如果选择器是 div.aaron input[name=ttt],div p,之前通过词法解析出来的的七类型:
TAG、>、TAG、CLASS、"空格"、"TAG"、ATTR
如下面的结构所示:
type: "TAG" value: "div" matches .... type: ">" value: " > " type: "TAG" value: "p" matches ....
除去关系选择器,其余的有语意的标签都对应这分析出matches。
tokenize最后一个属性选择器分支单元结构。
"[input[name=ttt]]" matches = [ 0: "type" 1: "=" 2: "ttt" ] type: "ATTR" value: [name=ttt]"
那么我们从右到左边开始匹配最终合集单元。
从左边开始很明显是属性选择器:
input[name=ttt]
但是这个东东原生的API是不认识的,所以我们只能再往前找input的合集:
type: "TAG" value: "input"
这种标签Expr.find能匹配到了,所以直接调用:
Expr.find["TAG"] = support.getElementsByTagName ?
function(tag, context) {
if (typeof context.getElementsByTagName !== strundefined) {
return context.getElementsByTagName(tag);
}
} :
但是getElementsByTagName方法返回的是一个合集。
这里引入了seed - 种子合集(搜索器搜到符合条件的标签),放入到这个初始集合seed中。这种我们找到了最终的一个合集,那么我们需要的就是根据剩余的条件筛选出真正的选择器就OK了,这里暂停了,不再往下匹配了,如果再用这样的方式往下匹配效率就慢了。
开始整理
重组一下选择器,剔掉已经在用于处理的tag标签,input,所以选择器变成了:
selector:"div > div.aaron [name=ttt]"
这里可以优化下,如果直接剔除后,为空了,就证明满足了匹配要求,直接返回结果了。
到这一步为止,我们能够使用的东东:
1、seed合集
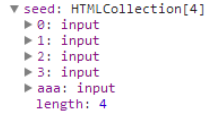
2、通过tokenize分析解析规则组成match合集,本来是7个规则快,因为匹配input,所以要对应的也要踢掉一个所以就是6个了。
3、选择器语句,对应的踢掉了input。
selector:"div > div.aaron [name=ttt]"
此时send目标合集有2个最终元素了,那么如何用最简单,最有效率的方式从2个条件中找到目标呢?
这个问题后面小节将给你们揭晓。
请验证,完成请求
由于请求次数过多,请先验证,完成再次请求
打开微信扫码自动绑定
绑定后可得到
使用 Ctrl+D 可将课程添加到书签
举报
