

-
统计常规指标:
1.均值、中位数、最大值、最小值等
2.计数类(如统计某值出现多少)
3.缺失值和方差等(方差太小没有区分度,缺失值太多也一样)
4. 分位点、值得频数等(不同的分位点的值相同的情况下,需要关注一下!值得频数就是统计最经常出现的值是谁,有什么比例等)
查看全部 -
数据的读取
查看全部 -
数据 诊断
查看全部 -
依赖包的导入
查看全部 -
数据分析依赖包
查看全部 -
数据诊断的目的
查看全部 -
1. 数据诊断的目的:
1) 了解特征的分布,缺失和异常等情况。(了解了这些情况我们才能更好地做特征工程和数据预处理)
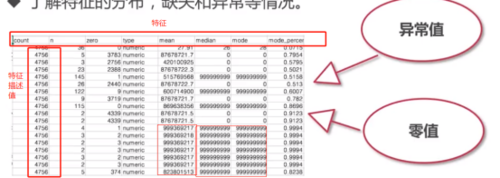
2)统计指标可直接用于数据预处理
数据预处理就是指比如说特征缺失值的填充,缺失值的填充是建模常用的手段。填充的目的有很多。在填充的时候大家一般会采用很多种办法。比如填一个0,-1,1这种常值进去,但是更多的人可能会填一些统计值,比如说中位数、众数这样的值进去。如果要用这种方法填数的话,一般需要对特征值重新计算一遍,如果每次都计算的话,这样会影响整个模型的效率。更好的办法:就是可以从前面预处理的过程和结果中把中位数和众数取到,直接填到缺失里面去,这样可以减少运行计算时间,因为我们只需要提取,不需要计算,这样的话会减少耗时。除了这个以外,我们也有很多的判断,比如数缺失值的比例,众数的比例,也是形容特征工程的一个环节。当我们整个建模的流程形成之后,这些数据诊断的结果也可以起到判断的作用。
 查看全部
查看全部 -
数据 诊断
查看全部 -
依赖包包括:Numpy,Pandas,Scipy
查看全部 -
了解特征分布,缺失和异常
统计指标可直接用于数据预处理
查看全部 -
清洗数据,是必要之必要的,准备步骤要做好
查看全部 -
为了更高效地学习,这次尝试从结果出发来学习 python,看不懂的部分,回头再查找入门课程。
依赖包-待安装
特殊值、描述值-待查概念
查看全部 -
1.缺失值不应该存在于EDA中。缺失值是通过分析得出来的。
2.数据导入-》数据分析-》工具
查看全部 -
1.# 2.Calculating Running time
import timeit
start = timeit.default_timer()
df_eda_summary = eda_analysis(missSet=[np.nan, 9999999999, -999999], df=df.iloc[:, 0:3])
print('EDA Running Time: {0:.2f} seconds'.format(timeit.default_timer() - start))
上面是时间的测试示例,我们去测试每一块所用时间,由此可以判断我们的优化重点,经过测试可知,众数部分的时间较长,所以我们后期可对这一部分进行优化,优化的方法有:1)注释掉没用的代码 2)使用更好的方法去替代原有方法。
查看全部 -
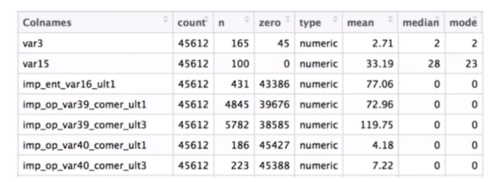
1.整合核心代码:
# 12.Combine All Information
df_eda_summary = pd.concat(
[count_un, count_zero, df_mean, df_median, df_mode,
df_mode_count, df_mode_perct, df_min, df_max, df_fre,
df_miss], axis=1
)
# 左边是特征,上边是有多少统计描述,就拼多少
查看全部




举报