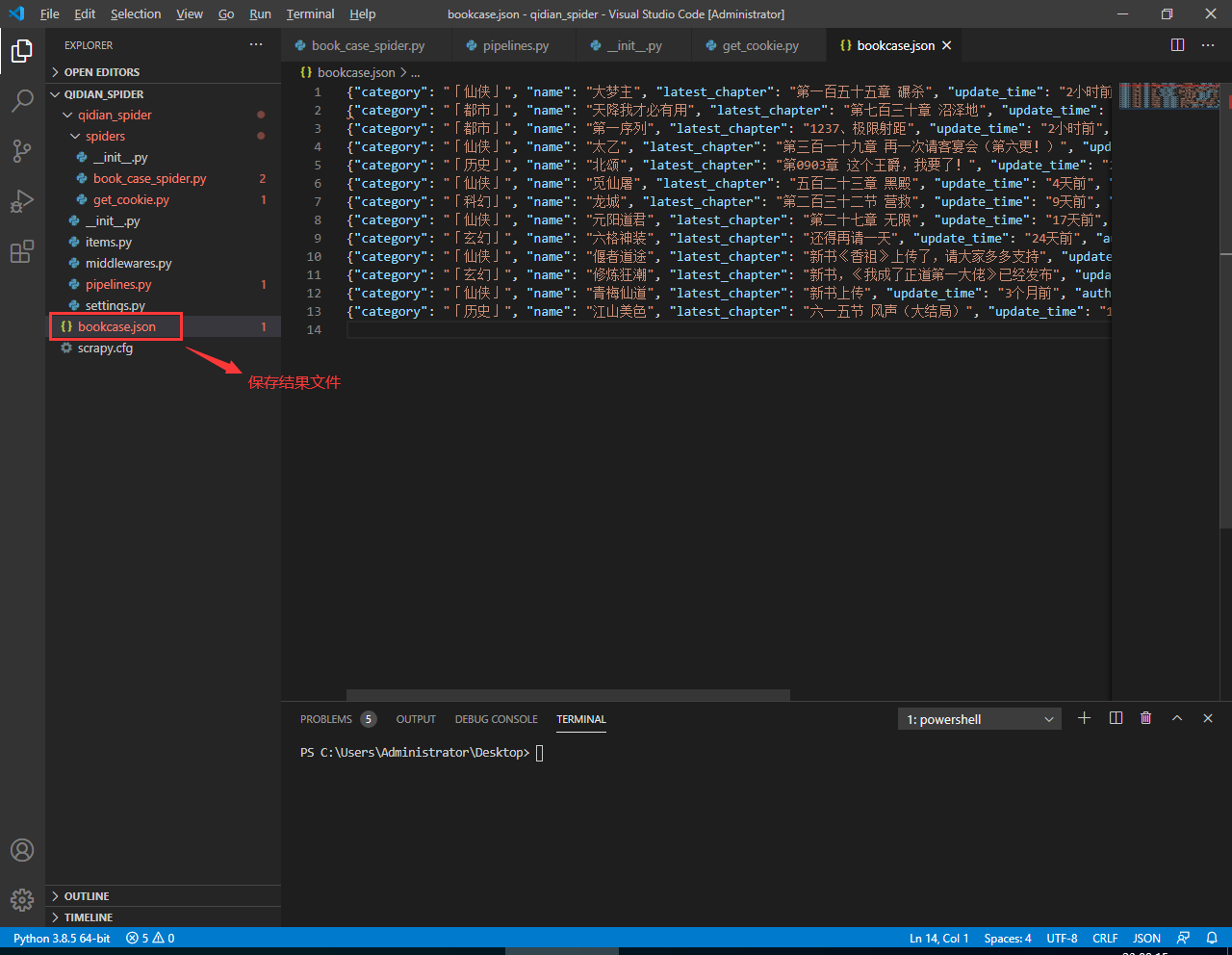
这样,我们就成功实现了用户登录后的访问动作。接下来我们在这个基础上进一步扩展,实现清除书架上所有的书籍,类似于淘宝的一键清除购物车。
2. 删除起点网用户的所有书架
首先我们随便添加一个书籍到书架上,然后进行清楚,请看下图,通过 Chrome 开发者工具我们可以找到删除书架上书籍的 URL 请求以及相应携带参数:
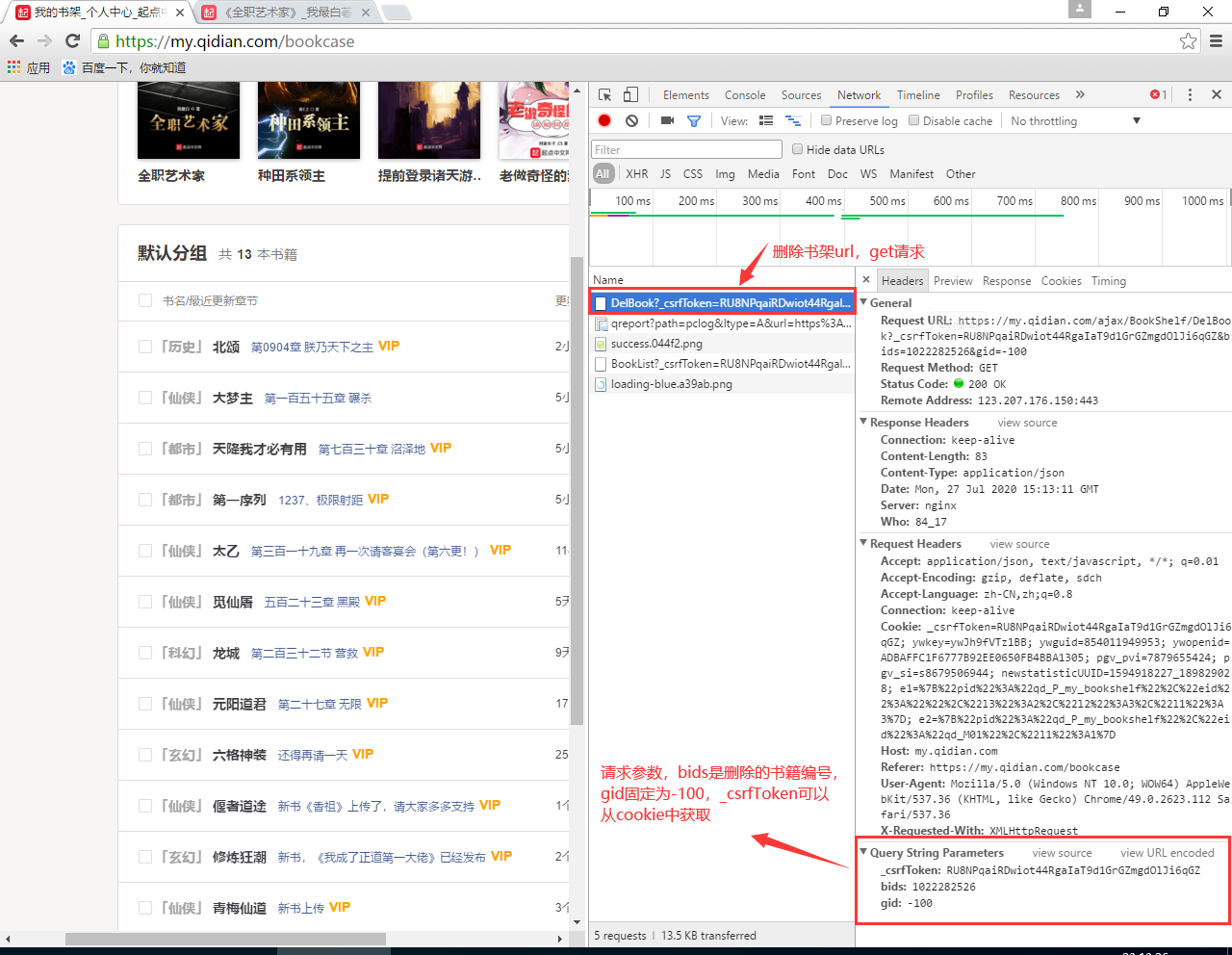
该请求一共有三个参数:
- _csrfToken:可以从 cookie 中获取;
- bids:书籍编号,可以从这一行的 html 元素中提取;
- gid:发现是固定的100;
于是我们在请求到书架上的书籍信息时,解析得到书籍编号,然后对应发送删除该书籍的请求,对应的代码如下:
from .get_cookie import get_cookies_from_chrome
from ..items import QidianSpiderItem
# 删除书籍信息 https://my.qidian.com/ajax/BookShelf/DelBook?_csrfToken=YJklLmhEFpEfuSmqZZGaK72D4sUVJty52gyKw0TJ&bids=1022282526&gid=-100
class BookCaseSpider(Spider):
name = "bookcase"
# 构造函数
def __init__(self):
self.cookie_dict = get_cookies_from_chrome(
"qidian.com",
["_csrfToken", "e1", "e2", "newstatisticUUID", "ywguid", "ywkey"]
)
def start_requests(self):
url = "https://my.qidian.com/bookcase"
# http请求时附加上cookie信息
yield Request(url=url, cookies=self.cookie_dict)
def parse(self, response):
item = QidianSpiderItem()
books = response.xpath('//table[@id="shelfTable"]/tbody/tr')
for book in books:
# ...
# 删除该书籍信息
query_data = {
'bids': book.xpath('td[6]/div[@class="ui-datalist"]/div[@class="ui-datalist-datalist"]/a[1]/@data-id').extract_first(),
'gid': '-100',
'_csrfToken': self.cookie_dict['_csrfToken']
}
url = "https://my.qidian.com/ajax/BookShelf/DelBook?{}".format(parse.urlencode(query_data))
print('对应删除url请求={}'.format(url))
yield Request(url=url, method='get', cookies=self.cookie_dict, callback=self.parse_delete_book)
def parse_delete_book(self, response):
"""
删除结果:{"code":0,"data":{"1022354901":{"code":0,"message":"操作成功"}},"msg":"成功"}
"""
data = response.text
print('删除响应:{}'.format(data))
if isinstance(data, str):
data = json.loads(data)
print('msg = {}'.format(data['msg']))
是不是非常简单?来看看最后运行的效果:
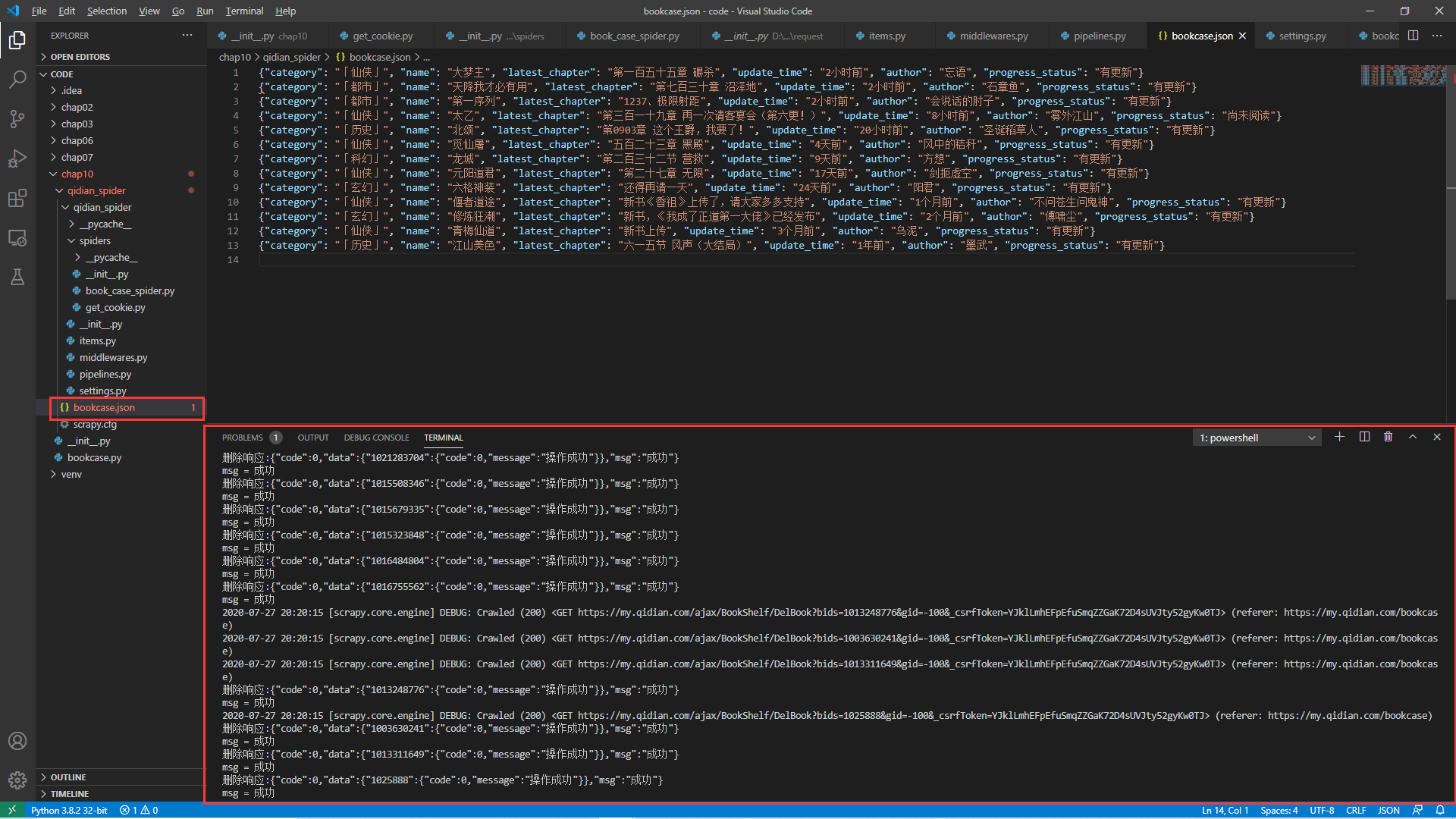
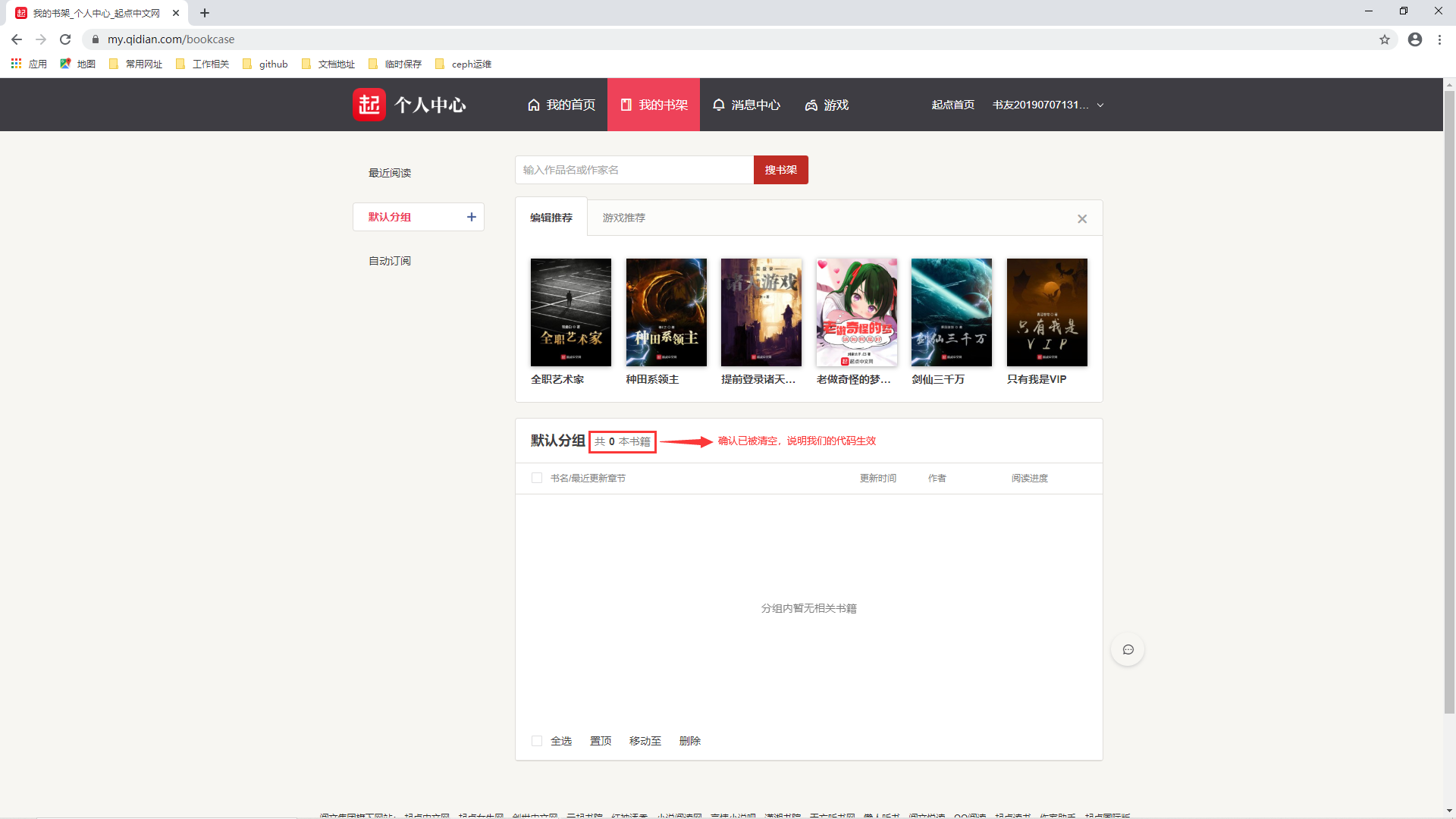
是不是很有意思?基于这样的操作,我们想想淘宝一键清除购物车功能,是不是也能这样实现?还有每次明星的恋情有变,连夜删除上千条微博,导致手指酸痛,我们是否能提供一键清除微博的功能,解决他们的痛点?这些事情是不是想想就很激动?还等什么,心动不如行动,这个就作为课后作业吧,希望你能独立完成淘宝的一键清除购物车代码。
3. 小结
本节中,我们基于 Scrapy 框架讲解了下如何简单地实现自动登录操作,避开滑动验证码的二次验证。然后,在登录的基础上实现删除用户的所有书架操作。

 2026 imooc.com All Rights Reserved |
2026 imooc.com All Rights Reserved |