

-
 查看全部
查看全部 -
使用POST请求
查看全部 -
模拟真实浏览器
查看全部 -
urllib使用方法
查看全部 -
安装BeautifulSoup4
查看全部 -
form urllib import request res = request.urlopen(' print(res.read().decode("utf-8"))查看全部 -
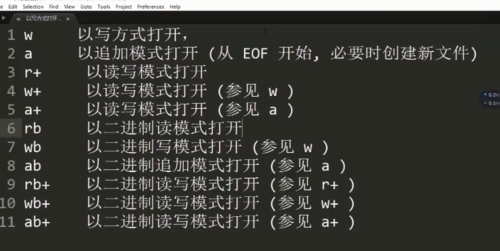 查看全部
查看全部 -
安装pdfminer3k 一般只安装了python3 安装使用语句 pip install pdfminer3k 若python同时安装了几个版本(python2.7 and python3.6) pip3 install pdfminer3k 或者 py -3 -m pip install pdfminer3k
查看全部 -
#!/usr/bin/env python # encoding: utf-8 import pymysql connection = pymysql.connect(host='localhost', user='root', password='', db='wiki', charset='utf8') try: with connection.cursor() as cursor: sql = "select `urlname`, `urlhref` from `urls` where `id` is not null" count = cursor.execute(sql) print(count) #result = cursor.fetchall() #print(result) result = cursor.fetchmany(size=5) print(result) finally: connection.close()
查看全部 -
#!/usr/bin/env python # encoding: utf-8 #引入开发包 from urllib.request import urlopen from bs4 import BeautifulSoup import re import pymysql resp = urlopen("https://en.wikipedia.org/wiki/Main_Page").read().decode("utf-8") soup = BeautifulSoup(resp, "html.parser") listUrls = soup.find_all("a", href=re.compile("^/wiki/")) #print(listUrls) connection = pymysql.connect(host='localhost', user='root', password='', db='wiki', charset='utf8') print(connection) try: with connection.cursor() as cursor: for url in listUrls: if not re.search("\.(jpg|jpeg)$", url['href']): sql = "insert into `urls`(`urlname`,`urlhref`)values(%s, %s)" #print(sql) #print(url.get_text()) cursor.execute(sql, (url.get_text(), "https://en.wikipedia.org" + url["href"])) connection.commit() finally: connection.close();查看全部 -
urllib
查看全部 -
python3 乱码解决
查看全部 -
mark
查看全部 -
读取在线PDF查看全部
-
获取维基百科词条查看全部






举报
0/150
提交
取消